Awesome Prompting on Vision Language Model
1.0.0
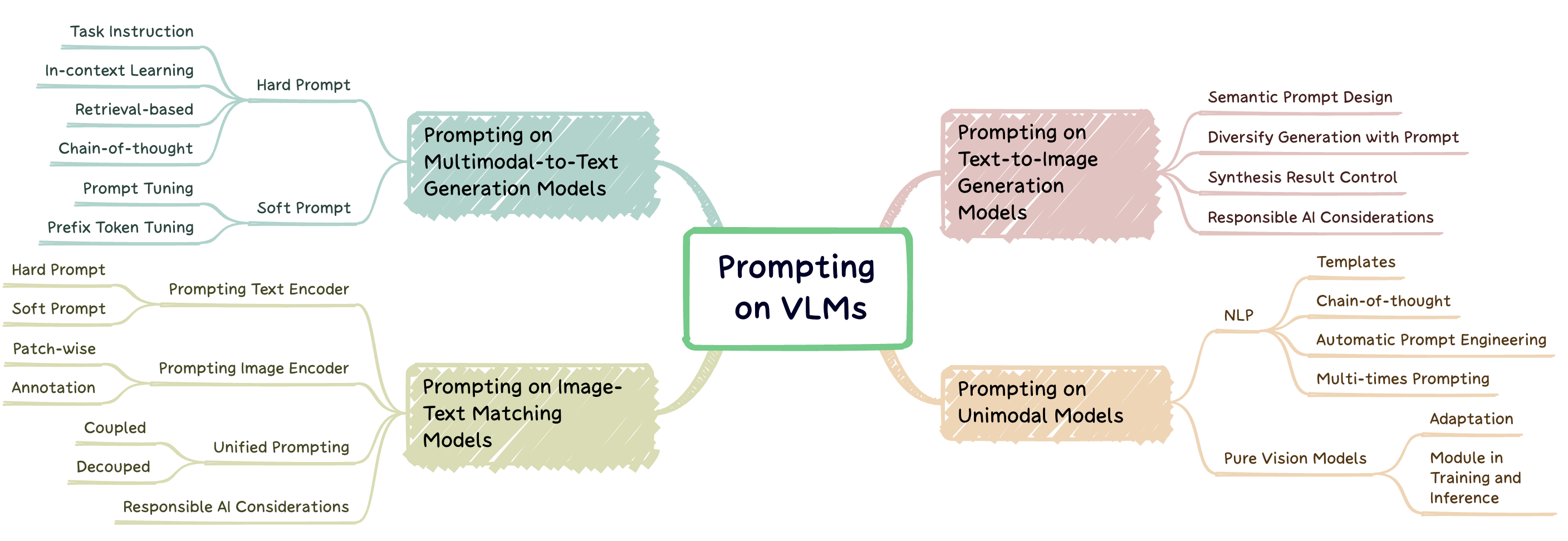
A engenharia rápida é uma técnica que envolve aumentar um modelo pré-treinado com dicas específicas de tarefas, conhecidas como prompts, para adaptar o modelo a novas tarefas. Esse repositório visa fornecer uma pesquisa abrangente sobre pesquisas de ponta em engenharia imediata em três tipos de modelos de linguagem de visão (VLMs): modelos de geração multimodal para texto ( por exemplo , flamingo), modelos de correspondência de imagem-texto ( por exemplo , clipe) e modelos de geração de imagem ( por exemplo , difusão estável) (Fig. 1).
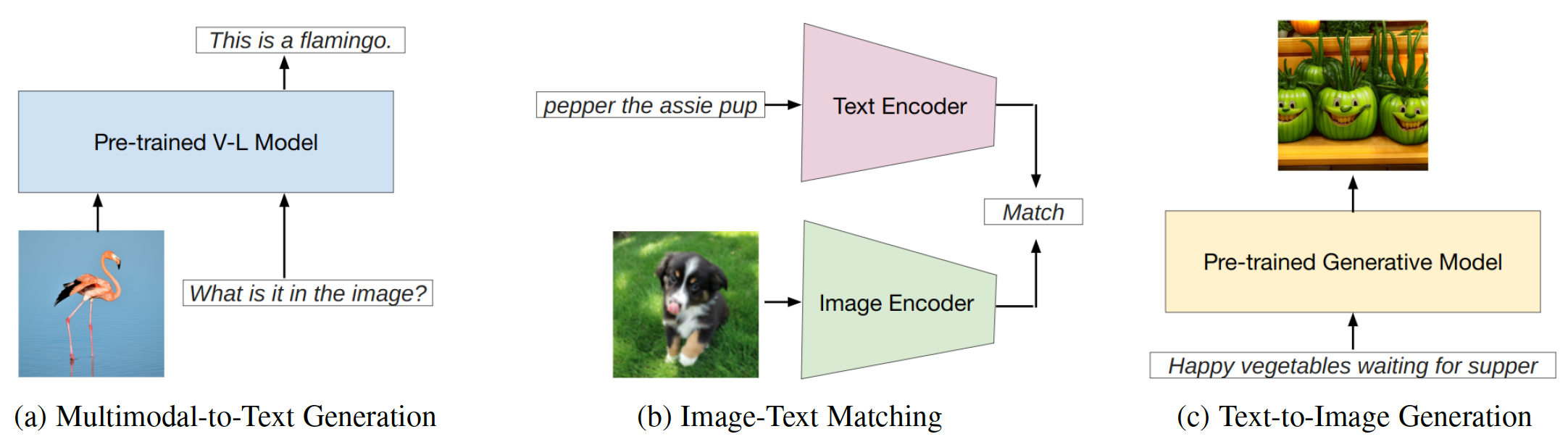
Fig. 1: Este trabalho se concentra em três tipos principais de modelos de linguagem de visão.
Este repositório lista os documentos relevantes resumidos em nossa pesquisa:
Uma pesquisa sistemática de engenharia imediata nos modelos de fundação em linguagem da visão. Jindong Gu, Zhen Han, Shuo Chen, Ahmad Beirami, Bailan He, Gengyuan Zhang, Ruotong Liao, Yao Qin, Volker Tresp, Philip Torr . Pré -impressão 2023. [PDF]
Se você achar útil nosso artigo e repositório para sua pesquisa, cite o seguinte artigo:
@article{gu2023survey,
title={A Systematic Survey of Prompt Engineering on Vision-Language Foundation Models},
author={Gu, Jindong and Han, Zhen and Chen, Shuo, and Beirami, Ahmad and He, Bailan and Zhang, Gengyuan and Liao, Ruotong and Qin, Yao and Tresp, Volker and Torr, Philip}
journal={arXiv preprint arXiv:2307.12980},
year={2023}
}Modelo de solicitação de geração multimodal para texto
Modelo de solicitação na correspondência de texto de imagem
Modelo de solicitação de geração de texto para imagem
Existem dois tipos principais de abordagens do módulo de fusão com base na integração de modalidades visuais e textuais: codificador-decodificador como um módulo de fusão multimodal e apenas decodificador como um módulo de fusão multimodal . Os métodos de solicitação podem ser divididos em duas categorias principais (Fig. 2), com base na legibilidade dos modelos: prompt e prompt suave e suave . Prompt difícil abrange quatro subcategorias: instrução de tarefas, aprendizado no contexto, promoção baseada em recuperação e solicitação de cadeia de pensamentos . Os avisos suaves são classificados em duas estratégias: ajuste imediato e ajuste de token prefixo , com base em adicionar novos tokens à arquitetura do modelo ou simplesmente anexá -los à entrada. Este estudo concentra -se principalmente em métodos imediatos que evitam alterar o modelo básico.
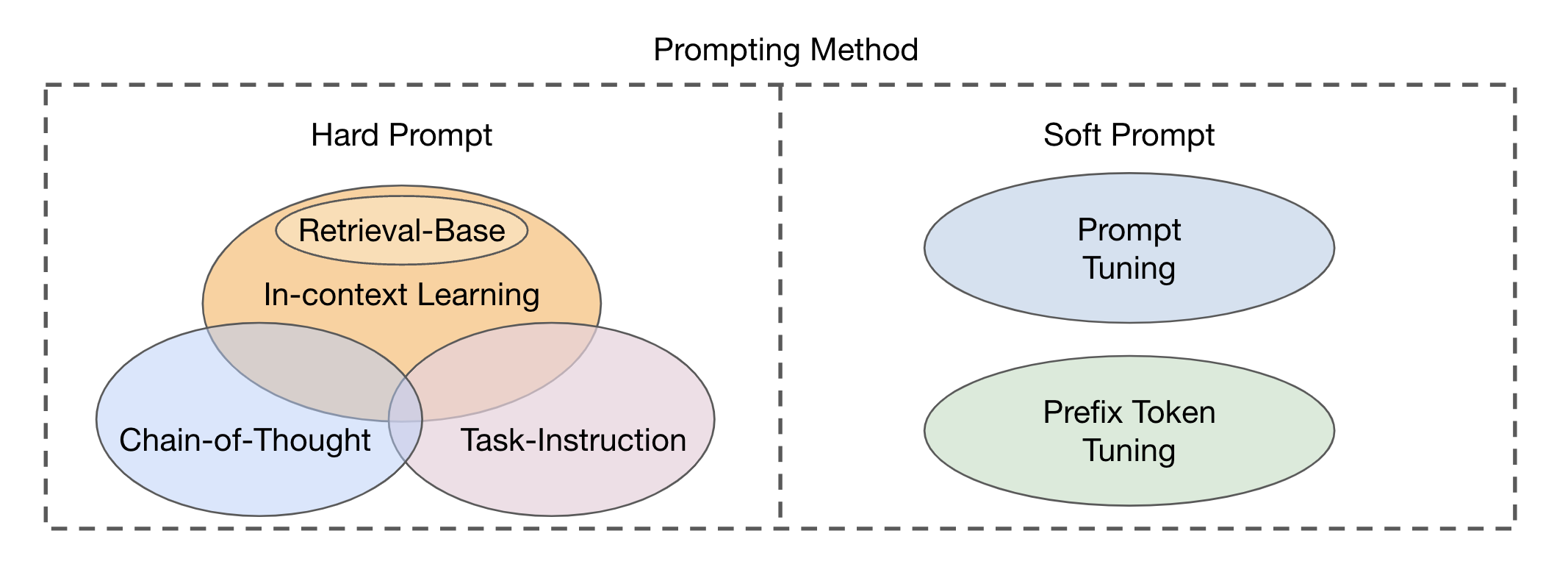
Fig. 2: Classificação dos métodos de solicitação.
| Título | Local | Ano | Código, se disponível | Comentário |
|---|---|---|---|---|
| Unificar tarefas de visão e linguagem via geração de texto | ICML | 2021 | Github | Fusão do codificador-decodificador; Prefixos de texto como rápido |
| Simvlm: modelo simples de linguagem visual pré -treinamento com supervisão fraca | ICLR | 2022 | Github | Fusão do codificador-decodificador; Prefixos de texto como rápido |
| OFA: unificar arquiteturas, tarefas e modalidades através de uma simples estrutura de aprendizado de sequência para sequência | ICML | 2022 | Github | Fusão do codificador-decodificador; Prefixos de texto como rápido |
| Pali: Um modelo de imagem de linguagem multilíngue em escala em conjunto | ICLR | 2023 | ---- | Fusão do codificador-decodificador; Prompt de instrução |
| Aprendizagem multimodal de poucos tiros com modelos de idiomas congelados | Neurips | 2021 | Página | Fusão somente para decodificador; Ajuste de prefixo condicional de imagem |
| Flamingo: um modelo de linguagem visual para aprendizado de poucos tiros | Neurips | 2022 | Github | Fusão somente para decodificador; Solicitações de texto; |
| Magma-Aumentação multimodal de modelos generativos por meio de Finetuning baseado em adaptador | Emnlp | 2022 | Github | Fusão somente para decodificador; Ajuste de prefixo condicional de imagem |
| BLIP-2: PRÉ-TREINAM | ICML | 2023 | Github | Fusão somente para decodificador; Ajuste de prefixo condicional de imagem |
| Modelos de idiomas são aprendizes multitarefa sem supervisão | Blog open | 2019 | Github | Prompt de instrução de tarefa |
| O Teste de Turquitagem: Os modelos de idiomas podem entender as instruções? | arxiv | 2020 | ---- | Prompt de instrução de tarefa |
| Modelos de idiomas são poucos alunos | Neurips | 2020 | ---- | Aprendizagem no contexto |
| Aprendendo a recuperar os avisos para o aprendizado no contexto | Naacl-hlt | 2022 | Github | Solicitação baseada em recuperação |
| Demonstração unificada Retriever para aprendizado no contexto | ACL | 2023 | Github | Solicitação baseada em recuperação |
| Exemplos de composição para aprendizado no contexto | ICML | 2023 | Github | Solicitação baseada em recuperação |
| Cadeia de pensamento provocando provas o raciocínio em grandes modelos de idiomas | Neurips | 2022 | ---- | Cadeia de pensamento solicitando |
| Cadeia de pensamento automática solicitando em grandes modelos de linguagem | ICLR | 2023 | Github | Cadeia de pensamento solicitando |
| O poder de escala para ajuste rápido com eficiência de parâmetro | Emnlp | 2021 | ---- | Ajuste imediato |
| Aprendendo a perguntar: Consultando LMs com misturas de avisos suaves | Naacl-hlt | 2021 | Github | Ajuste imediato |
| Tuneamento de prefixos: otimizando instruções contínuas para geração | ACL | 2021 | Github | Ajuste prefixo |
| Ajuste imediato para modelos generativos de pré -treinamento multimodais | ACL | 2023 | Github | Ajuste rápido em Ofa |
| A linguagem não é tudo o que você precisa: alinhar a percepção com modelos de linguagem | Neurips | 2023 | Github | Promotos de instrução textual |
| Robustez de benchmarking dos métodos de adaptação em modelos de linguagem de visão pré-treinados | Neurips | 2024 | Página | Robustez de ajuste rápido no VLMS |
| Para instruções robustas em modelos de linguagem de visão | NextGenaisafety@ICLR | 2024 | ---- | Robustez de ajuste rápido no VLMS |
| InstructBlip: Rumo a modelos de linguagem de visão geral com ajuste de instrução | Neurips | 2023 | Github | Ajuste imediato |
| Ajuste da instrução visual | Neurips | 2023 | Github | |
| QWEN-VL: Um modelo versátil de linguagem de visão para compreensão, localização, leitura de texto e além | arxiv | 2023 | Github | Ajuste imediato |
| Shikra: Unbleing Magic Multimodal LLM de diálogo referencial Magic Magic | arxiv | 2023 | Github | |
| Minigpt-4: Aprimorando o entendimento da linguagem da visão com modelos avançados de linguagem grande | ICLR | 2023 | Github | Ajuste imediato |
Dependendo do alvo da solicitação, os métodos existentes podem ser classificados em três categorias: solicitando o codificador de texto , solicitando o codificador visual ou solicitando em conjunto ambas as ramificações, como mostrado na Fig. 2. Essas abordagens visam melhorar a flexibilidade e o desempenho específico da tarefa dos VLMs.
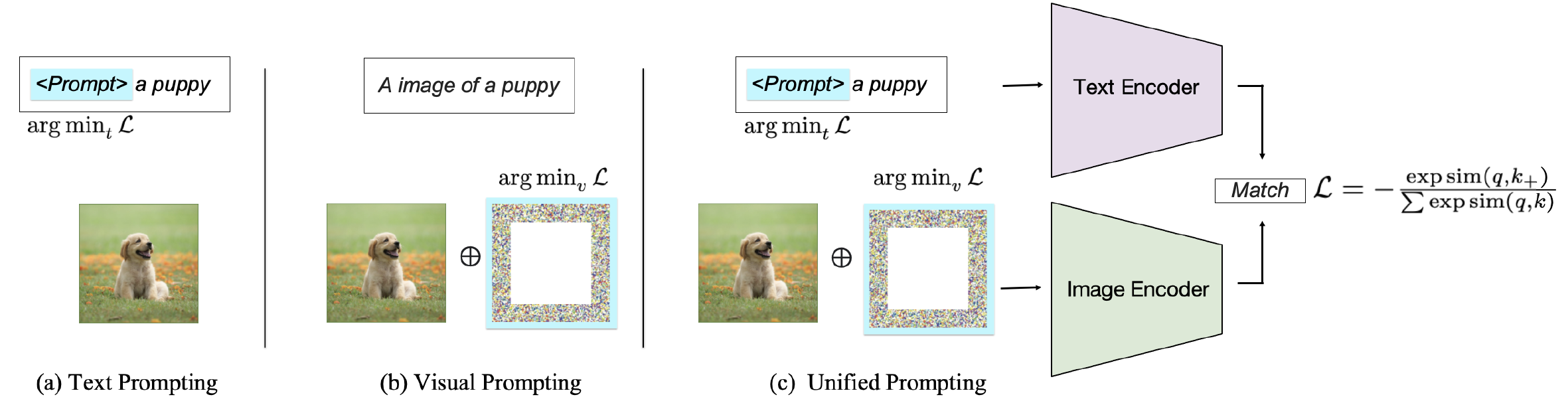
Fig. 2: Classificação dos métodos de solicitação em VLMs correspondentes ao texto de imagem.
| Título | Local | Ano | Código, se disponível | Comentário |
|---|---|---|---|---|
| Aprendendo modelos visuais transferíveis da supervisão da linguagem natural | ICML | 2021 | Github | Proot de texto difícil; Prompt para classificação de imagem |
| Mergulhando na abertura do clipe | ACL | 2023 | Github | Promotos de texto difícil para entender |
| Teste de tempo de teste Tuning para generalização de tiro zero em modelos de linguagem de visão | Neurips | 2022 | Github | Promotos de texto suave |
| Aprendendo a solicitar modelos de linguagem de visão | IJCV | 2022 | Github | Promotos de texto suave |
| Solicitando modelos de linguagem visual para uma compreensão de vídeo eficiente | ECCV | 2022 | Github | Promotos de texto suave |
| Ajuste rápido da linguagem de visão multitarefa | WACV | 2024 | Github | Promotos de texto suave |
| Aprendizado rápido condicional para modelos de linguagem de visão | Cvpr | 2022 | Github | Promotos de texto suave |
| Ajuste rápido visual | ECCV | 2022 | Github | Pronhos visuais em patches |
| Explorando instruções visuais para adaptar modelos em larga escala | arxiv | 2022 | Github | Pronhos visuais em patches |
| Ajuste rápido da linguagem de visão multitarefa | WACV | 2024 | Github | Pronhos visuais em patches |
| Liberando o poder do Visual Octing no nível do pixel | Tmlr | 2024 | Github | Pronhos visuais em patches |
| Meta visual consciente da diversidade solicitar | Cvpr | 2023 | Github | Pronhos visuais em patches |
| CPT: ajuste rápido colorido para modelos de linguagem de visão pré-treinados | Ai aberto | 2024 | Github | Avisos de anotação visual |
| O que o Clip sabe sobre um círculo vermelho? Engenharia de prompt visual para VLMs | ICCV | 2023 | ---- | Avisos de anotação visual |
| Solicitação visual por meio de imagens de imagem | Neurips | 2022 | Github | Avisos de anotação visual |
| Visão unificada e aprendizado rápido de idiomas | arxiv | 2023 | Github | Solicitação unificada acoplada |
| Ajuste rápido da linguagem de visão multitarefa | WACV | 2024 | Github | Promotamento unificado desacoplado |
| Maple: Aprendizado rápido multimodal | Cvpr | 2023 | Github | Promotamento unificado desacoplado |
| Compreendendo a robustez adversária zero-tiro para modelos em larga escala | ICLR | 2023 | Código | Robustez adversária de prompt |
| Solicitação visual para robustez adversária | ICASSP | 2023 | Github | Robustez adversária de prompt |
| Alinhe antes do fusível: Visão e representação da linguagem Aprendendo com destilação de momento | Neurips | 2021 | Github | Modelo de correspondência de texto de imagem |
| Aprendizado imediato não supervisionado para modelos de linguagem de visão | arxiv | 2022 | Github | Prompts aprendidas não permissão |
| Teste de tempo de teste Tuning para generalização de tiro zero em modelos de linguagem de visão | Neurips | 2022 | Github | Solicitação aprendida |
| PROMPENTO PRÉ-TREINAM | Neurips | 2023 | Github | Rápido pré-treinamento |
| Aprendizado imediato guiado pela consistência para modelos de linguagem de visão | ICLR | 2024 | ---- | Promotamento unificado desacoplado |
| Melhorando a adaptabilidade e generalização do aprendizado de transferência eficiente para modelos de linguagem de visão | ACL ARR | 2024 | ---- | Solicitação aprendida |
| Título | Local | Ano | Código, se disponível | Comentário |
|---|---|---|---|---|
| LMPT: sintonização imediata com perda de incorporação específica de classe para reconhecimento visual de várias marcas de cauda longa | ALVR | 2024 | Github | Promotos para classificação de imagem com vários rótulos de cauda longa |
| Teste de tempo de teste Tuning para generalização de tiro zero em modelos de linguagem de visão | Neurips | 2022 | Github | Prompt de aprendizado; Solicitações para classificação de imagem |
| LPT: Tuning de longa cauda de cauda para classificação de imagem | ICLR | 2023 | Github | Solicita a classificação de imagem de cauda longa |
| Textos como imagens em ajuste rápido para reconhecimento de imagem com vários rótulos | Cvpr | 2023 | Github | Promotos para classificação e detecção de imagem com vários rótulos |
| DualCoop: Adaptação rápida ao reconhecimento de vários rótulos com anotações limitadas | Neurips | 2022 | Github | Promotos para classificação e reconhecimento de imagem com vários rótulos |
| Ajuste Visual Pump para classificação de texto de pouca tiro | ICCL | 2022 | ---- | Promotos visuais para classificação de texto |
| Detecção de objetos abertos-vocabulários via visão e destilação do conhecimento da linguagem | ICLR | 2021 | Github | Solicita a detecção de objetos |
| Aprendendo a solicitar a detecção de objetos abertos-vocabulares com modelo de linguagem de visão | Cvpr | 2022 | Github | Solicita a detecção de objetos |
| PromptDet: para detecção de vocabulário aberto usando imagens não curtas | ECCV | 2022 | Github | Solicita a detecção de objetos |
| Otimizando instruções contínuas para a detecção de relacionamento visual por afixação | IEEE Acesso | 2022 | ---- | Promotos suaves para detecção de relação visual |
| Rumo à geração de gráficos de cenas abertas de vocabulário com finsetuning rápido | ECCV | 2022 | ---- | Promotos suaves para detecção de relação visual |
| Ajuste rápido composicional com pistas de movimento para detecção de relação de vídeo em vídeo aberta | ICLR | 2023 | Github | Solicitações de relação para o vídeo de detecção de relação de video-vocabulário |
| Denseclip: previsão densa guiada por idiomas com o contexto que levanta o contexto | Cvpr | 2022 | Github | Promotos de texto condicionado a classe para segmentação semântica |
| Segmentar qualquer coisa | ICCV | 2023 | Github | Consultas prontáveis para segmentação semântica |
| Adaptação de domínio por meio de aprendizado rápido | IEEE | 2023 | Github | Promotos textuais específicos de domínio para adaptação de domínio |
| Tuning visual Prompt para adaptação de domínio no tempo de teste | arxiv | 2022 | ---- | Solicita a adaptação de domínio |
| Aprendendo a solicitar a aprendizagem contínua | Cvpr | 2022 | Github | Solicita a aprendizagem contínua |
| PROMPRIMENTO DO DUAL: Promotamento complementar para aprendizado contínuo sem ensaio | ECCV | 2022 | Github | Solicita a aprendizagem contínua |
| Impressionante transformador de visão para generalização do domínio | arxiv | 2022 | Github | Solicita a generalização do domínio |
| Compreendendo a robustez adversária zero-tiro para modelos em larga escala | Lclr | 2022 | Github | Visual Pump Tuning sob ataque adversário |
| Solicitação visual para robustez adversária | ICASSP | 2023 | Github | Visual solicitando para melhorar a robustez adversária |
| Explorando a vulnerabilidade universal do paradigma de aprendizado rápido baseado | Naacl | 2022 | Github | Vulnerabilidade visual de promoção |
| Envenenamento e backdooring Learning | ICLR | 2022 | ---- | Ataques de backdoor e envenenamento em clipes |
| Badencoder: ataques de backdoor a codificadores pré-treinados em aprendizado auto-supervisionado | IEEE | 2022 | Github | Ataque de backdoor ao clipe |
| CleanClip: Mitigando ataques de envenenamento de dados em aprendizado contrastivo multimodal | Workshop ICLR | 2023 | ---- | Ataques de backdoor de defesa no clipe |
| Modelos de linguagem de visão de debiasing por meio de avisos tendenciosos | arxiv | 2023 | Github | Solicita a aliviar o viés |
| Título | Local | Ano | Código, se disponível | Comentário |
|---|---|---|---|---|
| Modelos de difusão batem Gans na síntese de imagem | Neurips | 2021 | Github | Modelos de difusão na geração de imagens |
| Modelos de difusão batem Gans na síntese de imagem | Neurips | 2021 | Github | Modelos de difusão na geração de imagens |
| Modelos probabilísticos de difusão denoising | Neurips | 2020 | Github | Modelos de difusão na geração de imagens |
| SU-X: transferência apenas de nome sem treinamento de modelos de linguagem de visão | ICCV | 2023 | Github | Modelos de difusão na geração de imagens |
| Investigando engenharia imediata em modelos de difusão | Workshop Neurips | 2022 | ---- | Design de imediato semântico |
| Difumask: sintetizando imagens com anotações em nível de pixel para segmentação semântica usando modelos de difusão | IEEE/CVF | 2023 | Github | Diversificar a geração com prompt; Solicitações para geração de dados sintéticos |
| Os dados sintéticos de modelos generativos estão prontos para o reconhecimento de imagem? | ICLR | 2023 | Github | Diversificar a geração com rápido |
| Uma imagem vale uma palavra: personalizar a geração de texto para imagem usando inversão textual | ICLR | 2023 | Github | Controle complexo dos resultados da síntese por meio de avisos |
| Dreambooth: Modelos de difusão de texto de ajuste fino para geração orientada por assuntos | Cvpr | 2023 | Github | Controle complexo dos resultados da síntese por meio de avisos |
| Personalização de múltiplos conceito de difusão de texto a imagem | Cvpr | 2023 | Github | Controle complexo dos resultados da síntese por meio de avisos |
| Edição de imagem pronta para promoção com controle de atenção cruzada | ICLR | 2023 | ---- | Controle complexo dos resultados da síntese por meio de avisos |
| Orientação de difusão estruturada sem treinamento para síntese de texto a imagem composicional | ICLR | 2023 | Github | Geração de texto para imagem controlável |
| Guidância de difusão para geração de imagem controlável | Neurips | 2023 | Página | Geração de texto para imagem controlável |
| Imagic: edição de imagem real baseada em texto com modelos de difusão | Cvpr | 2023 | Github | Geração de texto para imagem controlável |
| Adicionando controle condicional aos modelos de difusão de texto a imagem | IEEE/CVF | 2023 | Github | Geração de texto para imagem controlável |
| Edição de imagem pronta para promoção com controle de atenção cruzada | ICLR | 2023 | Github | Controle complexo dos resultados da síntese por meio de avisos |
| ImaginaryNet: Aprendendo detectores de objetos sem imagens e anotações reais | ICLR | 2023 | Github | Solicitações para geração de dados sintéticos |
| Os dados sintéticos de modelos generativos estão prontos para o reconhecimento de imagem? | ICLR | 2023 | Github | Solicitações para geração de dados sintéticos |
| Make-a-Video: geração de texto para video sem dados de texto-vídeo | ICLR | 2023 | Página | Solicita a geração de texto para vídeo |
| Imagen Video: Geração de vídeo de alta definição com modelos de difusão | arxiv | 2022 | Página | Solicita a geração de texto para vídeo |
| FateZero: Fusão de atenções para edição de vídeo baseada em texto com tiro zero | ICCV | 2023 | Github | Solicita a geração de texto para vídeo |
| Tune-a-Video: ajuste de um tiro de modelos de difusão de imagem para geração de texto para vídeo | ICCV | 2023 | Github | Solicita a geração de texto para vídeo |
| DIFFRF: Difusão de campo de radiação 3D guiada por renderização | Cvpr | 2023 | Página | Solicita a geração de texto para 3D |
| Dreamfusion: Text-to-3D usando difusão 2D | ICLR Notável 5% no topo | 2023 | Página | Solicita a geração de texto para 3D |
| Dream3d: síntese de texto para 3D com tiro zero usando modelos de difusão de forma 3D em forma de 3D e texto para a imagem | Cvpr | 2023 | Página | Solicita a geração de texto para 3D |
| MotionDiffuse: geração de movimento humano orientado por texto com modelo de difusão | IEEE | 2024 | Página | Solicita a geração de texto para movimento |
| Chama: síntese de movimento e edição de movimento baseado em forma livre | Aaai | 2023 | Github | Solicita a geração de texto para movimento |
| MDM: Modelo de difusão de movimento humano | ICLR | 2023 | Github | Solicita a geração de texto para movimento |
| Geração zero de livro de histórias coerentes da história de texto simples usando modelos de difusão | arxiv | 2023 | ---- | Solicita tarefas complexas |
| Planejamento processual multimodal por meio de imagens de imagem dupla | ICLR | 2024 | Github | Solicita tarefas complexas |
| Roubo de ataques de roubo contra modelos de geração de texto para texto | Simpósio de Segurança Usenix | 2023 | ---- | Solicita a IA responsável |
| Ataques de inferência de associação contra modelos de geração de texto para imagem | ICLR | 2023 | ---- | Ataques de associação contra modelos de texto para imagem |
| Os modelos de difusão são vulneráveis a ataques de inferência de membros? | ICML | 2023 | Github | Ataques de associação contra modelos de texto para imagem |
| Uma extração reproduzível de imagens de treinamento de modelos de difusão | arxiv | 2023 | Github | Ataques de associação contra modelos de texto para imagem |
| Difusão justa: Instruindo modelos de geração de texto para imagens sobre justiça | arxiv | 2023 | Github | Solicita os modelos de texto para imagem, considerando a justiça |
| Vieses sociais através das lentes de geração de texto para imagem | AAAI/ACM | 2023 | ---- | Solicita os modelos de texto para imagem, considerando vieses |
| T2IAT: Medição de valência e vieses estereotipados na geração de texto para imagem | ACL | 2023 | ---- | Solicita os modelos de texto para imagem, considerando vieses |
| Viés estável: analisando representações sociais em modelos de difusão | Neurips | 2023 | ---- | Solicita os modelos de texto para imagem, considerando vieses |
| Um estudo piloto de ataque adversário livre de consulta contra difusão estável | Cvpr | 2023 | ---- | Robustez adversária de modelos de texto a imagem |
| Modelos de difusão para ataque adversário imperceptível e transferível | ICLR | 2024 | Github | Robustez adversária de modelos de texto a imagem |
| Modelos de difusão para purificação adversária | ICML | 2022 | Github | Robustez adversária de modelos de texto a imagem |
| Rickrolling the Artist: Injetando backdoors em codificadores de texto para síntese de texto para imagem | ICCV | 2023 | ---- | Ataque de backdoor em modelos de texto para imagem |
| Modelos de difusão de texto para imagem podem ser facilmente encostos através de envenenamento por dados multimodais | ACM MM | 2023 | ---- | Ataque de backdoor em modelos de texto para imagem |
| Personalização como um atalho para um ataque de backdoor de poucos backdoor contra modelos de difusão de texto a imagem | Aaai | 2024 | ---- | Ataque de backdoor em modelos de texto para imagem |
Entre em contato conosco ([email protected], [email protected]) se


