nnv
1.0.0

NNV(no-Named.v)是一個數據庫,旨在從頭到生產實現。 NNV可以部署在邊緣環境中,並用於小規模生產設置。通過下面描述的創新建築方法,它也可以在大規模生產環境中可靠地使用。
有關完整的更新歷史記錄,請參閱更新歷史記錄。
我們計劃支持CFLAT,這可以通過更複雜的操作來促進各種服務,從而實現多向量搜索。 CFLAT只是我創造的名字。請注意!
由於正在進行的發展,績效可能會暫時降低。謝謝您的耐心等待!
Windows & Linux
git clone https://github.com/sjy-dv/nnv
cd nnv
# start edge
go run cmd/root/main.go -mode=edge
# start core
go run cmd/root/main.go -mode=root
MacOS
** The CPU acceleration (SSE, AVX2, AVX-512) code has caused an error where it does not function on Mac, and it is not a priority to address at this time. **
git clone https://github.com/sjy-dv/nnv
cd nnv
source .env
deploy
make edge-docker特徵
建築學
BugFix
在計劃這個項目時,我考慮了很多。
在設置群集環境時,大多數開發人員自然會像以前那樣選擇木筏算法。原因是這是成功項目使用的一種經過驗證的方法。
但是,我開始懷疑:這不是有點複雜嗎?筏提高了讀取的可用性,但降低了寫入可用性。那麼,如果從長遠來看,多寫的話,我該如何解決?
鑑於矢量數據庫的性質,我認為大多數服務都是圍繞批處理作業而不是實時寫作構建的。但這是否意味著我可以跳過解決這個問題?我不這麼認為。但是,使用八卦之類的東西在筏上建立多領導者設置感到非常複雜和困難。 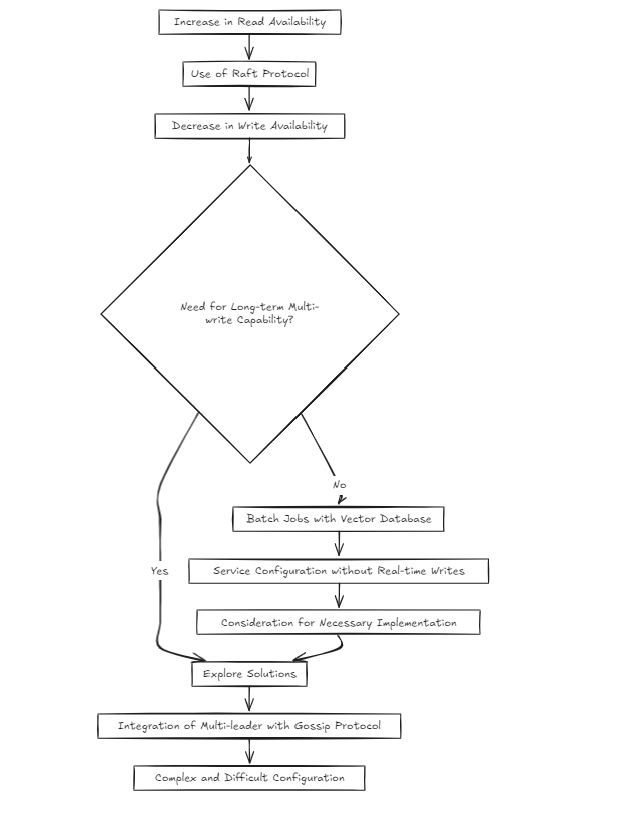
因此,截至今天(2024-10-20),我正在考慮兩種建築方法。
該體系結構分為兩種方法。
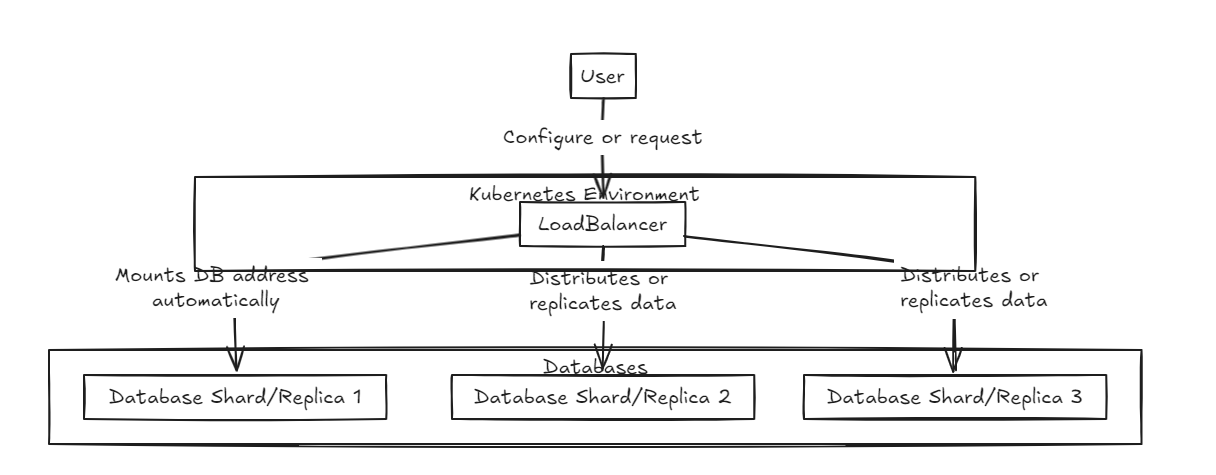
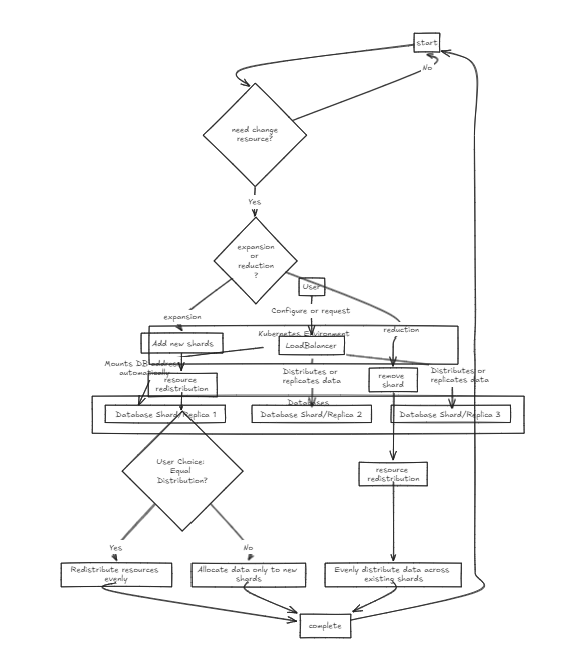
首先,將負載平衡器放在前面,支持數據的分片和集成。內部數據庫存在於純狀態。
 |  |
|---|---|
| 複製磅 | 碎片 |
複製負載均衡器等待所有數據庫在投入或回滾之前成功完成寫入,而碎片負載平衡器在整個碎片數據庫中均勻分配負載,以確保類似的存儲能力。
關鍵區別在於,複製可以減慢寫入操作,但與碎片負載平衡器相比,在長期到長期中提供更快的讀取性能。另一方面,碎片方法提供更快的寫作速度,因為它僅投入特定的碎片,但是閱讀需要從所有碎片中收集數據,最初速度較慢,但隨著數據集增長的增長可能比複製更快。
因此,為了管理大量數據,建議使用碎片平衡器。但是,這兩個體系結構的重點是它們在設置和管理方面的簡單性,使它們像典型的後端服務器一樣易於處理。 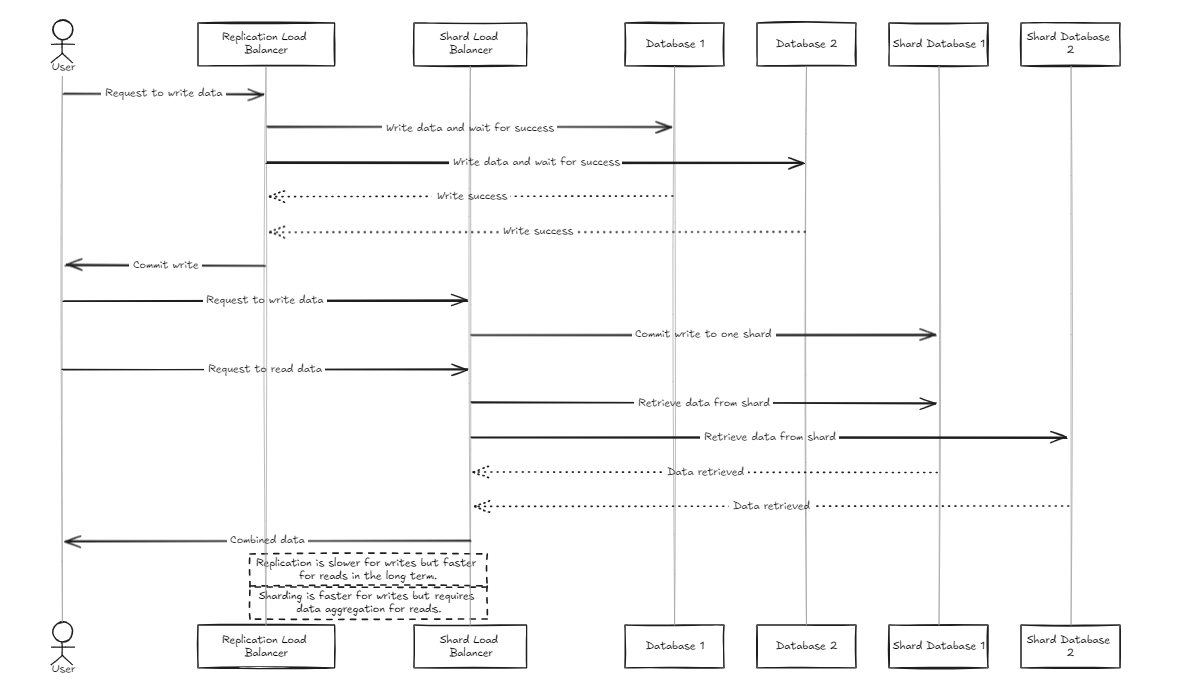
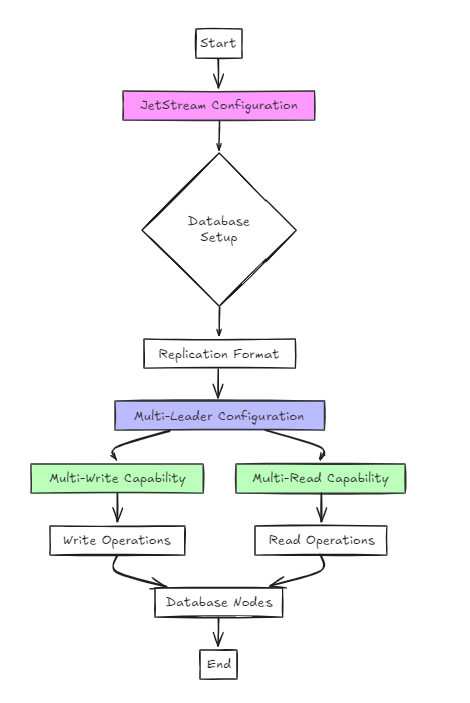
第二種方法利用噴頭進行配置。
儘管從用戶的角度來看,這在架構上比以前的方法更簡單,但設置與RAFT沒有顯著差異。
但是,關鍵區別在於,與筏子不同,它支持多寫的和多讀的配置,而不是單寫的和多讀。
在這種方法中,數據庫以復制格式配置,並且使用Jetstream用於啟用多領導配置。
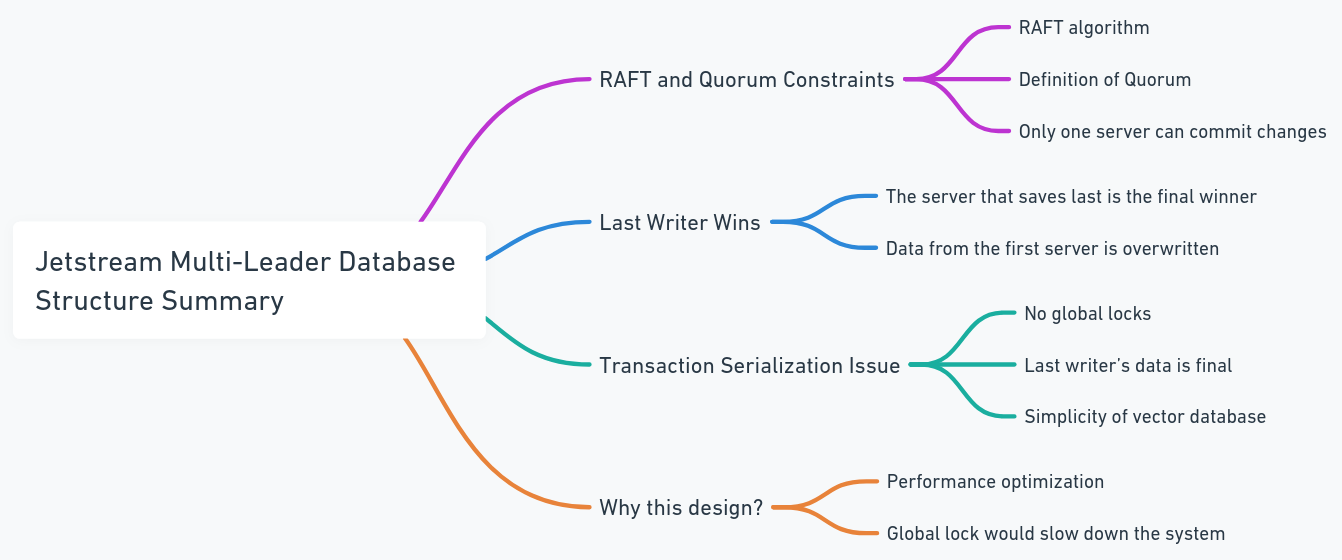
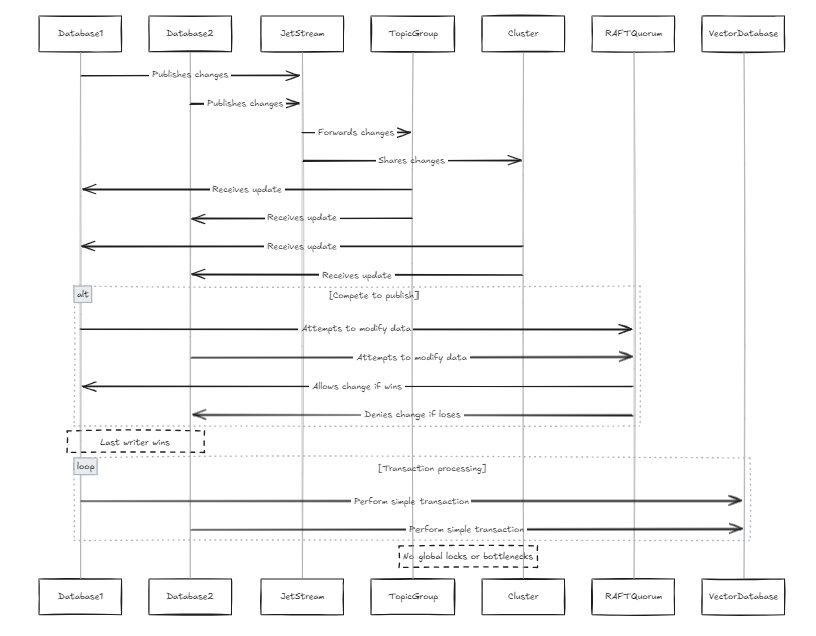 每個數據庫都包含其自己的射擊,這些噴頭加入了相同的主題和群集。在這種情況下,每當所有節點都嘗試發布對行更改時,它們都會通過相同的噴頭。如果兩個節點試圖並行修改相同的數據,他們將競爭發布其更改。雖然有可能防止變化被傳播,但這可能導致數據丟失。根據Jetstream中的Raft Quorum約束,只有一個作者可以發布更改。因此,我們設計了該系統以允許最後一位作家獲勝。對於向量數據庫而言,這不是問題,因為與傳統數據庫相比,數據結構更簡單(這並不意味著系統本身很簡單,而是更少的複雜交易和過程,例如交易序列化)。這也避免了全球鎖和性能瓶頸。
每個數據庫都包含其自己的射擊,這些噴頭加入了相同的主題和群集。在這種情況下,每當所有節點都嘗試發布對行更改時,它們都會通過相同的噴頭。如果兩個節點試圖並行修改相同的數據,他們將競爭發布其更改。雖然有可能防止變化被傳播,但這可能導致數據丟失。根據Jetstream中的Raft Quorum約束,只有一個作者可以發布更改。因此,我們設計了該系統以允許最後一位作家獲勝。對於向量數據庫而言,這不是問題,因為與傳統數據庫相比,數據結構更簡單(這並不意味著系統本身很簡單,而是更少的複雜交易和過程,例如交易序列化)。這也避免了全球鎖和性能瓶頸。
查看舊建築
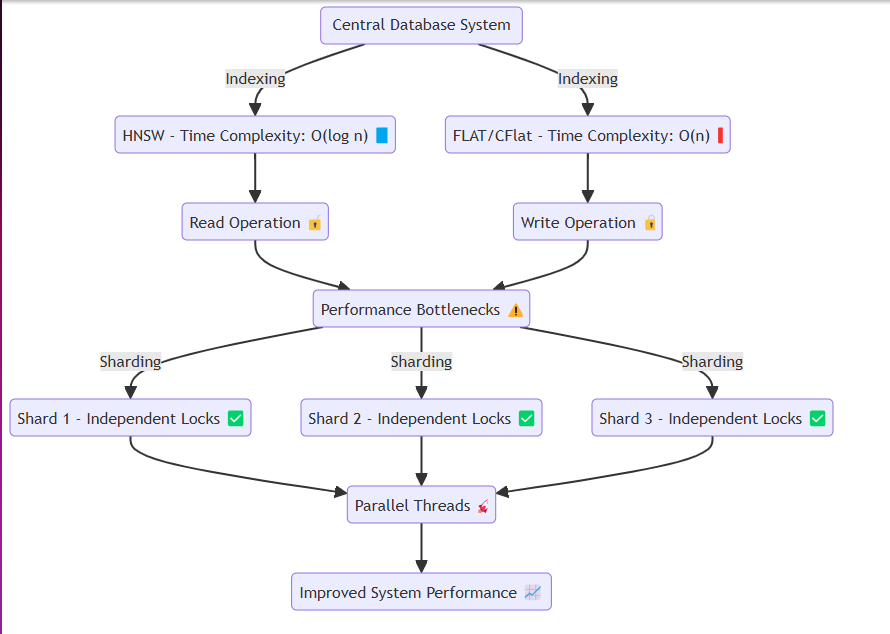 通常,諸如數據庫之類的系統訪問相同的內存或磁盤,反复執行讀寫操作。在此過程中,HNSW之類的方法可以實現有效的時間複雜性,例如O(log n) 。但是,需要準確性的技術,例如Flat和cflat,通常以O(n)的時間複雜性執行線性搜索。
通常,諸如數據庫之類的系統訪問相同的內存或磁盤,反复執行讀寫操作。在此過程中,HNSW之類的方法可以實現有效的時間複雜性,例如O(log n) 。但是,需要準確性的技術,例如Flat和cflat,通常以O(n)的時間複雜性執行線性搜索。
避免數據爭議時會出現問題。在閱讀或寫作時,諸如Goroutines之類的線程通過鎖來隔離各個資源。具體來說:
為了解決這個問題,我們設計了該系統以在內存中有效地創建碎片並將數據分配給每個碎片,而不會丟失系統的本質。每個碎片都具有鎖定機制,可以:
更快的鎖定發布:插入大量數據或執行讀取操作時。分區數據插入:通過允許數據插入分隔段來促進平滑系統操作。該設計可確保系統即使在重型數據插入或高讀取請求方案下也可以無縫操作,從而減輕性能瓶頸。
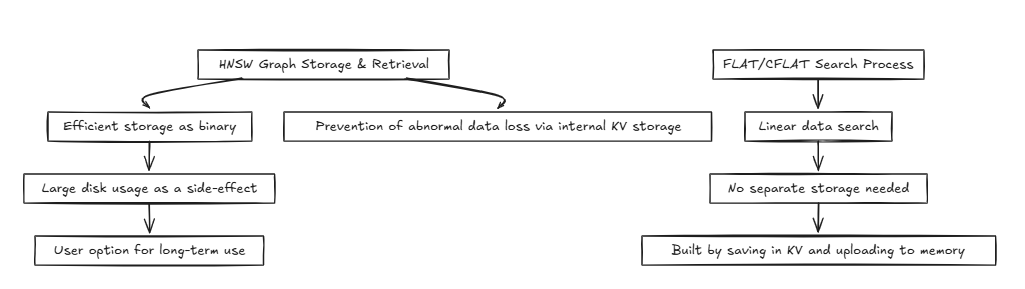
HNSW(層次可通航的小世界):
平坦/CFLAT(複合平面):
CFLAT(複合平面)是一種索引方法,它搜索多個向量並基於兩個向量的重要性產生復合結果。
將復合矢量搜索應用於HNSW之類的圖形算法很具有挑戰性,因為它需要大量的內存,並且與鄰域結構不符,因此需要多個圖形。儘管搜索的時間複雜性仍然會收斂到O(2 log n)≈O(log n),但空間複雜性非常差。
隨著數據的增加,這些問題變得越來越有問題。此外,基於圖形結構中的複合密鑰合併和評估的方法忽略了TOPK,並且顯著增加了單個搜索的堆大小。
因此,我們選擇基於平面處理。儘管時間複雜性為O(n)(沒有任何恆定降低),但空間複雜性與平坦相同,並且對於基於復合鍵的合併和評估非常有效。
Magine我們正在為一家對接公司開發一項服務,該公司可幫助用戶根據輸入標準找到理想的合作夥伴。我們將考慮各種因素,例如人格和其他屬性。但是,使用單個矢量意味著將這些因素組合到一個句子中進行搜索,這大大增加了準確性失真的可能性。
例如: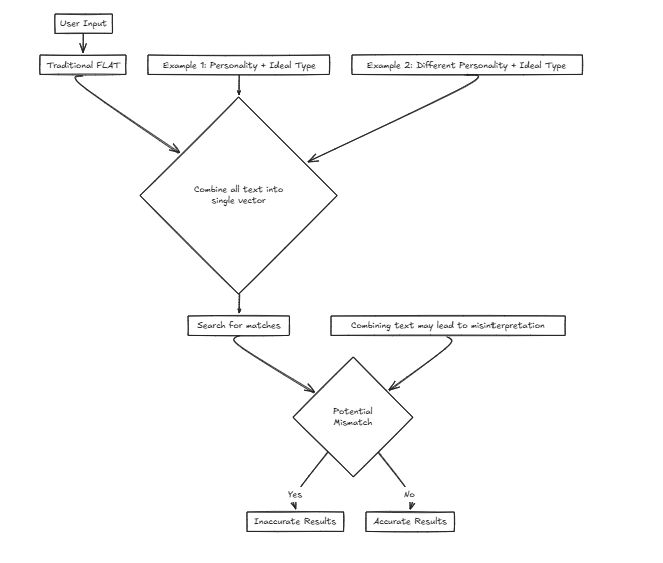 所需的特徵:{個性:決定性,理想類型:高大而苗條}在這種情況下,用戶更喜歡一種個性特徵,使人可以根據外部屬性找到理想的類型的人,重點是尋找伴侶。
所需的特徵:{個性:決定性,理想類型:高大而苗條}在這種情況下,用戶更喜歡一種個性特徵,使人可以根據外部屬性找到理想的類型的人,重點是尋找伴侶。
但是,考慮另一個情況:
所需的特徵:{個性:隨和的,理想的類型:決定性的}在這裡,想要隨和的性格與決定性理想類型的人可能會導致不正確的匹配,例如,與那些與用戶真正偏好不符的方式匹配的人。
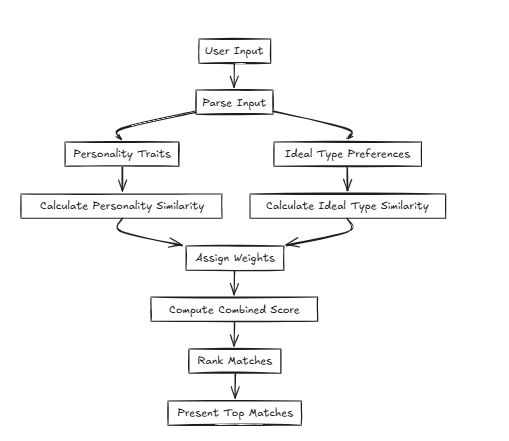 在這種情況下,CFLAT(複合平面)通過共同評估人格的相似性和理想類型的相似性來計算得分。用戶可以為每個屬性分配重要性級別,從而可以根據用戶定義的優先級給出具有更大相似性的方面的更高分數。
在這種情況下,CFLAT(複合平面)通過共同評估人格的相似性和理想類型的相似性來計算得分。用戶可以為每個屬性分配重要性級別,從而可以根據用戶定義的優先級給出具有更大相似性的方面的更高分數。
Edge是指無需與Central Server通信的情況下在附近設備上傳輸和接收數據的能力。但是,實際上,軟件中的“邊緣”有時可能與此概念有所不同,因為與中央服務器相比,它通常在更輕的,資源約束的環境中部署。
NNV-EDGE旨在以輕量級的方式在較小規模的矢量數據集(最多100萬個向量)上快速運行,從而將自動任務從原始NNV轉移回用戶,以獲得更大的控制。
高級算法,例如HNSW,Faiss和Foration很棒,但是您不認為它們對於較小規格的規格可能有些重嗎?並擱置算法,而米爾維斯(Milvus),編織和QDRANT等項目是由輝煌的頭腦構建的,但它們難道難道不太資源密集型,無法與小型便攜式設備上的其他軟件一起運行?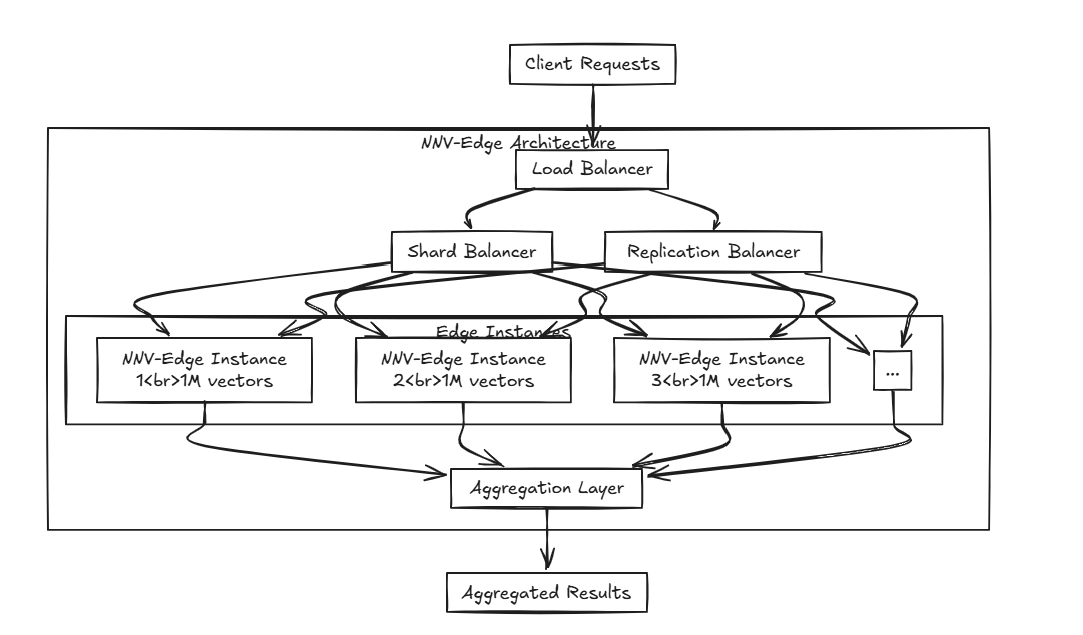 那就是NNV-Edge進來的地方。
那就是NNV-Edge進來的地方。
如果您分發多個邊緣怎麼辦?通過將NNV-EDGE與前面提到的負載平衡器一起使用,您可以創建一個高級設置,該設置可在多個邊緣劃分數據並無縫地匯總!


