nnv
1.0.0

NNV (No-Named.v) es una base de datos diseñada para implementarse desde cero hasta la producción. NNV se puede implementar en entornos de borde y usarse en configuraciones de producción a pequeña escala. A través del innovador enfoque arquitectónico que se describe a continuación, se prevé y se desarrolla para ser utilizado de manera confiable en entornos de producción a gran escala también.
Para el historial de actualización completa, consulte el historial de actualizaciones.
Planeamos admitir CFLAT, que puede facilitar varios servicios a través de operaciones más complejas que permiten las búsquedas de vectores múltiples. Cflat es simplemente un nombre que acuñé. ¡Tome nota!
El rendimiento puede reducirse temporalmente debido al desarrollo continuo. ¡Gracias por tu paciencia!
Windows & Linux
git clone https://github.com/sjy-dv/nnv
cd nnv
# start edge
go run cmd/root/main.go -mode=edge
# start core
go run cmd/root/main.go -mode=root
MacOS
** The CPU acceleration (SSE, AVX2, AVX-512) code has caused an error where it does not function on Mac, and it is not a priority to address at this time. **
git clone https://github.com/sjy-dv/nnv
cd nnv
source .env
deploy
make edge-dockerCaracterísticas
ARQUITECTURA
Corrección de errores
Al planificar este proyecto, lo pensé mucho.
Al configurar el entorno de clúster, es natural que la mayoría de los desarrolladores elijan el algoritmo de balsa, como siempre había hecho antes. La razón es que es un enfoque probado utilizado por proyectos exitosos.
Sin embargo, comencé a preguntarme: ¿no es un poco complejo? La balsa aumenta la disponibilidad de lectura, pero disminuye la disponibilidad de escritura. Entonces, ¿cómo resolvería esto si se vuelve necesario múltiples escrituras a largo plazo?
Dada la naturaleza de las bases de datos de vectores, supuse que la mayoría de los servicios se estructurarían en torno a trabajos por lotes en lugar de la escritura en tiempo real. Pero, ¿eso significa que puedo omitir abordar el problema? No lo pensé. Sin embargo, la construcción de una configuración de múltiples líderes sobre la balsa usando algo como Gossip se sintió extremadamente complejo y difícil. 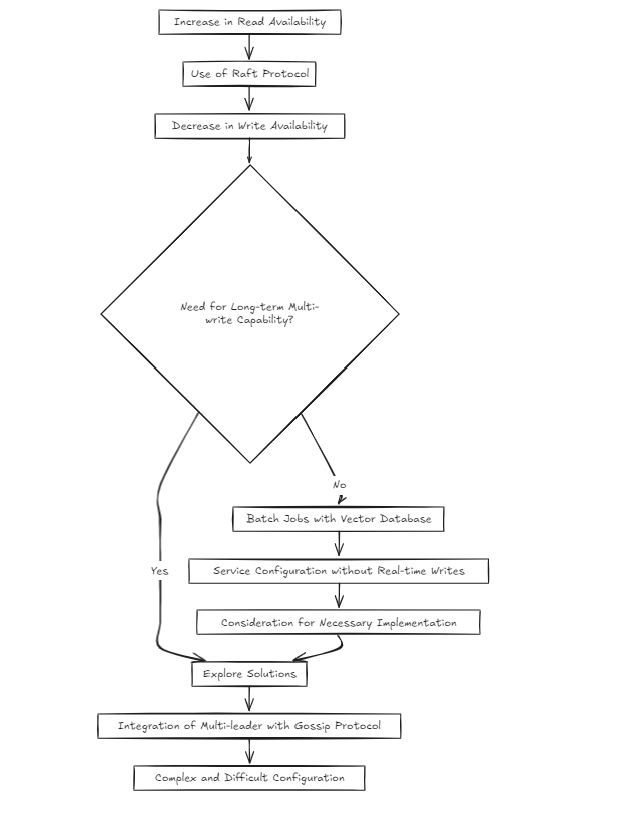
Por lo tanto, a partir de hoy (2024-10-20), estoy considerando dos enfoques arquitectónicos.
La arquitectura se divide en dos enfoques.
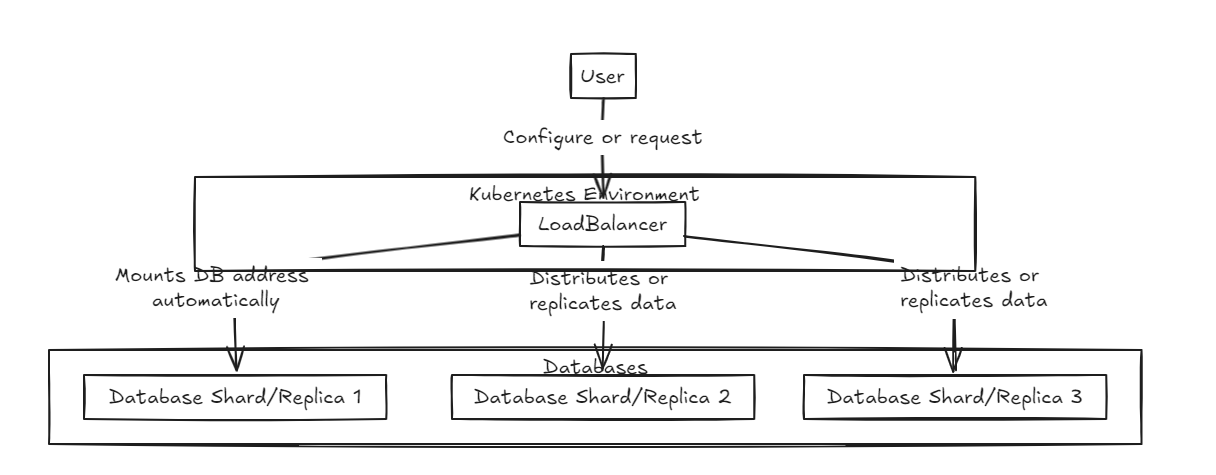
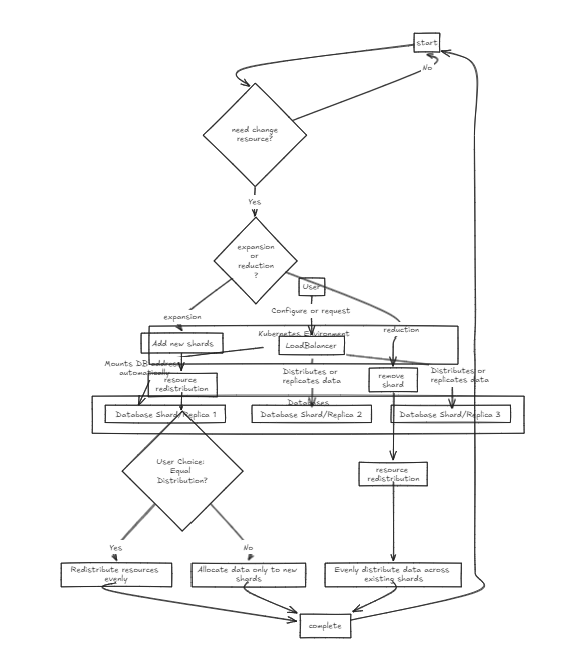
Primero, se coloca un equilibrador de carga en la parte delantera, lo que respalda el fragmento y la integración de los datos. La base de datos interna existe en un estado puro.
 |  |
|---|---|
| Réplica LB | LB de fragmentos |
El equilibrador de carga de replicación espera que todas las bases de datos completen con éxito las escrituras antes de cometer o rodar hacia atrás, mientras que el equilibrador de carga de fragmentos distribuye la carga de manera uniforme a través de las bases de datos de fragmentos para garantizar capacidades de almacenamiento similares.
La diferencia clave es que la replicación puede ralentizar las operaciones de escritura, pero proporciona un rendimiento de lectura más rápido a mediano y largo plazo en comparación con el equilibrador de carga de fragmentos. Por otro lado, el enfoque de fragmentos ofrece velocidades de escritura más rápidas porque solo se compromete a un fragmento específico, pero la lectura requiere recopilar datos de todos los fragmentos, que es más lento inicialmente, pero podría ser más rápido que la replicación a medida que el conjunto de datos crece.
Por lo tanto, para administrar grandes volúmenes de datos, el equilibrador de fragmentos es un poco más recomendado. Sin embargo, el punto principal de ambas arquitecturas es su simplicidad en la configuración y la gestión, lo que los hace tan fáciles de manejar como un servidor de backend típico.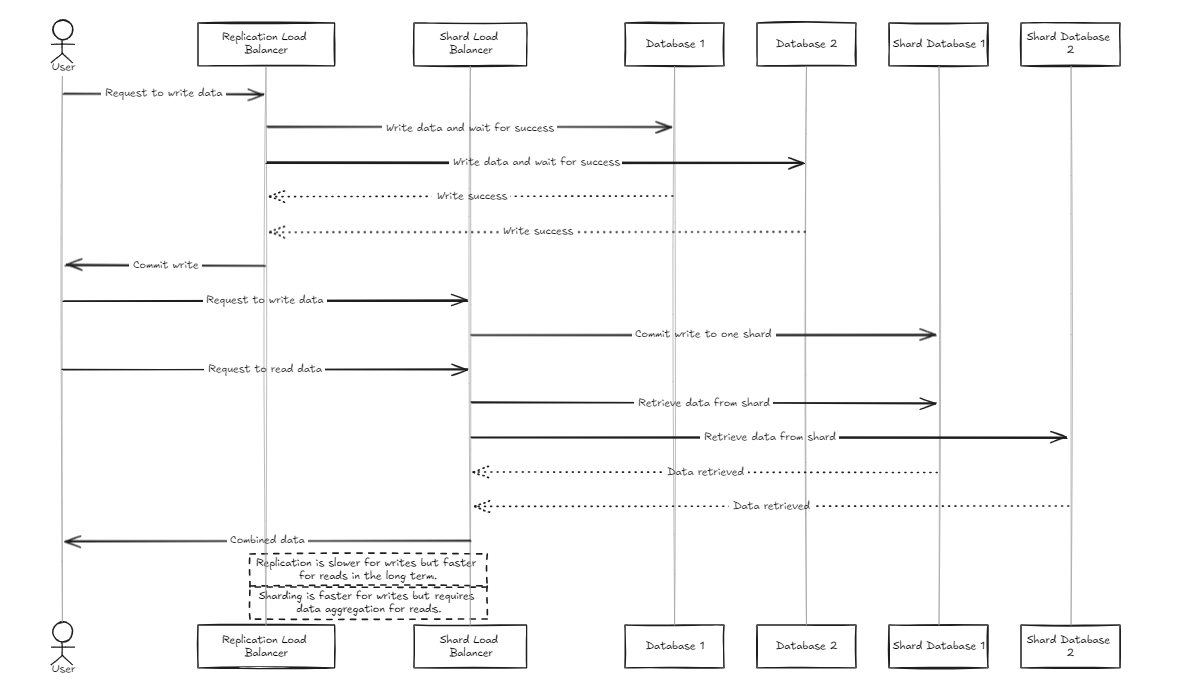
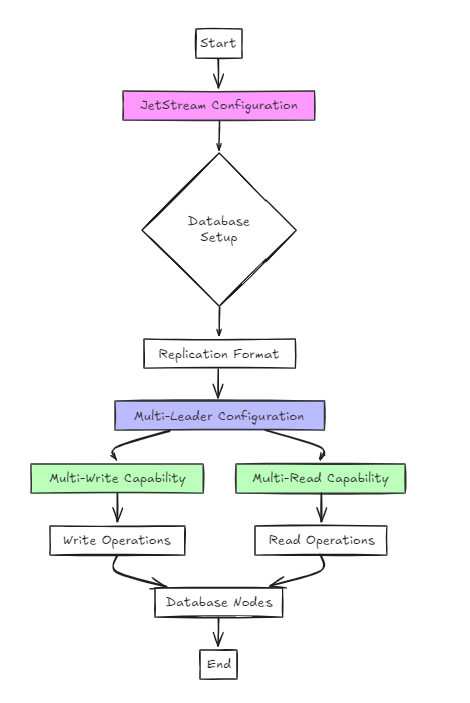
El segundo enfoque utiliza jetstream para la configuración.
Si bien esto es arquitectónicamente más simple que el enfoque anterior, desde la perspectiva del usuario, la configuración no es significativamente diferente de la balsa.
Sin embargo, la diferencia clave es que, a diferencia de la balsa, admite configuraciones múltiples de escritura y lectura múltiple, en lugar de una sola escritura y lectura múltiple.
En este enfoque, la base de datos está configurada en un formato de replicación, y JetStream se utiliza para habilitar configuraciones de líderes múltiples.
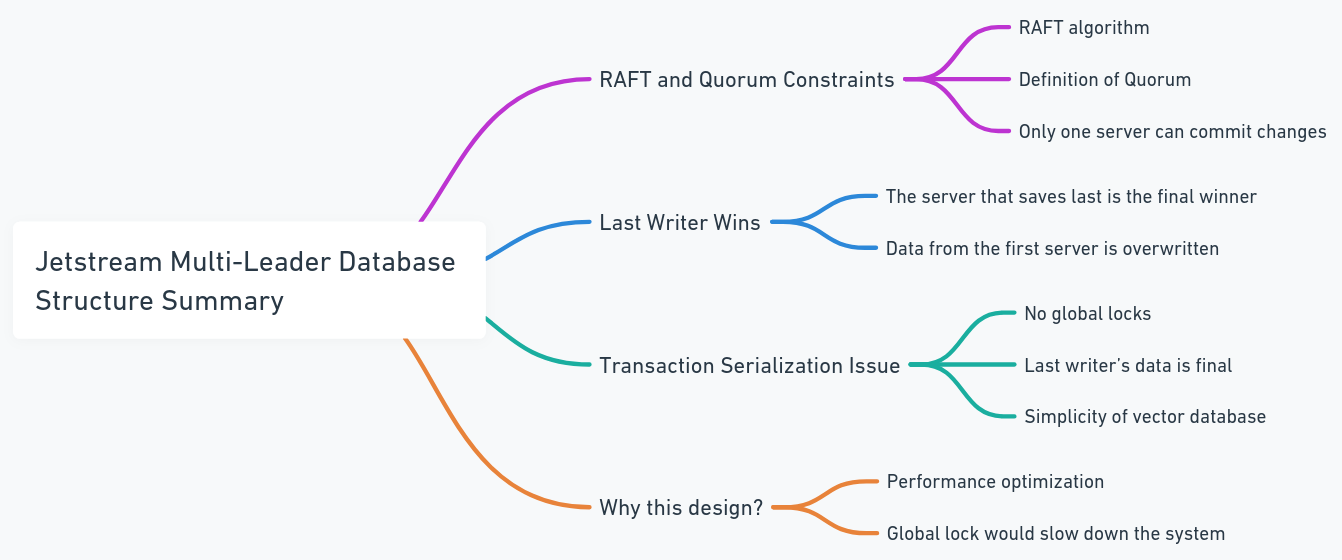
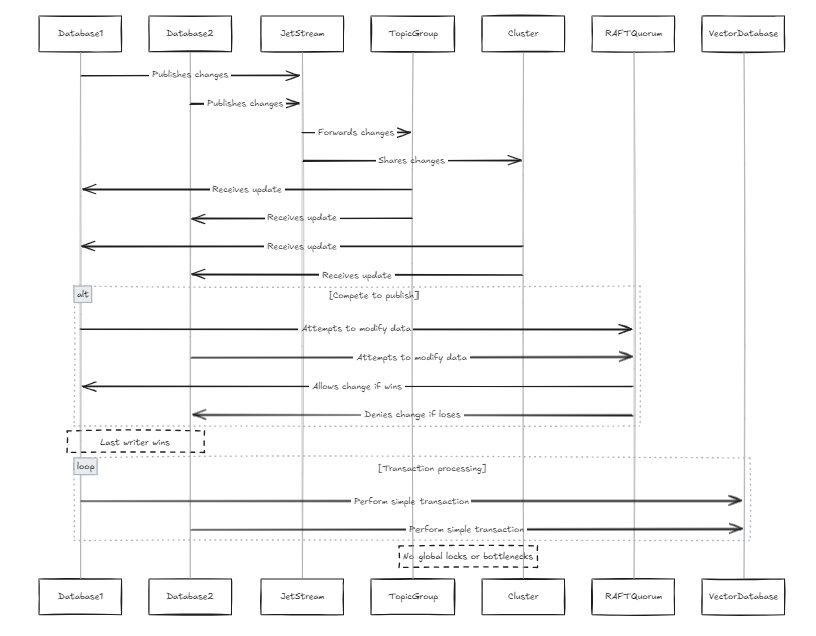 Cada base de datos contiene su propio jetstream, y estos jetstreams se unen al mismo grupo de temas y clústeres. En este caso, cada vez que todos los nodos intentan publicar cambios en una fila, pasan a través del mismo JetStream. Si dos nodos intentan modificar los mismos datos en paralelo, competirán para publicar sus cambios. Si bien es posible evitar que los cambios se propagen, esto podría conducir a la pérdida de datos. Según la restricción de quórum de la balsa en Jetstream, solo un escritor puede publicar el cambio. Por lo tanto, diseñamos el sistema para permitir que el último escritor gane. Este no es un problema para las bases de datos vectoriales porque, en comparación con las bases de datos tradicionales, la estructura de datos es más simple (esto no implica que el sistema en sí sea simple, sino que hay menos transacciones y procedimientos complejos, como la serialización de la transacción). Esto también evita cerraduras globales y cuellos de botella de rendimiento.
Cada base de datos contiene su propio jetstream, y estos jetstreams se unen al mismo grupo de temas y clústeres. En este caso, cada vez que todos los nodos intentan publicar cambios en una fila, pasan a través del mismo JetStream. Si dos nodos intentan modificar los mismos datos en paralelo, competirán para publicar sus cambios. Si bien es posible evitar que los cambios se propagen, esto podría conducir a la pérdida de datos. Según la restricción de quórum de la balsa en Jetstream, solo un escritor puede publicar el cambio. Por lo tanto, diseñamos el sistema para permitir que el último escritor gane. Este no es un problema para las bases de datos vectoriales porque, en comparación con las bases de datos tradicionales, la estructura de datos es más simple (esto no implica que el sistema en sí sea simple, sino que hay menos transacciones y procedimientos complejos, como la serialización de la transacción). Esto también evita cerraduras globales y cuellos de botella de rendimiento.
Ver la arquitectura antigua
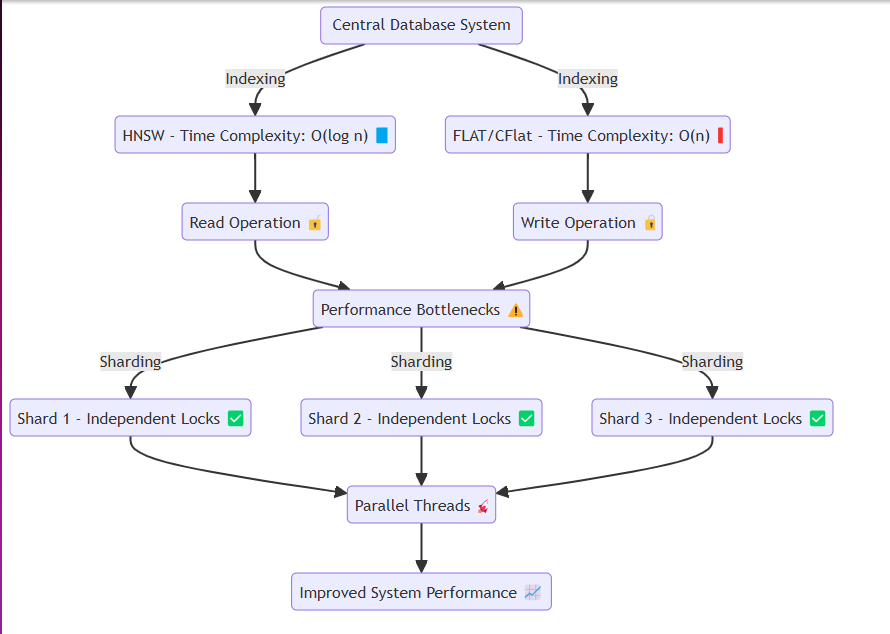 Por lo general, los sistemas como las bases de datos acceden a la misma memoria o disco, realizando repetidamente operaciones de lectura y escritura. En este proceso, métodos como HNSW pueden lograr complejidades de tiempo eficientes como O (log n) . Sin embargo, las técnicas que requieren precisión, como Flat y CFLAT, generalmente ejecutan búsquedas lineales con una complejidad de tiempo de O (N) .
Por lo general, los sistemas como las bases de datos acceden a la misma memoria o disco, realizando repetidamente operaciones de lectura y escritura. En este proceso, métodos como HNSW pueden lograr complejidades de tiempo eficientes como O (log n) . Sin embargo, las técnicas que requieren precisión, como Flat y CFLAT, generalmente ejecutan búsquedas lineales con una complejidad de tiempo de O (N) .
El problema surge al evitar la contención de datos. Al leer o escribir, los hilos como las goroutinas aislan los recursos respectivos a través de cerraduras. Específicamente:
Para abordar esto, hemos diseñado el sistema para crear fragmentos de manera eficiente en la memoria y asignar datos a cada fragmento sin perder la esencia del sistema. Cada fragmento presenta un mecanismo de bloqueo que permite:
Liberación de bloqueo más rápida : al insertar grandes cantidades de datos o realizar operaciones de lectura. Inserción de datos particionados : facilitar las operaciones suaves del sistema al permitir que los datos se inserten en segmentos divididos. Este diseño asegura que el sistema pueda funcionar a la perfección incluso bajo una pesada inserción de datos o escenarios de solicitud de lectura alta, mitigando así los cuellos de botella de rendimiento.
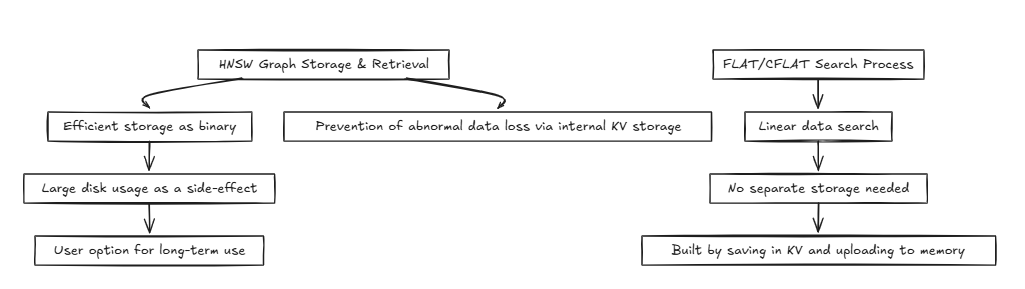
HNSW (mundo pequeño jerárquico navegable):
Plano/cflat (compuesto plano):
CFLAT (compuesto plano) es un método de indexación que busca múltiples vectores y produce resultados compuestos basados en la importancia de dos vectores.
La aplicación de la búsqueda vectorial compuesta a algoritmos de gráficos como HNSW es un desafío porque requiere una cantidad significativa de memoria y no se alinea bien con las estructuras del vecindario, lo que requiere múltiples gráficos. Aunque la complejidad del tiempo para la búsqueda aún converge a O (2 log n) ≈ O (log n), la complejidad del espacio es considerablemente pobre.
Estos problemas se vuelven cada vez más problemáticos a medida que crece la cantidad de datos. Además, el método de fusión y evaluación basada en claves compuestas dentro de la estructura de gráficos ignora TOPK y aumenta significativamente el tamaño del montón para una sola búsqueda.
Por lo tanto, hemos optado por procesar en función de Flat. Aunque la complejidad del tiempo es O (N) (sin caídas constantes), la complejidad del espacio sigue siendo la misma que plana, y es altamente efectiva para fusionar y evaluar según las teclas compuestas.
Magine estamos desarrollando un servicio para una empresa de emparejamiento que ayuda a los usuarios a encontrar sus socios ideales en función de los criterios de entrada. Consideraremos varios factores, como la personalidad y otros atributos. Sin embargo, usar un solo vector significa combinar estos factores en una oración para la búsqueda, lo que aumenta en gran medida la probabilidad de distorsión de precisión.
Por ejemplo: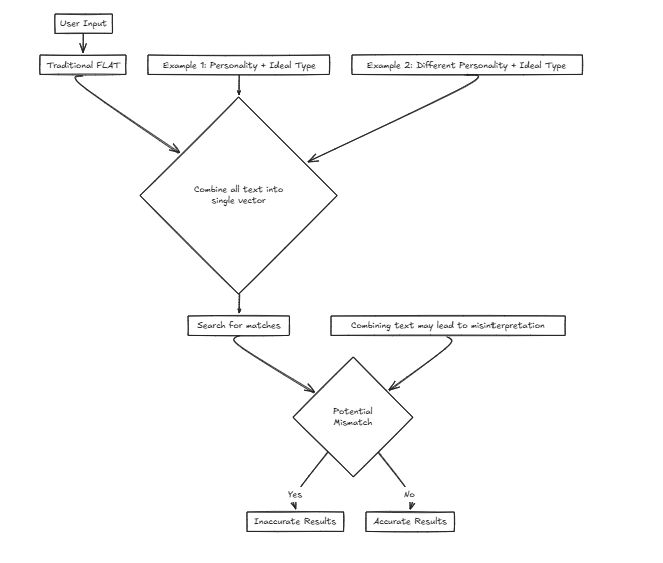 Rasgos deseados: {Personalidad: Tipo decisivo, ideal: alto y delgado} En este escenario, el usuario prefiere un rasgo de personalidad que hace que el tipo ideal sea que alguien sea probable que los aprecie, enfocándose en encontrar una pareja basada en atributos externos.
Rasgos deseados: {Personalidad: Tipo decisivo, ideal: alto y delgado} En este escenario, el usuario prefiere un rasgo de personalidad que hace que el tipo ideal sea que alguien sea probable que los aprecie, enfocándose en encontrar una pareja basada en atributos externos.
Sin embargo, considere otro caso:
Rasgos deseados: {Personalidad: Tipo Ideal e Ideal: decisivo} Aquí, alguien que quiere una personalidad sencilla combinada con un tipo ideal decisivo podría dar lugar a coincidencias incorrectas, como una coincidencia con personas que son decisivas de manera que no se alinee con las verdaderas preferencias del usuario.
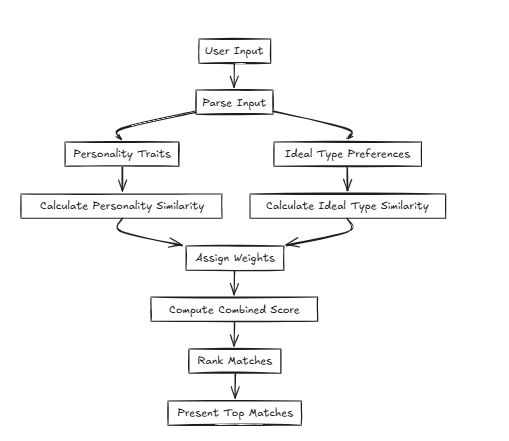 En tales casos, CFLAT (compuesto plano) calcula las puntuaciones evaluando conjuntamente la similitud en la personalidad y la similitud en el tipo ideal. Los usuarios pueden asignar niveles de importancia a cada atributo, permitiendo que se otorguen puntajes más altos a los aspectos con mayor similitud basada en prioridades definidas por el usuario.
En tales casos, CFLAT (compuesto plano) calcula las puntuaciones evaluando conjuntamente la similitud en la personalidad y la similitud en el tipo ideal. Los usuarios pueden asignar niveles de importancia a cada atributo, permitiendo que se otorguen puntajes más altos a los aspectos con mayor similitud basada en prioridades definidas por el usuario.
Edge se refiere a la capacidad de transmitir y recibir datos sobre dispositivos cercanos sin comunicación con un servidor central. Sin embargo, en la práctica, el "borde" en el software a veces puede diferir de este concepto, ya que a menudo se implementa en entornos más ligeros y limitados por recursos en comparación con un servidor central.
NNV-Edge está diseñado para operar rápidamente en conjuntos de datos vectoriales a menor escala (hasta 1 millón de vectores) de manera liviana, transfiriendo tareas automatizadas desde el NNV original al usuario para un mayor control.
Algoritmos avanzados como HNSW, Faiss y Moln son excelentes, pero ¿no crees que pueden ser un poco pesados para las especificaciones de menor escala? Y reservar algoritmos, mientras que proyectos como Milvus, Weaviate y Qdrant están construidos por mentes brillantes, ¿no son un poco demasiado intensivos en recursos para correr junto con otro software en dispositivos pequeños y portátiles?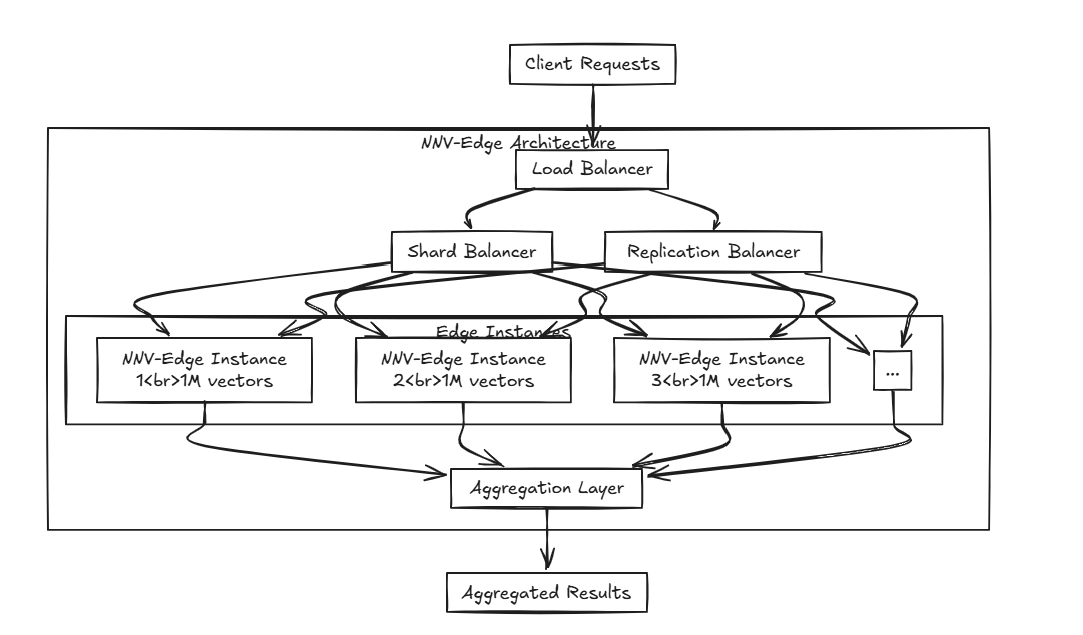 Ahí es donde entra NNV-Edge.
Ahí es donde entra NNV-Edge.
¿Qué pasa si distribuye varios bordes? Al usar NNV-EDED con el equilibrador de carga mencionado anteriormente, ¡puede crear una configuración avanzada que frote los datos en múltiples bordes y los agregue sin problemas!


