nnv
1.0.0

NNV(no-Named.v)是一个数据库,旨在从头到生产实现。 NNV可以部署在边缘环境中,并用于小规模生产设置。通过下面描述的创新建筑方法,它也可以在大规模生产环境中可靠地使用。
有关完整的更新历史记录,请参阅更新历史记录。
我们计划支持CFLAT,这可以通过更复杂的操作来促进各种服务,从而实现多向量搜索。 CFLAT只是我创造的名字。请注意!
由于正在进行的发展,绩效可能会暂时降低。谢谢您的耐心等待!
Windows & Linux
git clone https://github.com/sjy-dv/nnv
cd nnv
# start edge
go run cmd/root/main.go -mode=edge
# start core
go run cmd/root/main.go -mode=root
MacOS
** The CPU acceleration (SSE, AVX2, AVX-512) code has caused an error where it does not function on Mac, and it is not a priority to address at this time. **
git clone https://github.com/sjy-dv/nnv
cd nnv
source .env
deploy
make edge-docker特征
建筑学
BugFix
在计划这个项目时,我考虑了很多。
在设置群集环境时,大多数开发人员自然会像以前那样选择木筏算法。原因是这是成功项目使用的一种经过验证的方法。
但是,我开始怀疑:这不是有点复杂吗?筏提高了读取的可用性,但降低了写入可用性。那么,如果从长远来看,多写的话,我该如何解决?
鉴于矢量数据库的性质,我认为大多数服务都是围绕批处理作业而不是实时写作构建的。但这是否意味着我可以跳过解决这个问题?我不这么认为。但是,使用八卦之类的东西在筏上建立多领导者设置感到非常复杂和困难。 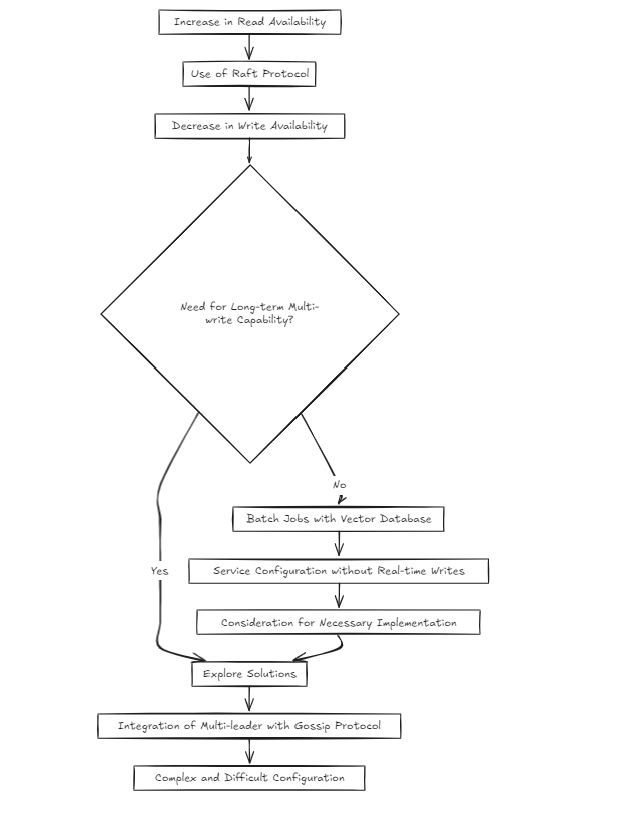
因此,截至今天(2024-10-20),我正在考虑两种建筑方法。
该体系结构分为两种方法。
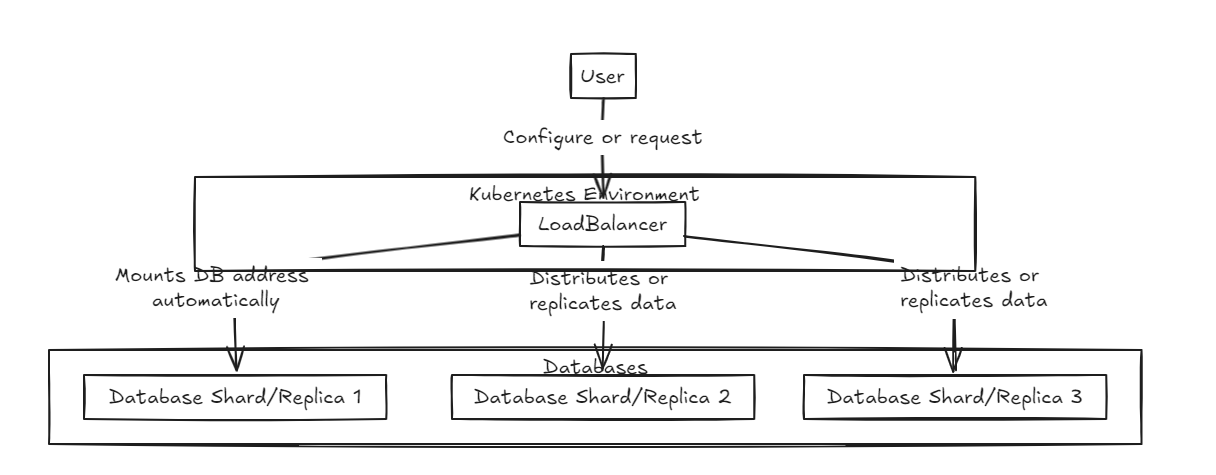
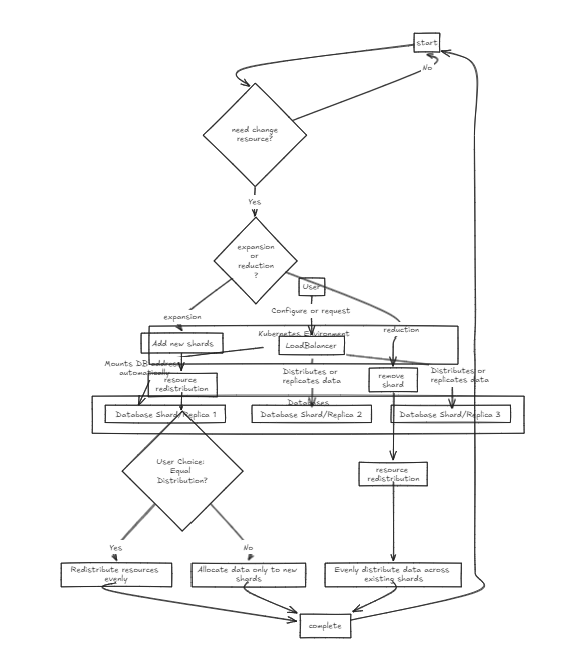
首先,将负载平衡器放在前面,支持数据的分片和集成。内部数据库存在于纯状态。
 |  |
|---|---|
| 复制磅 | 碎片 |
复制负载均衡器等待所有数据库在投入或回滚之前成功完成写入,而碎片负载平衡器在整个碎片数据库中均匀分配负载,以确保类似的存储能力。
关键区别在于,复制可以减慢写入操作,但与碎片负载平衡器相比,在长期到长期中提供更快的读取性能。另一方面,碎片方法提供更快的写作速度,因为它仅投入特定的碎片,但是阅读需要从所有碎片中收集数据,最初速度较慢,但随着数据集增长的增长可能比复制更快。
因此,为了管理大量数据,建议使用碎片平衡器。但是,这两个体系结构的重点是它们在设置和管理方面的简单性,使它们像典型的后端服务器一样易于处理。 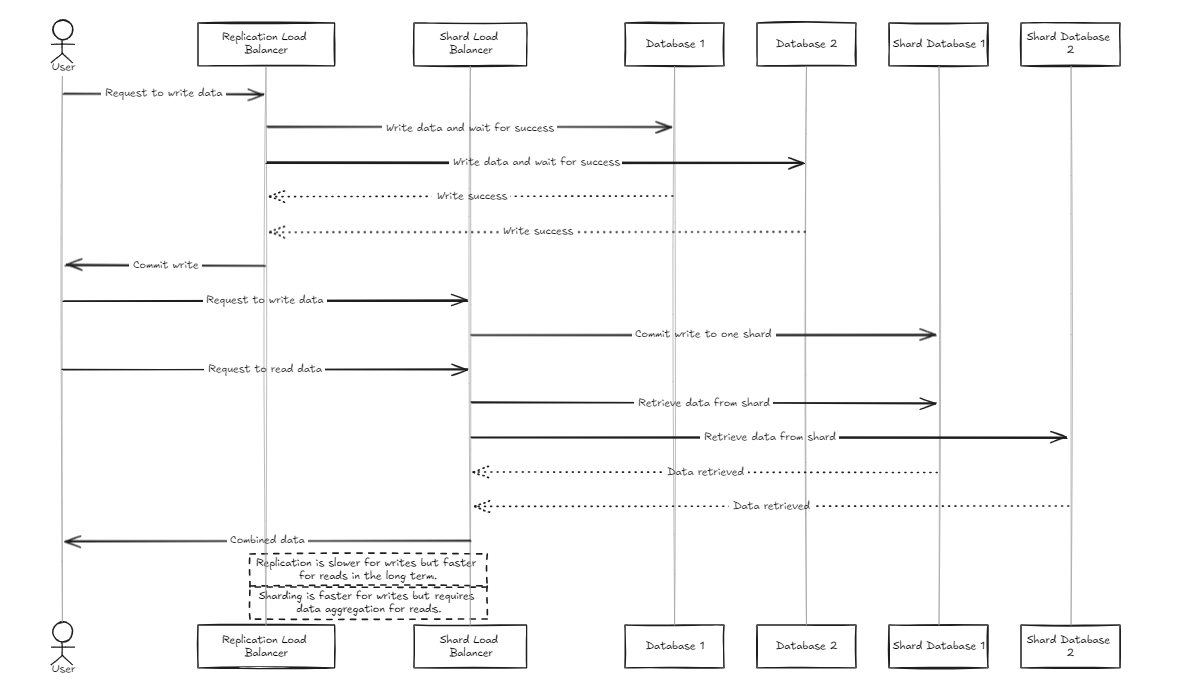
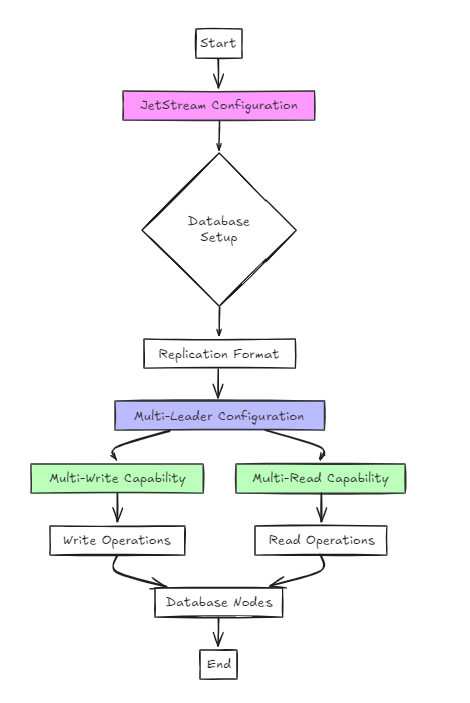
第二种方法利用喷头进行配置。
尽管从用户的角度来看,这在架构上比以前的方法更简单,但设置与RAFT没有显着差异。
但是,关键区别在于,与筏子不同,它支持多写的和多读的配置,而不是单写的和多读。
在这种方法中,数据库以复制格式配置,并且使用Jetstream用于启用多领导配置。
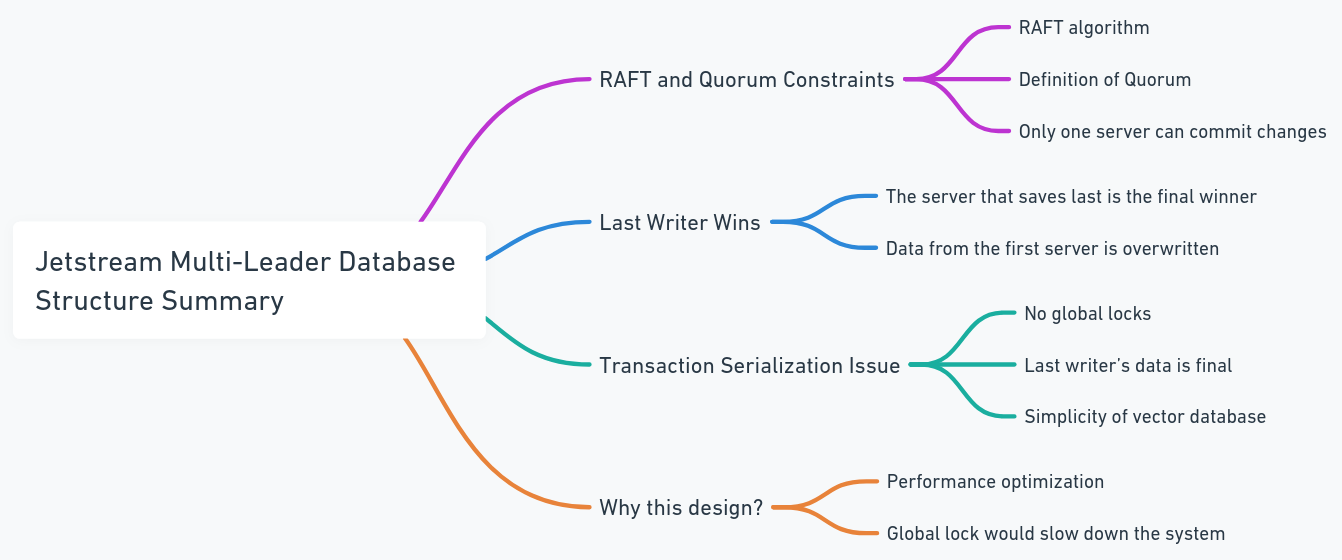
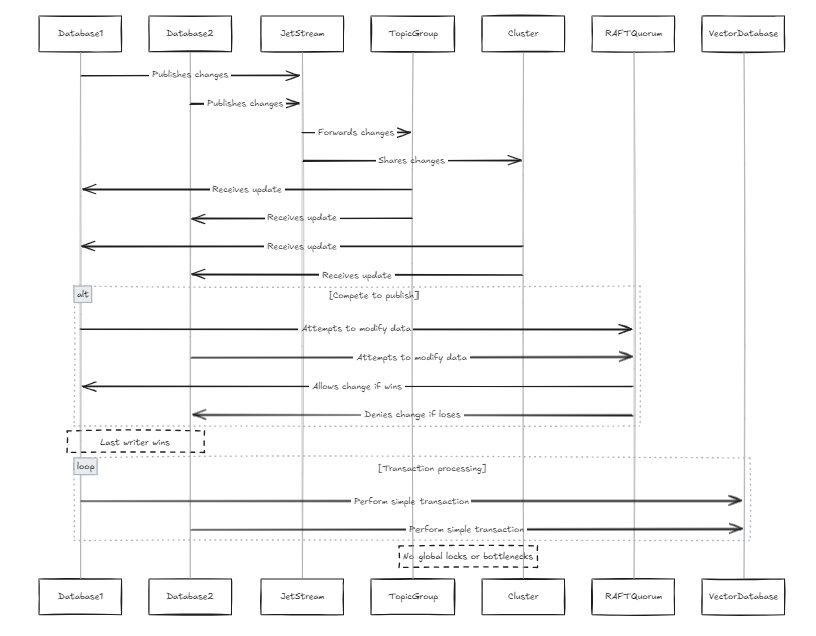 每个数据库都包含其自己的射击,这些喷头加入了相同的主题和群集。在这种情况下,每当所有节点都尝试发布对行更改时,它们都会通过相同的喷头。如果两个节点试图并行修改相同的数据,他们将竞争发布其更改。虽然有可能防止变化被传播,但这可能导致数据丢失。根据Jetstream中的Raft Quorum约束,只有一个作者可以发布更改。因此,我们设计了该系统以允许最后一位作家获胜。对于向量数据库而言,这不是问题,因为与传统数据库相比,数据结构更简单(这并不意味着系统本身很简单,而是更少的复杂交易和过程,例如交易序列化)。这也避免了全球锁和性能瓶颈。
每个数据库都包含其自己的射击,这些喷头加入了相同的主题和群集。在这种情况下,每当所有节点都尝试发布对行更改时,它们都会通过相同的喷头。如果两个节点试图并行修改相同的数据,他们将竞争发布其更改。虽然有可能防止变化被传播,但这可能导致数据丢失。根据Jetstream中的Raft Quorum约束,只有一个作者可以发布更改。因此,我们设计了该系统以允许最后一位作家获胜。对于向量数据库而言,这不是问题,因为与传统数据库相比,数据结构更简单(这并不意味着系统本身很简单,而是更少的复杂交易和过程,例如交易序列化)。这也避免了全球锁和性能瓶颈。
查看旧建筑
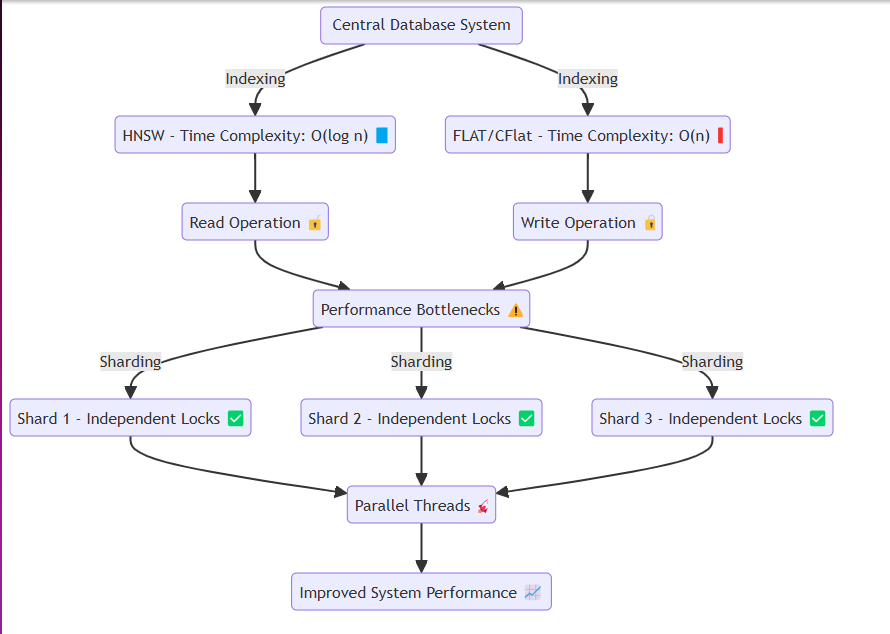 通常,诸如数据库之类的系统访问相同的内存或磁盘,反复执行读写操作。在此过程中,HNSW之类的方法可以实现有效的时间复杂性,例如O(log n) 。但是,需要准确性的技术,例如Flat和cflat,通常以O(n)的时间复杂性执行线性搜索。
通常,诸如数据库之类的系统访问相同的内存或磁盘,反复执行读写操作。在此过程中,HNSW之类的方法可以实现有效的时间复杂性,例如O(log n) 。但是,需要准确性的技术,例如Flat和cflat,通常以O(n)的时间复杂性执行线性搜索。
避免数据争议时会出现问题。在阅读或写作时,诸如Goroutines之类的线程通过锁来隔离各个资源。具体来说:
为了解决这个问题,我们设计了该系统以在内存中有效地创建碎片并将数据分配给每个碎片,而不会丢失系统的本质。每个碎片都具有锁定机制,可以:
更快的锁定发布:插入大量数据或执行读取操作时。分区数据插入:通过允许数据插入分隔段来促进平滑系统操作。该设计可确保系统即使在重型数据插入或高读取请求方案下也可以无缝操作,从而减轻性能瓶颈。
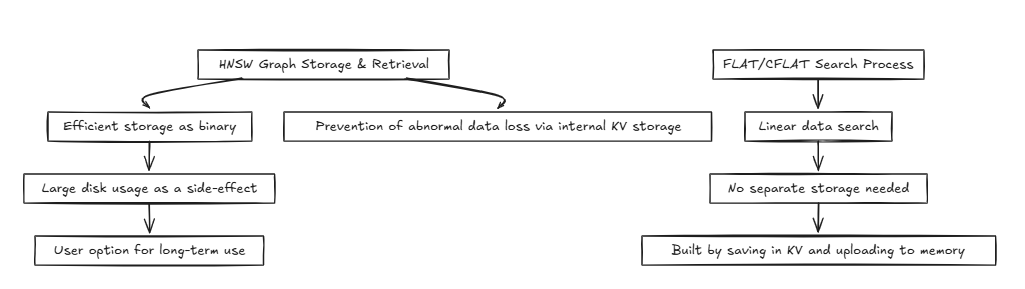
HNSW(层次可通航的小世界):
平坦/CFLAT(复合平面):
CFLAT(复合平面)是一种索引方法,它搜索多个向量并基于两个向量的重要性产生复合结果。
将复合矢量搜索应用于HNSW之类的图形算法很具有挑战性,因为它需要大量的内存,并且与邻域结构不符,因此需要多个图形。尽管搜索的时间复杂性仍然会收敛到O(2 log n)≈O(log n),但空间复杂性非常差。
随着数据的增加,这些问题变得越来越有问题。此外,基于图形结构中的复合密钥合并和评估的方法忽略了TOPK,并且显着增加了单个搜索的堆大小。
因此,我们选择基于平面处理。尽管时间复杂性为O(n)(没有任何恒定降低),但空间复杂性与平坦相同,并且对于基于复合键的合并和评估非常有效。
Magine我们正在为一家对接公司开发一项服务,该公司可帮助用户根据输入标准找到理想的合作伙伴。我们将考虑各种因素,例如人格和其他属性。但是,使用单个矢量意味着将这些因素组合到一个句子中进行搜索,这大大增加了准确性失真的可能性。
例如: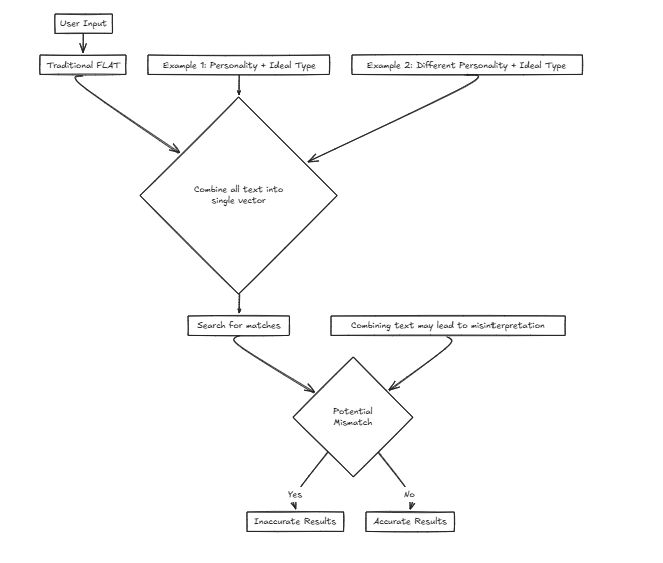 所需的特征:{个性:决定性,理想类型:高大而苗条}在这种情况下,用户更喜欢一种个性特征,使人可以根据外部属性找到理想的类型的人,重点是寻找伴侣。
所需的特征:{个性:决定性,理想类型:高大而苗条}在这种情况下,用户更喜欢一种个性特征,使人可以根据外部属性找到理想的类型的人,重点是寻找伴侣。
但是,考虑另一个情况:
所需的特征:{个性:随和的,理想的类型:决定性的}在这里,想要随和的性格与决定性理想类型的人可能会导致不正确的匹配,例如,与那些与用户真正偏好不符的方式匹配的人。
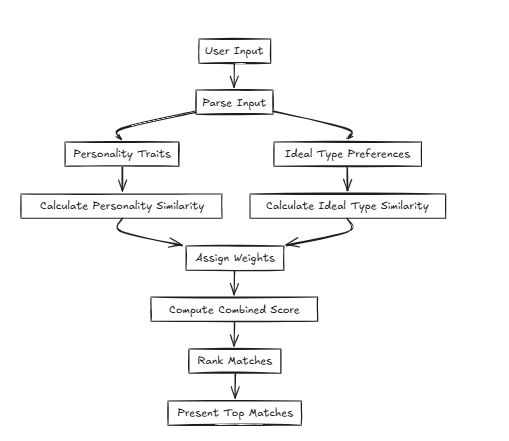 在这种情况下,CFLAT(复合平面)通过共同评估人格的相似性和理想类型的相似性来计算得分。用户可以为每个属性分配重要性级别,从而可以根据用户定义的优先级给出具有更大相似性的方面的更高分数。
在这种情况下,CFLAT(复合平面)通过共同评估人格的相似性和理想类型的相似性来计算得分。用户可以为每个属性分配重要性级别,从而可以根据用户定义的优先级给出具有更大相似性的方面的更高分数。
Edge是指无需与Central Server通信的情况下在附近设备上传输和接收数据的能力。但是,实际上,软件中的“边缘”有时可能与此概念有所不同,因为与中央服务器相比,它通常在更轻的,资源约束的环境中部署。
NNV-EDGE旨在以轻量级的方式在较小规模的矢量数据集(最多100万个向量)上快速运行,从而将自动任务从原始NNV转移回用户,以获得更大的控制。
高级算法,例如HNSW,Faiss和Foration很棒,但是您不认为它们对于较小规格的规格可能有些重吗?并搁置算法,而米尔维斯(Milvus),编织和QDRANT等项目是由辉煌的头脑构建的,但它们难道难道不太资源密集型,无法与小型便携式设备上的其他软件一起运行?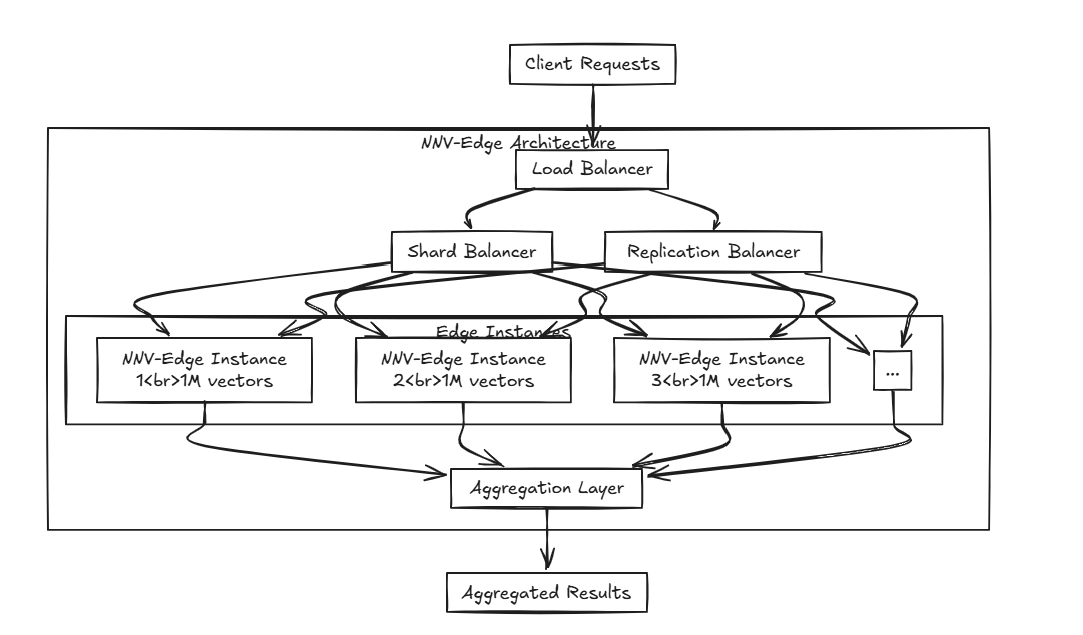 那就是NNV-Edge进来的地方。
那就是NNV-Edge进来的地方。
如果您分发多个边缘怎么办?通过将NNV-EDGE与前面提到的Load Balancer一起使用,您可以创建一个高级设置,该设置可在多个边缘划分数据并无缝地汇总!


