nnv
1.0.0

NNV (no-name.v)는 처음부터 생산으로 구현되도록 설계된 데이터베이스입니다. NNV는 Edge 환경에 배치되어 소규모 생산 설정에 사용할 수 있습니다. 아래에 설명 된 혁신적인 건축 접근법을 통해 대규모 생산 환경에서도 안정적으로 사용하도록 구상되고 개발되었습니다.
전체 업데이트 기록은 업데이트 기록을 참조하십시오.
우리는 다중 벡터 검색을 가능하게하는보다 복잡한 운영을 통해 다양한 서비스를 촉진 할 수있는 CFLAT를 지원할 계획입니다. CFLAT는 단지 내가 만들어 낸 이름 일뿐입니다. 메모하십시오!
지속적인 개발로 인해 성능이 일시적으로 줄어들 수 있습니다. 인내심에 감사드립니다!
Windows & Linux
git clone https://github.com/sjy-dv/nnv
cd nnv
# start edge
go run cmd/root/main.go -mode=edge
# start core
go run cmd/root/main.go -mode=root
MacOS
** The CPU acceleration (SSE, AVX2, AVX-512) code has caused an error where it does not function on Mac, and it is not a priority to address at this time. **
git clone https://github.com/sjy-dv/nnv
cd nnv
source .env
deploy
make edge-docker특징
건축학
버그 문제
이 프로젝트를 계획 할 때 많은 생각을했습니다.
클러스터 환경을 설정할 때 대부분의 개발자가 항상 이전에했던 것처럼 RAFT 알고리즘을 선택하는 것이 당연합니다. 그 이유는 성공적인 프로젝트에서 사용되는 입증 된 접근 방식이기 때문입니다.
그러나 나는 궁금해지기 시작했다 : 조금 복잡하지 않습니까? 래프트는 읽기 가용성을 증가 시키지만 쓰기 가용성을 줄입니다. 그렇다면 장기적으로 다중 쓰기가 필요 해지면 어떻게 해결할 것인가?
벡터 데이터베이스의 특성을 고려할 때, 나는 대부분의 서비스가 실시간 쓰기보다는 배치 작업을 중심으로 구성 될 것이라고 가정했습니다. 그러나 그것은 내가 문제를 해결하는 것을 건너 뛸 수 있다는 것을 의미합니까? 나는 그렇게 생각하지 않았다. 그러나 가십과 같은 것을 사용하여 래프트 위에 멀티 리더 설정을 구축하는 것은 매우 복잡하고 어려운 느낌이 들었습니다. 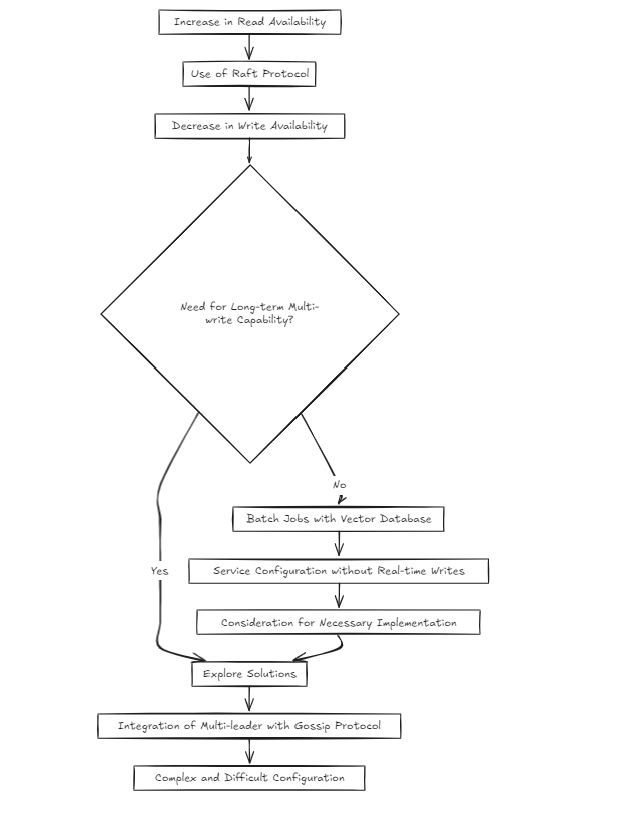
따라서 오늘날 (2024-10-20), 나는 두 가지 건축 접근법을 고려하고 있습니다.
아키텍처는 두 가지 접근 방식으로 나뉩니다.
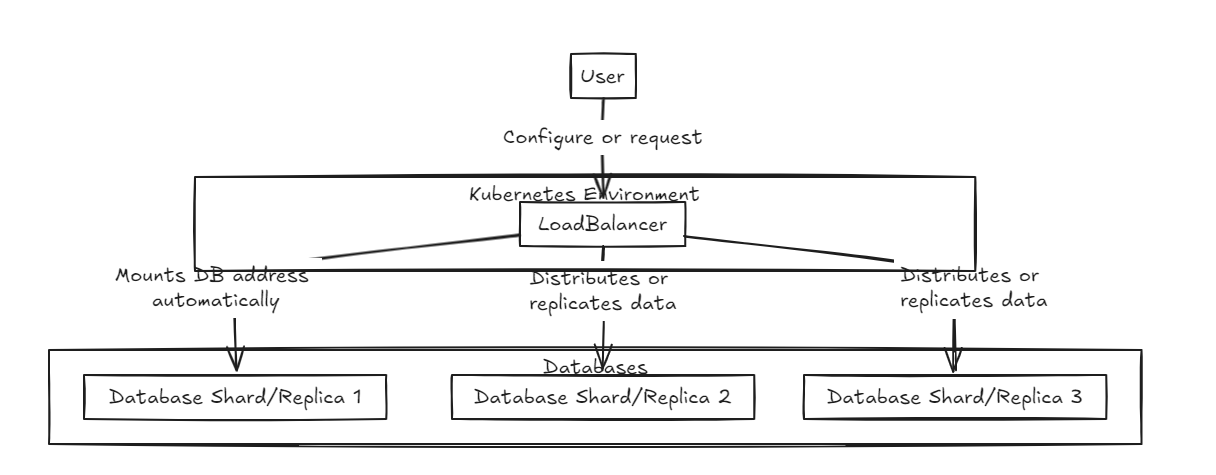
먼저,로드 밸런서가 전면에 배치되어 데이터의 샤딩 및 통합을 모두 지원합니다. 내부 데이터베이스는 순수한 상태로 존재합니다.
 |  |
|---|---|
| 복제 LB | 샤드 LB |
복제로드 밸런서는 모든 데이터베이스가 커밋하거나 롤백하기 전에 쓰기를 성공적으로 완료하기를 기다리는 반면, 샤드로드 밸런서는 유사한 스토리지 용량을 보장하기 위해 샤드 데이터베이스 전체에 부하를 고르게 배포합니다.
주요 차이점은 복제가 쓰기 작업 속도를 늦출 수 있지만 샤드 하중 밸런서에 비해 중기에서 장기적으로 더 빠른 읽기 성능을 제공한다는 것입니다. 반면에, Shard Approach는 특정 샤드에만 저장하기 때문에 더 빠른 쓰기 속도를 제공하지만, 읽기는 모든 파편에서 데이터를 수집해야하며, 처음에는 느리지 만 데이터 세트가 성장함에 따라 복제보다 더 빠르게 될 수 있습니다.
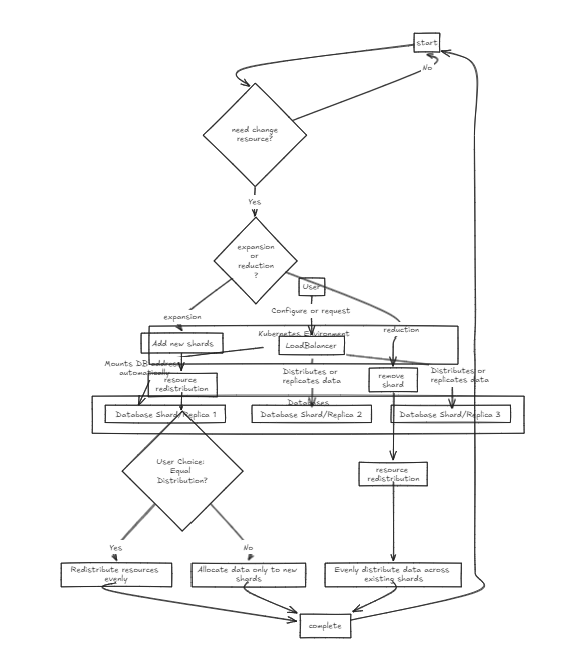
따라서 대량의 데이터를 관리하기 위해서는 샤드 밸런서가 약간 더 권장됩니다. 그러나 두 아키텍처의 주요 요점은 설정 및 관리의 단순성이므로 일반적인 백엔드 서버만큼 쉽게 처리 할 수 있습니다.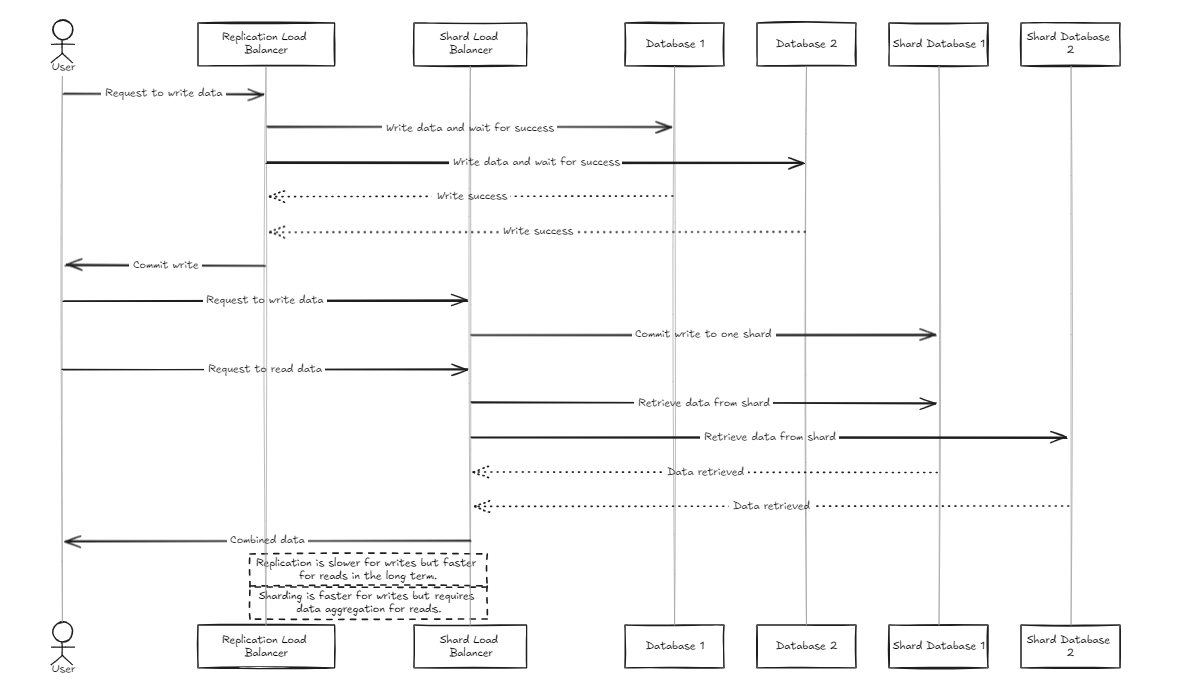
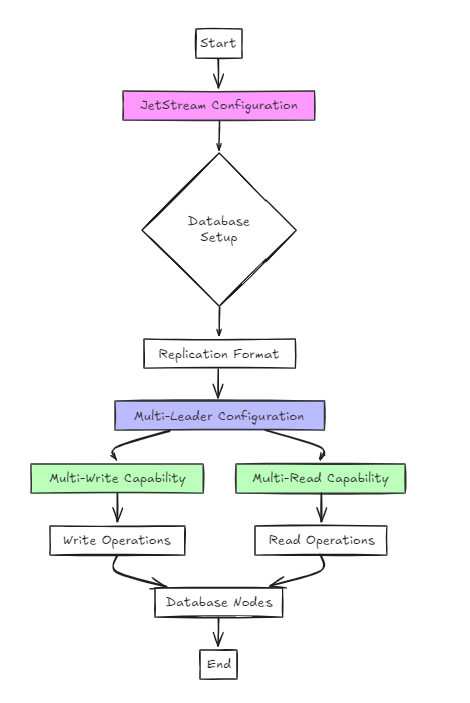
두 번째 접근법은 구성에 JetStream을 사용합니다.
이것은 이전 접근법보다 건축 적으로 단순하지만 사용자의 관점에서 설정은 RAFT와 크게 다르지 않습니다.
그러나 주요 차이점은 RAFT와 달리 단일 쓰기 및 다중 읽기보다는 다중 쓰기 및 다중 읽기 구성을 지원한다는 것입니다.
이 접근법에서 데이터베이스는 복제 형식으로 구성되며 JetStream은 다중 리더 구성을 활성화하는 데 사용됩니다.
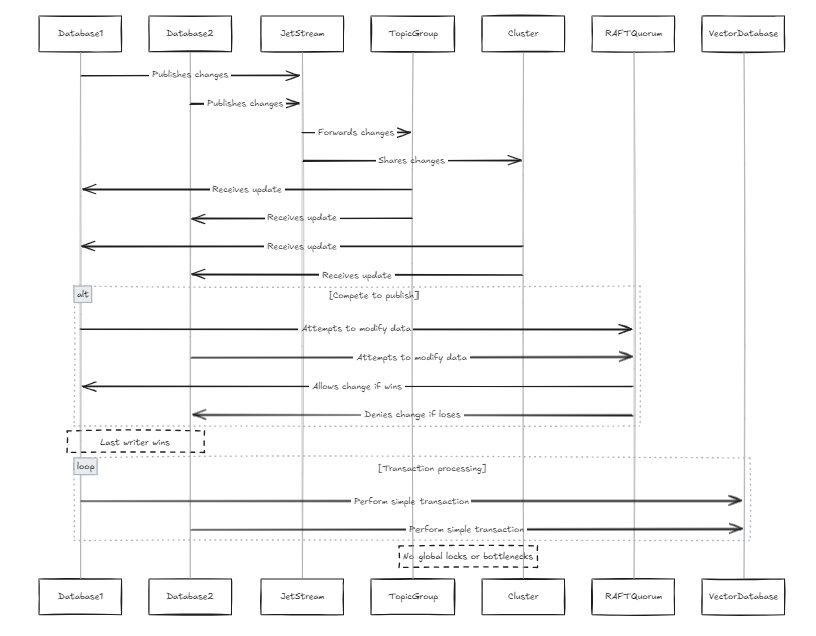 각 데이터베이스에는 자체 JetStream이 포함되어 있으며이 제트 스트림에는 동일한 주제 및 클러스터가 결합됩니다. 이 경우 모든 노드가 행에 변경 사항을 게시하려고 시도 할 때마다 동일한 제트 스트림을 통과합니다. 두 노드가 동일한 데이터를 병렬로 수정하려고하면 변경 사항을 게시하기 위해 경쟁합니다. 변화가 전파되는 것을 방지 할 수는 있지만, 이로 인해 데이터 손실이 발생할 수 있습니다. JetStream의 Raft Quorum 제약에 따르면, 한 작가만이 변경 사항을 게시 할 수 있습니다. 따라서 우리는 마지막 작가가 이길 수 있도록 시스템을 설계했습니다. 기존 데이터베이스와 비교하여 데이터 구조가 더 간단하기 때문에 벡터 데이터베이스의 문제는 아닙니다 (시스템 자체가 간단하다는 것을 의미하는 것이 아니라 트랜잭션 직렬화와 같은 복잡한 트랜잭션 및 절차가 적음을 의미합니다). 이것은 또한 글로벌 잠금 및 성능 병목 현상을 피합니다.
각 데이터베이스에는 자체 JetStream이 포함되어 있으며이 제트 스트림에는 동일한 주제 및 클러스터가 결합됩니다. 이 경우 모든 노드가 행에 변경 사항을 게시하려고 시도 할 때마다 동일한 제트 스트림을 통과합니다. 두 노드가 동일한 데이터를 병렬로 수정하려고하면 변경 사항을 게시하기 위해 경쟁합니다. 변화가 전파되는 것을 방지 할 수는 있지만, 이로 인해 데이터 손실이 발생할 수 있습니다. JetStream의 Raft Quorum 제약에 따르면, 한 작가만이 변경 사항을 게시 할 수 있습니다. 따라서 우리는 마지막 작가가 이길 수 있도록 시스템을 설계했습니다. 기존 데이터베이스와 비교하여 데이터 구조가 더 간단하기 때문에 벡터 데이터베이스의 문제는 아닙니다 (시스템 자체가 간단하다는 것을 의미하는 것이 아니라 트랜잭션 직렬화와 같은 복잡한 트랜잭션 및 절차가 적음을 의미합니다). 이것은 또한 글로벌 잠금 및 성능 병목 현상을 피합니다.
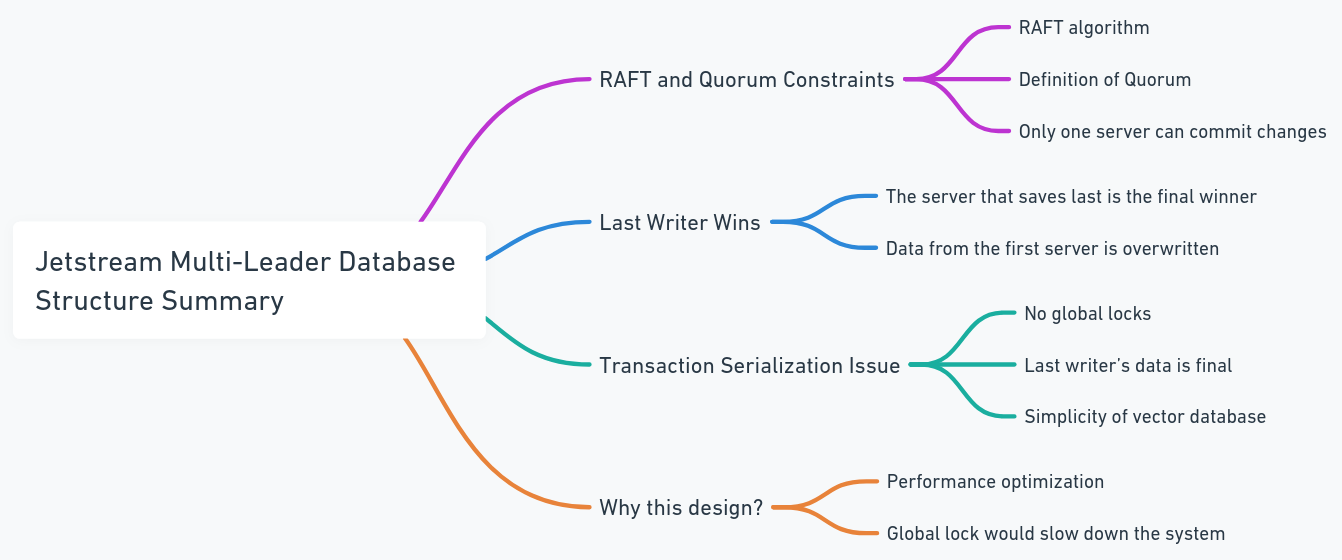
오래된 아키텍처를보십시오
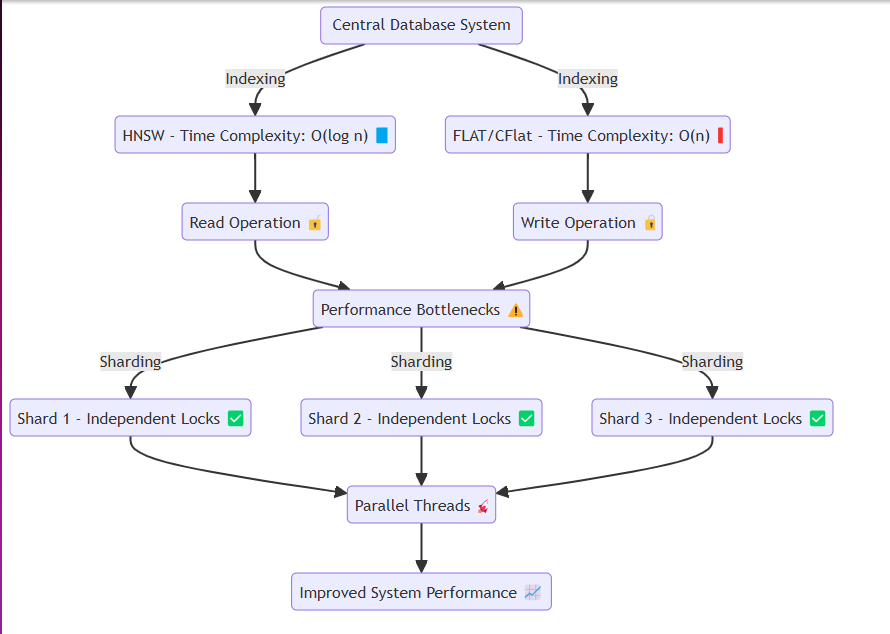 일반적으로 데이터베이스와 같은 시스템은 동일한 메모리 또는 디스크에 액세스하여 읽기 및 쓰기 작업을 반복적으로 수행합니다. 이 과정에서 HNSW와 같은 방법은 O (log n) 와 같은 효율적인 시간 복잡성을 달성 할 수 있습니다. 그러나, 플랫 및 CFLAT와 같은 정확도가 필요한 기술은 일반적으로 O (n) 의 시간 복잡성으로 선형 검색을 실행합니다.
일반적으로 데이터베이스와 같은 시스템은 동일한 메모리 또는 디스크에 액세스하여 읽기 및 쓰기 작업을 반복적으로 수행합니다. 이 과정에서 HNSW와 같은 방법은 O (log n) 와 같은 효율적인 시간 복잡성을 달성 할 수 있습니다. 그러나, 플랫 및 CFLAT와 같은 정확도가 필요한 기술은 일반적으로 O (n) 의 시간 복잡성으로 선형 검색을 실행합니다.
데이터 경합을 피할 때 문제가 발생합니다. 읽기 또는 쓰기시 Goroutines와 같은 스레드는 자물쇠를 통해 각 자원을 분리합니다. 구체적으로:
이를 해결하기 위해 시스템의 필수를 잃지 않고 메모리에 파편을 효율적으로 생성하고 각 샤드에 데이터를 할당하도록 시스템을 설계했습니다. 각 샤드에는 다음을 허용하는 잠금 장치가 있습니다.
더 빠른 잠금 해제 : 다량의 데이터를 삽입하거나 읽기 작업을 수행 할 때. 분할 된 데이터 삽입 : 데이터를 분할 된 세그먼트에 삽입 할 수 있도록하여 원활한 시스템 작업을 용이하게합니다. 이 디자인은 데이터 삽입이 많은 경우에도 시스템이 원활하게 작동 할 수 있도록하여 성능 병목 현상을 완화시킵니다.
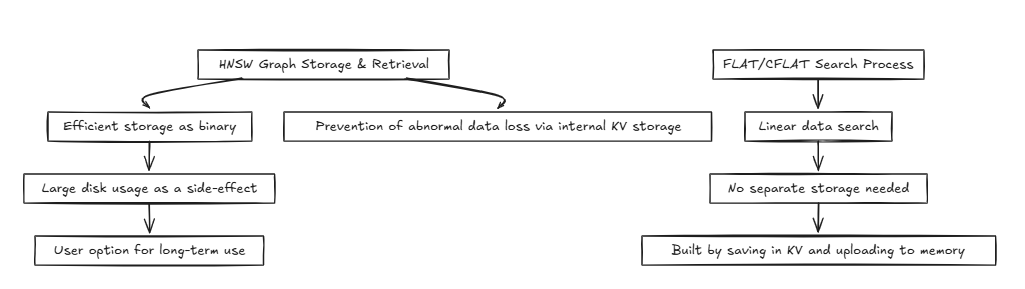
HNSW (계층 적 항해 가능한 작은 세계) :
플랫/cflat (합성 플랫) :
CFLAT (Composite Flat) 는 여러 벡터를 검색하고 두 벡터의 중요성에 따라 복합 결과를 생성하는 인덱싱 방법입니다.
HNSW와 같은 그래프 알고리즘에 복합 벡터 검색을 적용하는 것은 상당한 양의 메모리가 필요하고 이웃 구조와 잘 맞지 않기 때문에 여러 그래프가 필요하기 때문에 어려운 일입니다. 검색의 시간 복잡성은 여전히 O (2 log n) ≈ O (log n)로 수렴하지만 공간 복잡성은 상당히 열악합니다.
데이터의 양이 커짐에 따라 이러한 문제는 점점 더 문제가됩니다. 또한 그래프 구조 내 복합 키를 기반으로 병합 및 평가 방법은 TOPK를 무시하고 단일 검색의 힙 크기를 크게 증가시킵니다.
따라서 우리는 플랫을 기반으로 처리하기로 결정했습니다. 시간 복잡성은 O (N) (일정한 방울없이)이지만 공간 복잡성은 평평한 상태로 유지되며 복합 키를 기반으로 병합 및 평가에 매우 효과적입니다.
Magine 우리는 입력 기준에 따라 사용자가 이상적인 파트너를 찾는 데 도움이되는 중매 회사를위한 서비스를 개발하고 있습니다. 우리는 성격 및 기타 속성과 같은 다양한 요소를 고려할 것입니다. 그러나 단일 벡터를 사용한다는 것은 이러한 요소를 검색을 위해 하나의 문장으로 결합하는 것을 의미하며, 이는 정확도 왜곡 가능성이 크게 증가합니다.
예를 들어: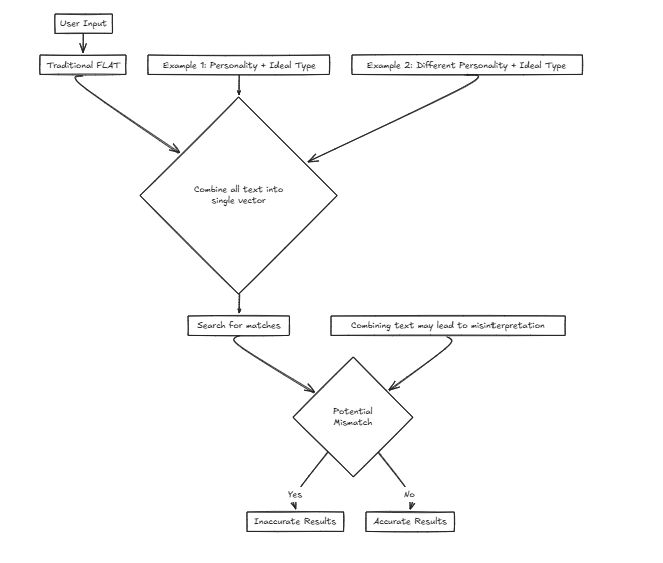 원하는 특성 : {성격 : 결정적, 이상적인 유형 : 키가 크고 슬림} 이 시나리오에서 사용자는 외부 속성을 기반으로 파트너를 찾는 데 중점을 둔 이상적인 유형을 이해할 수있는 이상적인 유형을 선호합니다.
원하는 특성 : {성격 : 결정적, 이상적인 유형 : 키가 크고 슬림} 이 시나리오에서 사용자는 외부 속성을 기반으로 파트너를 찾는 데 중점을 둔 이상적인 유형을 이해할 수있는 이상적인 유형을 선호합니다.
그러나 또 다른 사례를 고려하십시오.
원하는 특성 : {성격 : 쉬운, 이상적인 유형 : 결정적} 여기에서, 결정적인 이상적인 유형과 짝을 이루는 쉬운 성격을 원하는 사람은 사용자의 진정한 선호도와 일치하지 않는 방식으로 결정적인 개인과 일치하는 등 부정확 한 일치를 초래할 수 있습니다.
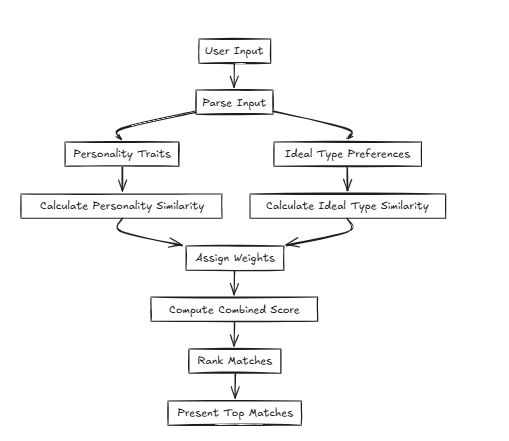 이러한 경우 CFLAT (Composite Flat)는 개성의 유사성과 이상적인 유형의 유사성을 공동으로 평가하여 점수를 계산합니다. 사용자는 각 속성에 중요도 레벨을 할당 할 수 있으므로 사용자 정의 우선 순위에 따라 더 큰 유사성을 가진 측면에 더 높은 점수를 제공 할 수 있습니다.
이러한 경우 CFLAT (Composite Flat)는 개성의 유사성과 이상적인 유형의 유사성을 공동으로 평가하여 점수를 계산합니다. 사용자는 각 속성에 중요도 레벨을 할당 할 수 있으므로 사용자 정의 우선 순위에 따라 더 큰 유사성을 가진 측면에 더 높은 점수를 제공 할 수 있습니다.
Edge는 중앙 서버와 통신하지 않고 인근 장치에서 데이터를 전송하고받는 기능을 나타냅니다. 그러나 실제로 소프트웨어의 "Edge"는 종종 중앙 서버에 비해 더 가볍고 자원으로 제한되는 환경에 배치되기 때문에이 개념과 다를 수 있습니다.
NNV-Edge는 소규모 스케일 벡터 데이터 세트 (최대 1 백만 벡터)에서 가벼운 방식으로 빠르게 작동하도록 설계되어 원래 NNV에서 자동화 된 작업을 사용자에게 더 큰 제어 할 수 있도록 전송합니다.
HNSW, FAISS 및 짜증과 같은 고급 알고리즘은 훌륭하지만 소규모 사양에 대해서는 약간 무거울 수 있다고 생각하지 않습니까? Milvus, Weaviate 및 Qdrant와 같은 프로젝트가 화려한 마음으로 구축되는 동안 알고리즘을 제외하고는 작은 휴대용 장치에서 다른 소프트웨어와 함께 실행하기에는 너무 자원 집약적이지 않습니까?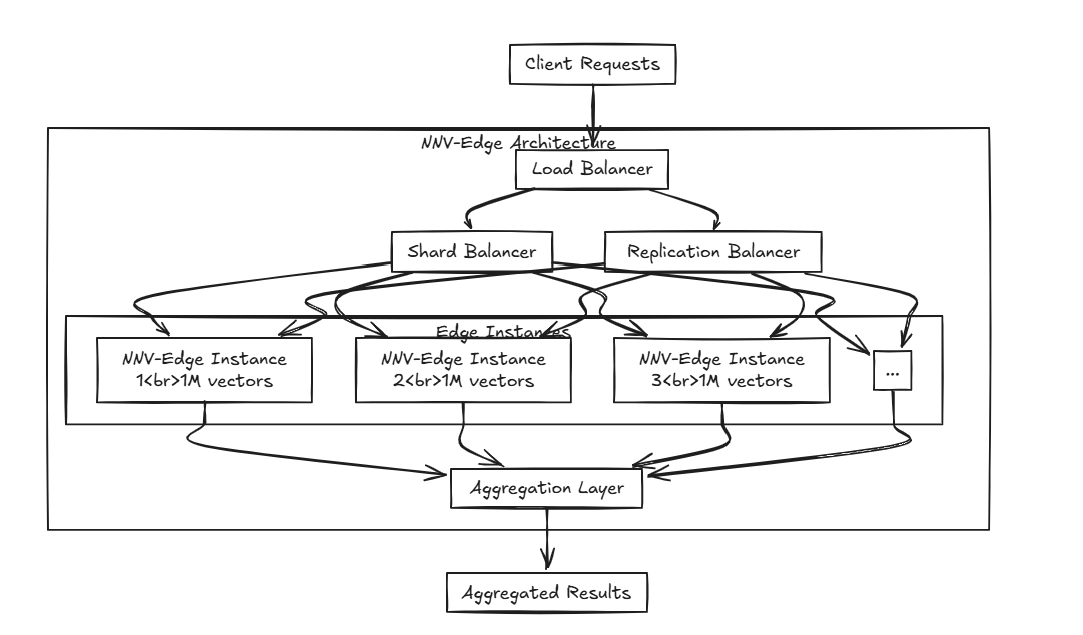 그것이 NNV-Edge가 들어오는 곳입니다.
그것이 NNV-Edge가 들어오는 곳입니다.
여러 모서리를 배포하면 어떻게됩니까? 이전에 언급 된로드 밸런서와 함께 NNV-Edge를 사용하면 여러 모서리에 걸쳐 데이터를 삭제하고 원활하게 집계하는 고급 설정을 만들 수 있습니다!


