nnv
1.0.0

NNV (No-Named.V) ist eine Datenbank, die von Grund auf Produktion implementiert werden soll. NNV kann in Kantenumgebungen eingesetzt und in kleinen Produktionsumgebungen verwendet werden. Durch den nachstehend beschriebenen innovativen architektonischen Ansatz ist er vorgesehen und entwickelt, um auch in großflächigen Produktionsumgebungen zuverlässig eingesetzt zu werden.
Weitere Informationen finden Sie in Update History.
Wir planen, CFLAT zu unterstützen, was verschiedene Dienste durch komplexere Operationen erleichtern kann, die Multi-Vektor-Suchvorgänge ermöglichen. CFLAT ist nur ein Name, den ich geprägt habe. Bitte beachten Sie!
Die Leistung kann aufgrund einer laufenden Entwicklung vorübergehend reduziert werden. Vielen Dank für Ihre Geduld!
Windows & Linux
git clone https://github.com/sjy-dv/nnv
cd nnv
# start edge
go run cmd/root/main.go -mode=edge
# start core
go run cmd/root/main.go -mode=root
MacOS
** The CPU acceleration (SSE, AVX2, AVX-512) code has caused an error where it does not function on Mac, and it is not a priority to address at this time. **
git clone https://github.com/sjy-dv/nnv
cd nnv
source .env
deploy
make edge-dockerMerkmale
ARCHITEKTUR
Bugfix
Bei der Planung dieses Projekts habe ich mir viel darüber nachgedacht.
Bei der Einrichtung der Cluster -Umgebung ist es für die meisten Entwickler natürlich, den Raft -Algorithmus zu wählen, wie ich es immer zuvor getan habe. Der Grund dafür ist, dass es sich um einen bewährten Ansatz handelt, der von erfolgreichen Projekten verwendet wird.
Ich habe mich jedoch gefragt: Ist es nicht ein bisschen komplex? RAFT erhöht die Verfügbarkeit von Lesen, verringert jedoch die Verfügbarkeit der Schreibweise. Wie würde ich das lösen, wenn Multi-Write auf lange Sicht notwendig wird?
Angesichts der Art der Vektordatenbanken nahm ich an, dass die meisten Dienste eher auf Batch-Jobs als in Echtzeit schreiben würden. Aber bedeutet das, dass ich einfach überspringen kann, um das Problem anzugehen? Ich habe das nicht gedacht. Der Bau eines Multi-Leader-Setups auf Floß mit etwas wie Klatsch war jedoch äußerst komplex und schwierig. 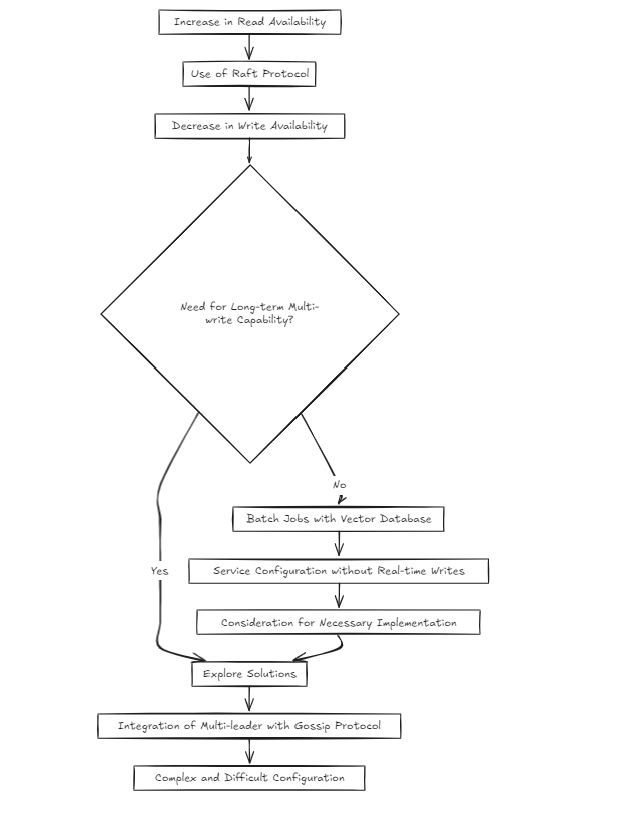
Daher erwähne ich bis heute (2024-10-20) zwei architektonische Ansätze.
Die Architektur ist in zwei Ansätze unterteilt.
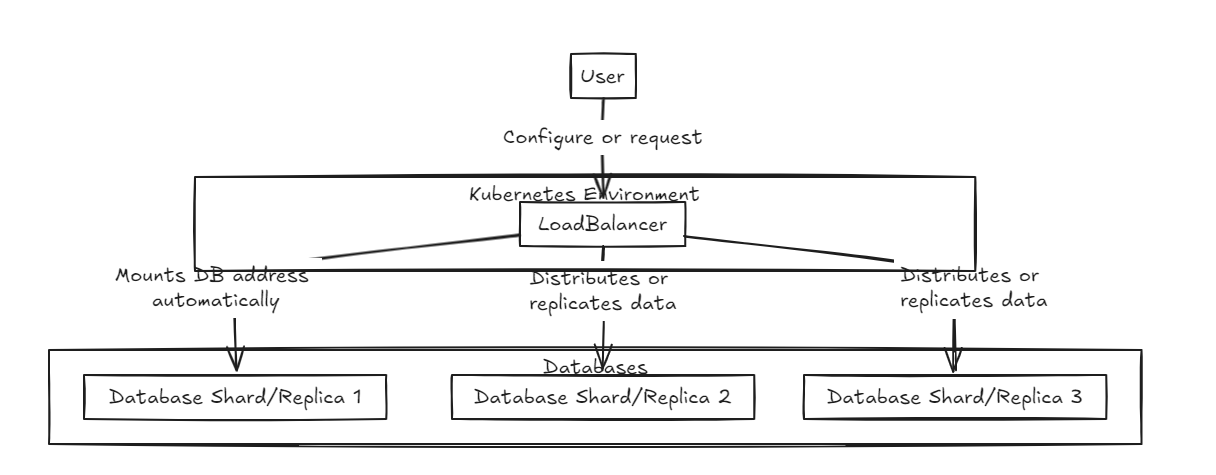
Zunächst wird vorne ein Lastausgleich platziert, wodurch sowohl die Sharding als auch die Integration der Daten unterstützt werden. Die interne Datenbank existiert in einem reinen Zustand.
 |  |
|---|---|
| Replik lb | Shard lb |
Der Replikations -Last -Balancer wartet darauf, dass alle Datenbanken geschriebene Schreibvorgänge erfolgreich abschließen, bevor er sich verpflichtet oder zurückrollt, während der Shard -Last -Balancer die Last gleichmäßig über die Shard -Datenbanken verteilt, um ähnliche Speicherkapazitäten zu gewährleisten.
Der Hauptunterschied besteht darin, dass die Replikation Schreibvorgänge verlangsamen kann, aber im Vergleich zum Shard -Last -Balancer eine schnellere Leseleistung im Medium bis langfristig liefert. Andererseits bietet der Shard -Ansatz schnellere Schreibgeschwindigkeiten, da er nur zu einem bestimmten Shard verpflichtet ist. Das Lesen erfordert jedoch das Sammeln von Daten aus allen Scherben, was anfangs langsamer ist, aber schneller werden kann als die Replikation, wenn der Datensatz wächst.
Für die Verwaltung großer Datenmengen ist der Shard Balancer daher etwas mehr empfohlen. Der Hauptpunkt beider Architekturen ist jedoch ihre Einfachheit in der Einrichtung und des Managements, sodass sie als typischer Backend -Server so einfach zu handhaben. 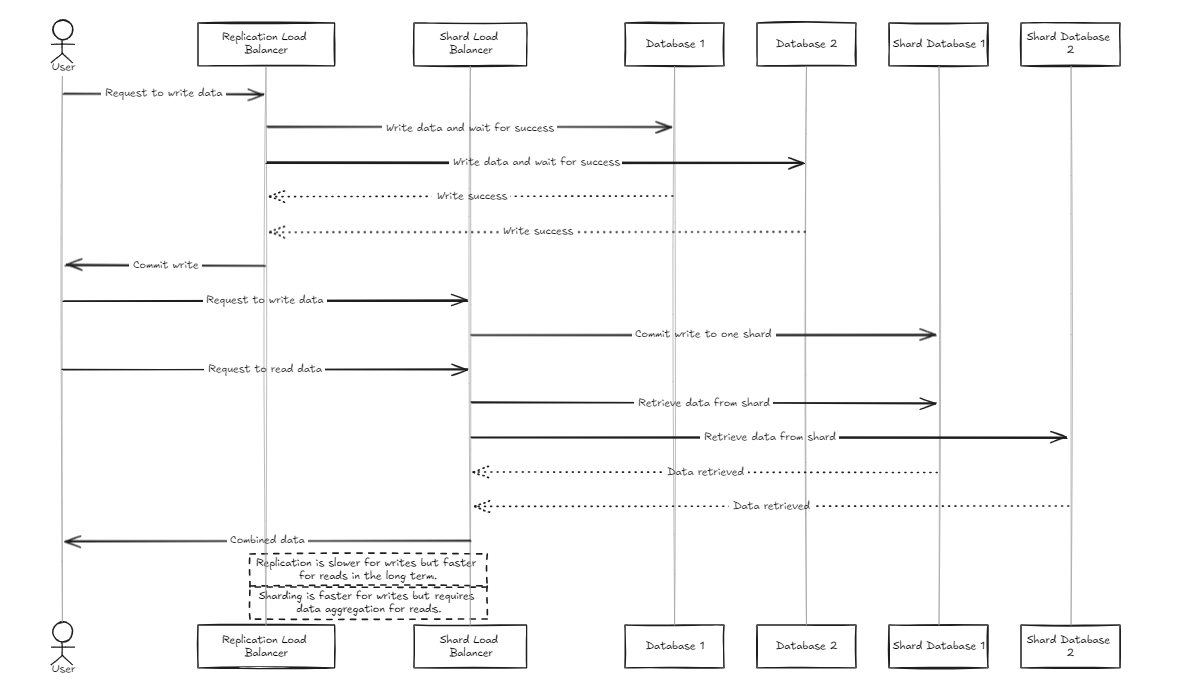
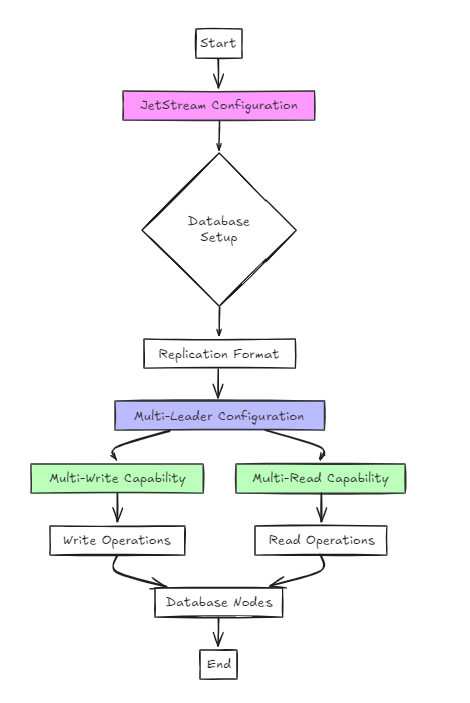
Der zweite Ansatz verwendet Jetstream für die Konfiguration.
Während dies architektonisch einfacher ist als der vorherige Ansatz, unterscheidet sich das Setup aus Sicht des Benutzers nicht wesentlich von Raft.
Der wichtigste Unterschied besteht jedoch darin, dass es im Gegensatz zu Raft mehrschreiber und mehrschichtige Konfigurationen anstelle von Einzelschreiber und Mehrfachlesen unterstützt.
In diesem Ansatz ist die Datenbank in einem Replikationsformat konfiguriert, und Jetstream wird verwendet, um Multi-Leader-Konfigurationen zu ermöglichen.
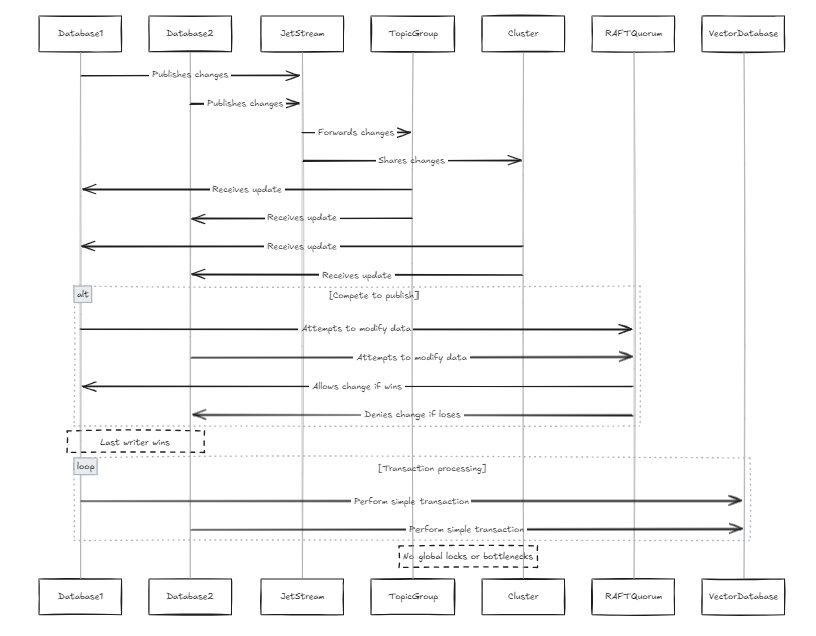 Jede Datenbank enthält ihren eigenen Jetstream, und diese Jetstreams beitreten derselben Gruppe von Themen und Clustern. In diesem Fall, wenn alle Knoten versuchen, Änderungen in einer Zeile zu veröffentlichen, gehen sie durch denselben Jetstream. Wenn zwei Knoten versuchen, dieselben Daten parallel zu ändern, konkurrieren sie um ihre Änderungen. Es ist zwar möglich, zu verhindern, dass Änderungen vermehrt werden, dies könnte zu einem Datenverlust führen. Nach der Raft -Quorum -Einschränkung in Jetstream kann nur ein Schriftsteller die Änderung veröffentlichen. Daher haben wir das System so gestaltet, dass der letzte Schriftsteller gewinnen kann. Dies ist kein Problem für Vektordatenbanken, da die Datenstruktur im Vergleich zu herkömmlichen Datenbanken einfacher ist (dies bedeutet nicht, dass das System selbst einfach ist, sondern dass es weniger komplexe Transaktionen und Verfahren gibt, wie z. B. Serialisierung der Transaktion). Dies vermeidet auch globale Schlösser und Leistungs Engpässe.
Jede Datenbank enthält ihren eigenen Jetstream, und diese Jetstreams beitreten derselben Gruppe von Themen und Clustern. In diesem Fall, wenn alle Knoten versuchen, Änderungen in einer Zeile zu veröffentlichen, gehen sie durch denselben Jetstream. Wenn zwei Knoten versuchen, dieselben Daten parallel zu ändern, konkurrieren sie um ihre Änderungen. Es ist zwar möglich, zu verhindern, dass Änderungen vermehrt werden, dies könnte zu einem Datenverlust führen. Nach der Raft -Quorum -Einschränkung in Jetstream kann nur ein Schriftsteller die Änderung veröffentlichen. Daher haben wir das System so gestaltet, dass der letzte Schriftsteller gewinnen kann. Dies ist kein Problem für Vektordatenbanken, da die Datenstruktur im Vergleich zu herkömmlichen Datenbanken einfacher ist (dies bedeutet nicht, dass das System selbst einfach ist, sondern dass es weniger komplexe Transaktionen und Verfahren gibt, wie z. B. Serialisierung der Transaktion). Dies vermeidet auch globale Schlösser und Leistungs Engpässe.
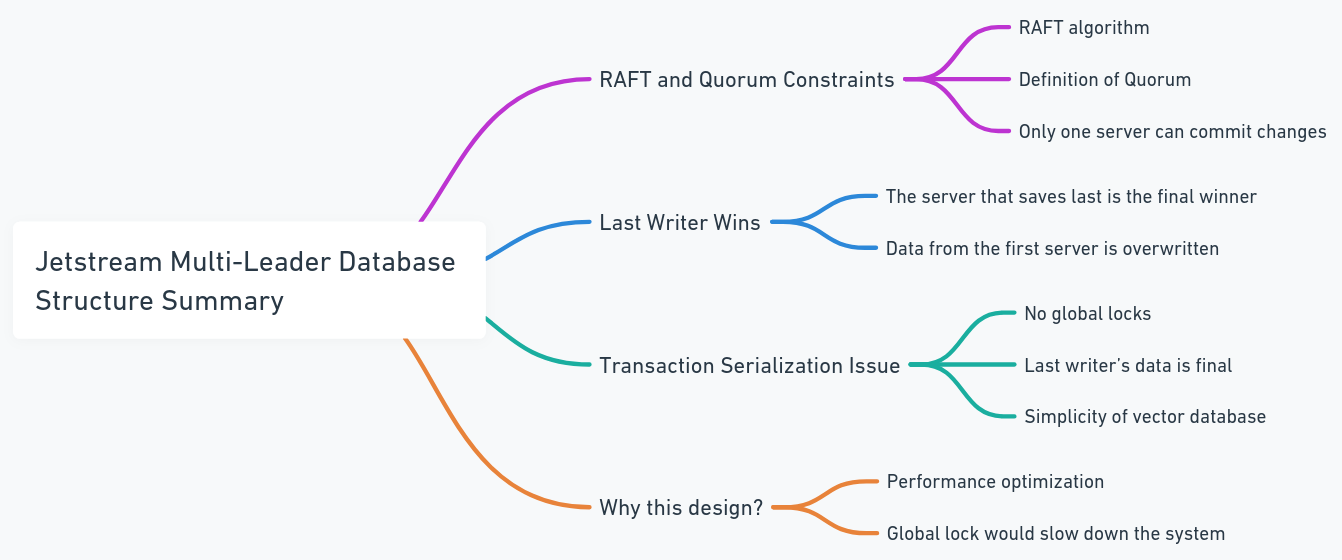
Alte Architektur anzeigen
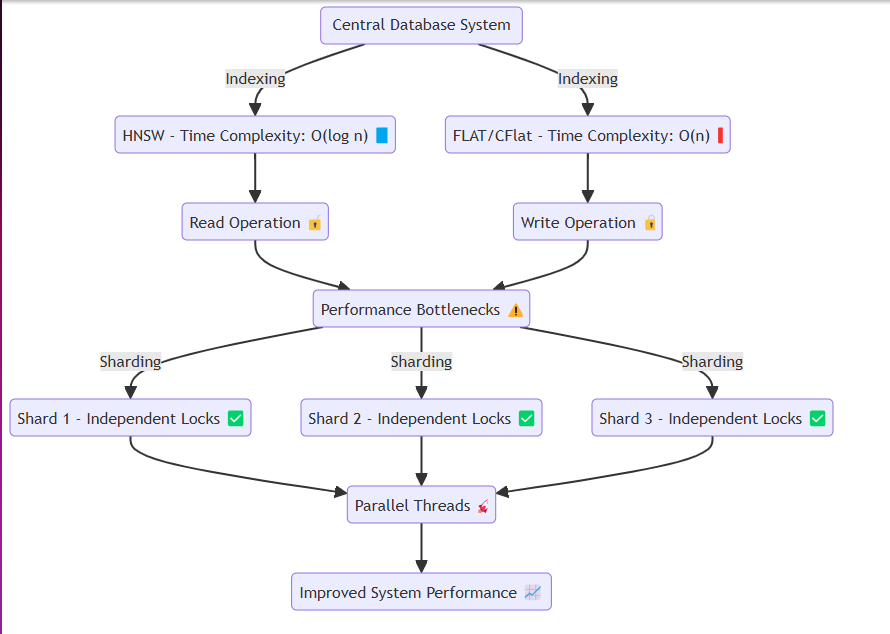 In der Regel greifen Systeme wie Datenbanken auf denselben Speicher oder die gleiche Festplatte zu und führen wiederholt Lese- und Schreibvorgänge durch. In diesem Prozess können Methoden wie HNSW effiziente zeitliche Komplexität wie O (log n) erreichen. Techniken, die Genauigkeit wie flach und cflat erfordern, führen jedoch im Allgemeinen lineare Suchvorgänge mit einer zeitlichen Komplexität von O (n) durch.
In der Regel greifen Systeme wie Datenbanken auf denselben Speicher oder die gleiche Festplatte zu und führen wiederholt Lese- und Schreibvorgänge durch. In diesem Prozess können Methoden wie HNSW effiziente zeitliche Komplexität wie O (log n) erreichen. Techniken, die Genauigkeit wie flach und cflat erfordern, führen jedoch im Allgemeinen lineare Suchvorgänge mit einer zeitlichen Komplexität von O (n) durch.
Das Problem tritt bei der Vermeidung von Datenkonflikten auf. Beim Lesen oder Schreiben isolieren Themen wie Goroutines die jeweiligen Ressourcen durch Schlösser. Speziell:
Um dies zu beheben, haben wir das System so gestaltet, dass wir effizient Scharden im Speicher erstellen und jedem Shard Daten zuweisen, ohne die Essenz des Systems zu verlieren. Jeder Shard verfügt über einen Verriegelungsmechanismus, der es ermöglicht:
Schnellere Sperrfreigabe : Beim Einsetzen großer Datenmengen oder der Durchführung von Lesevorgängen. Partitionierte Dateninsertion : Erleichterung der reibungslosen Systemvorgänge, indem Daten in geteilte Segmente eingefügt werden können. Dieses Design stellt sicher, dass das System auch unter schweren Dateneinfügungen oder hohen Szenarien für Anforderungen nahtlos arbeiten kann, wodurch die Leistungs Engpässe gemindert werden.
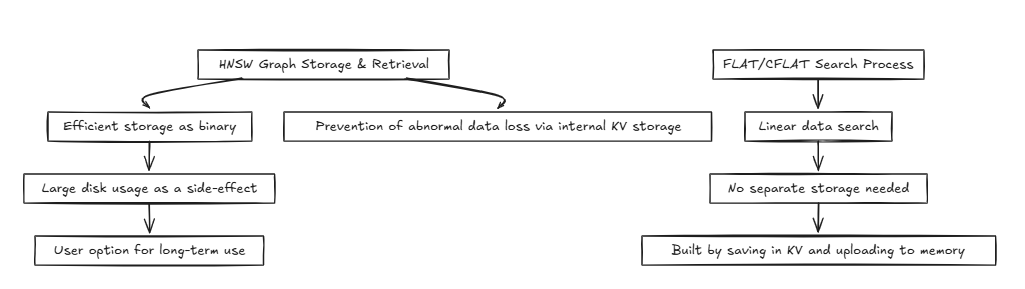
HNSW (hierarchische schiffbare kleine Welt):
Flach/cflat (zusammengesetzter flach):
CFLAT (Composite Flat) ist eine Indizierungsmethode, die mehrere Vektoren durchsucht und zusammengesetzte Ergebnisse basierend auf der Bedeutung von zwei Vektoren erzeugt.
Die Anwendung der zusammengesetzten Vektorsuche auf Graph -Algorithmen wie HNSW ist eine Herausforderung, da sie eine erhebliche Menge an Speicher erfordert und nicht gut mit Nachbarschaftsstrukturen übereinstimmt, was mehrere Grafiken erfordert. Obwohl die Zeitkomplexität für die Suche immer noch zu O (2 log n) ≈ O (log n) konvergiert, ist die Raumkomplexität erheblich schlecht.
Diese Probleme werden mit zunehmendem Datenmengen immer problematischer. Darüber hinaus ignoriert die Verschmelzung und Bewertung auf der Grundlage von zusammengesetzten Schlüssel innerhalb der Graph -Struktur TOPK und erhöht die Haufengröße für eine einzelne Suche signifikant.
Daher haben wir uns für die Verarbeitung auf der Basis von Flat entschieden. Obwohl die zeitliche Komplexität O (n) ist (ohne konstante Tropfen), bleibt die Raumkomplexität die gleiche wie flach und ist hochwirksam für das Zusammenführen und Bewertung auf der Grundlage von Verbundtasten.
MAGINE Wir entwickeln einen Dienst für ein Matchmaking -Unternehmen, das Benutzern hilft, ihre idealen Partner auf der Grundlage von Input -Kriterien zu finden. Wir werden verschiedene Faktoren wie Persönlichkeit und andere Attribute in Betracht ziehen. Die Verwendung eines einzelnen Vektors bedeutet jedoch, diese Faktoren zu einem Satz für die Suche zu kombinieren, was die Wahrscheinlichkeit einer Genauigkeitsverzerrung erheblich erhöht.
Zum Beispiel: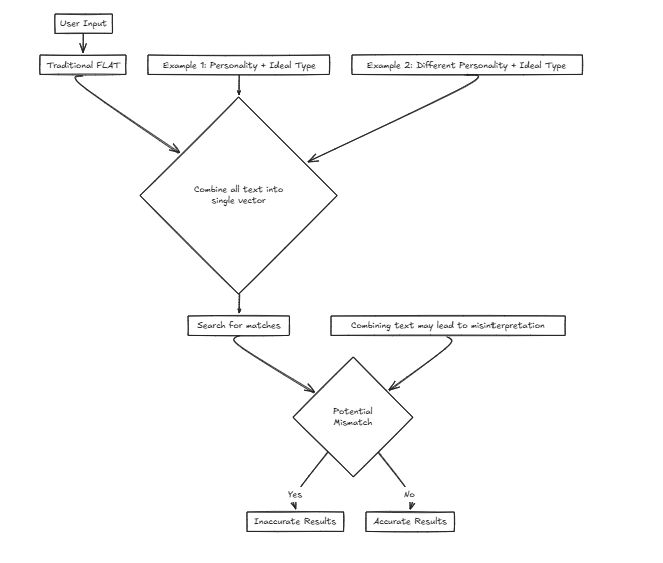 Wünschte Merkmale: {Persönlichkeit: Entschlossen, idealer Typ: groß und schlank} In diesem Szenario bevorzugt der Benutzer ein Persönlichkeitsmerkmal, der den idealen Typ macht, der sie wahrscheinlich schätzt und sich darauf konzentriert, einen Partner basierend auf externen Attributen zu finden.
Wünschte Merkmale: {Persönlichkeit: Entschlossen, idealer Typ: groß und schlank} In diesem Szenario bevorzugt der Benutzer ein Persönlichkeitsmerkmal, der den idealen Typ macht, der sie wahrscheinlich schätzt und sich darauf konzentriert, einen Partner basierend auf externen Attributen zu finden.
Betrachten Sie jedoch einen anderen Fall:
Wünschte Merkmale: {Persönlichkeit: Locker, idealer Typ: Entscheidend} Hier kann jemand, der eine lockere Persönlichkeit mit einem entscheidenden Ideal -Typ gepaart hat, zu falschen Übereinstimmungen führen, z.
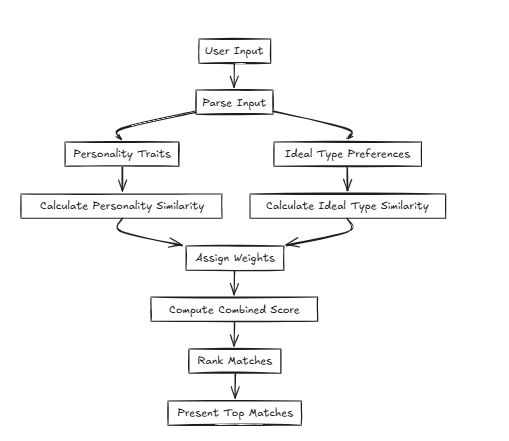 In solchen Fällen berechnet CFLAT (Composite Flat) die Bewertungen, indem die Ähnlichkeit der Persönlichkeit und die Ähnlichkeit des idealen Typs gemeinsam bewertet wird. Benutzer können jedem Attribut Bedeutung zuweisen, sodass die Aspekte mit größerer Ähnlichkeit auf der Grundlage benutzerdefinierter Prioritäten höhere Ergebnisse vergeben können.
In solchen Fällen berechnet CFLAT (Composite Flat) die Bewertungen, indem die Ähnlichkeit der Persönlichkeit und die Ähnlichkeit des idealen Typs gemeinsam bewertet wird. Benutzer können jedem Attribut Bedeutung zuweisen, sodass die Aspekte mit größerer Ähnlichkeit auf der Grundlage benutzerdefinierter Prioritäten höhere Ergebnisse vergeben können.
Edge bezieht sich auf die Fähigkeit, Daten auf nahe gelegenen Geräten ohne Kommunikation mit einem zentralen Server zu übertragen und zu empfangen. In der Praxis kann "Edge" in der Software jedoch manchmal von diesem Konzept abweichen, da es häufig in leichteren, ressourcenbezogenen Umgebungen im Vergleich zu einem zentralen Server eingesetzt wird.
NNV-Edge ist so konzipiert, dass sie in leichten Weise in kleineren Vektor-Datensätzen (bis zu 1 Million Vektoren) schnell betrieben werden und automatisierte Aufgaben vom ursprünglichen NNV zurück an den Benutzer übertragen werden, um eine größere Kontrolle zu erhalten.
Erweiterte Algorithmen wie HNSW, Faiss und Ärger sind ausgezeichnet, aber glauben Sie nicht, dass sie für kleinere Spezifikationen etwas schwer sind? Und wenn sie Algorithmen beiseite lassen, während Projekte wie Milvus, Weaviate und Qdrant von brillanten Köpfen aufgebaut werden, sind sie nicht zu ressourcenintensiv, um neben anderen Software auf kleinen, tragbaren Geräten zu laufen?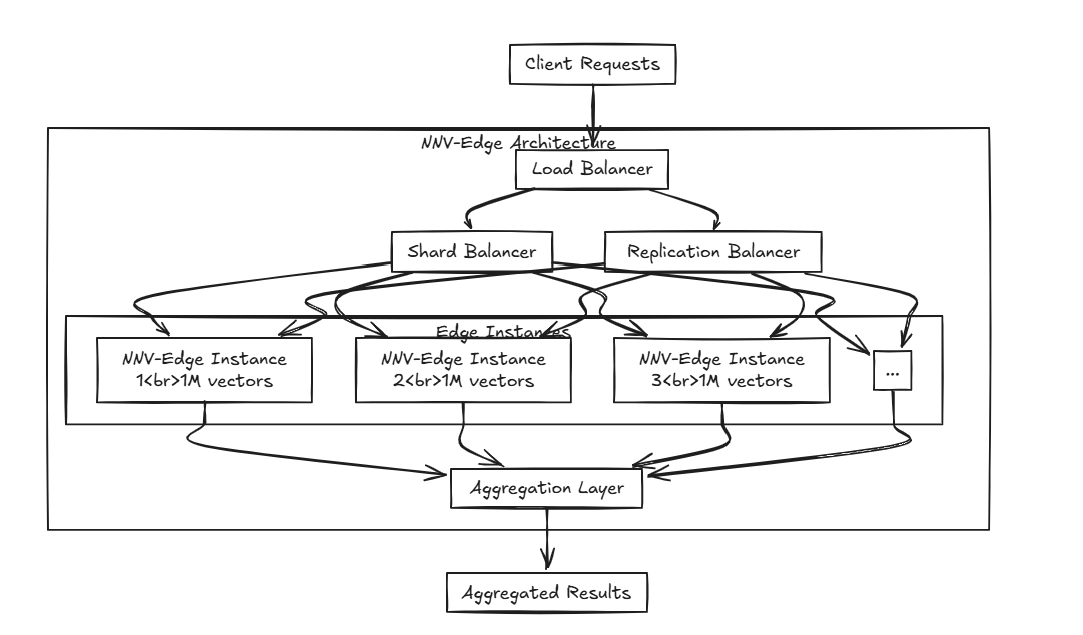 Hier kommt NNV-Edge ins Spiel.
Hier kommt NNV-Edge ins Spiel.
Was ist, wenn Sie mehrere Kanten verteilen? Durch die Verwendung von NNV-Edge mit dem zuvor erwähnten Last-Balancer können Sie ein erweitertes Setup erstellen, das Daten an mehreren Kanten über mehrere Kanten leitet und es nahtlos aggregiert!


