nnv
1.0.0

NNV(No-Named.V)は、ゼロから生産まで実装するように設計されたデータベースです。 NNVは、エッジ環境で展開し、小規模な生産設定で使用できます。以下で説明する革新的な建築的アプローチを通じて、大規模な生産環境でも確実に使用されるように想定され開発されています。
完全な更新履歴については、更新履歴を参照してください。
CFLATをサポートする予定です。CFLATは、マルチベクトル検索を可能にするより複雑な操作を通じてさまざまなサービスを促進できます。 CFLATは、私が造った単なる名前です。注意してください!
進行中の開発により、パフォーマンスが一時的に低下する場合があります。忍耐をありがとう!
Windows & Linux
git clone https://github.com/sjy-dv/nnv
cd nnv
# start edge
go run cmd/root/main.go -mode=edge
# start core
go run cmd/root/main.go -mode=root
MacOS
** The CPU acceleration (SSE, AVX2, AVX-512) code has caused an error where it does not function on Mac, and it is not a priority to address at this time. **
git clone https://github.com/sjy-dv/nnv
cd nnv
source .env
deploy
make edge-docker特徴
建築
bugfix
このプロジェクトを計画するとき、私はそれに多くの考えを与えました。
クラスター環境をセットアップするとき、私が以前に行ったように、ほとんどの開発者がRAFTアルゴリズムを選択するのは自然です。その理由は、それが成功したプロジェクトで使用される実証済みのアプローチであるためです。
しかし、私は疑問に思い始めました:それは少し複雑ではありませんか?ラフトは読み取りの可用性を増加させますが、書き込みの可用性を低下させます。それでは、長期的にマルチライトが必要になった場合、これをどのように解決しますか?
Vectorデータベースの性質を考えると、ほとんどのサービスは、リアルタイムのライティングではなく、バッチジョブを中心に構成されると思いました。しかし、それは私が問題に対処するだけでスキップできるということですか?私はそうは思いませんでした。しかし、ゴシップのようなものを使用して、ラフトの上にマルチリーダーのセットアップを構築することは、非常に複雑で困難に感じられました。 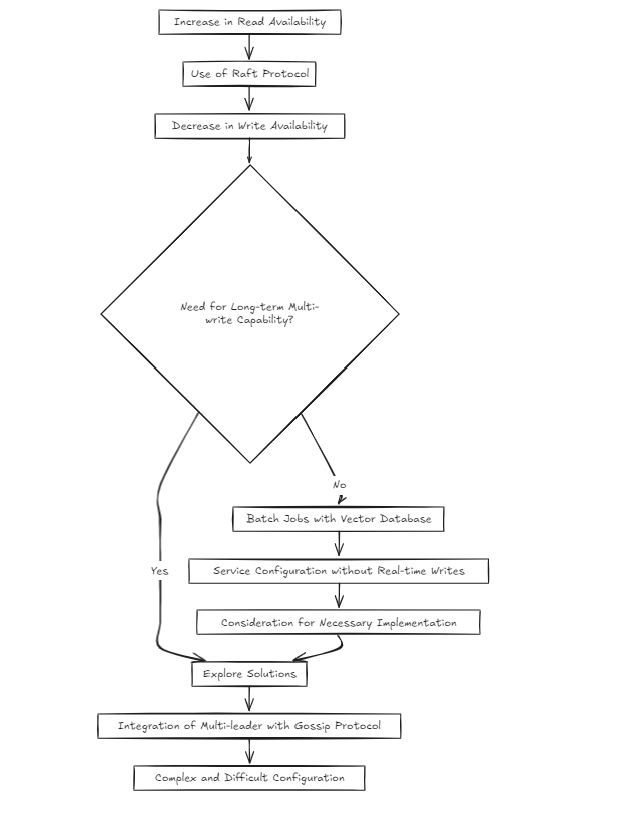
したがって、今日(2024-10-20)の時点で、私は2つの建築的アプローチを検討しています。
アーキテクチャは2つのアプローチに分かれています。
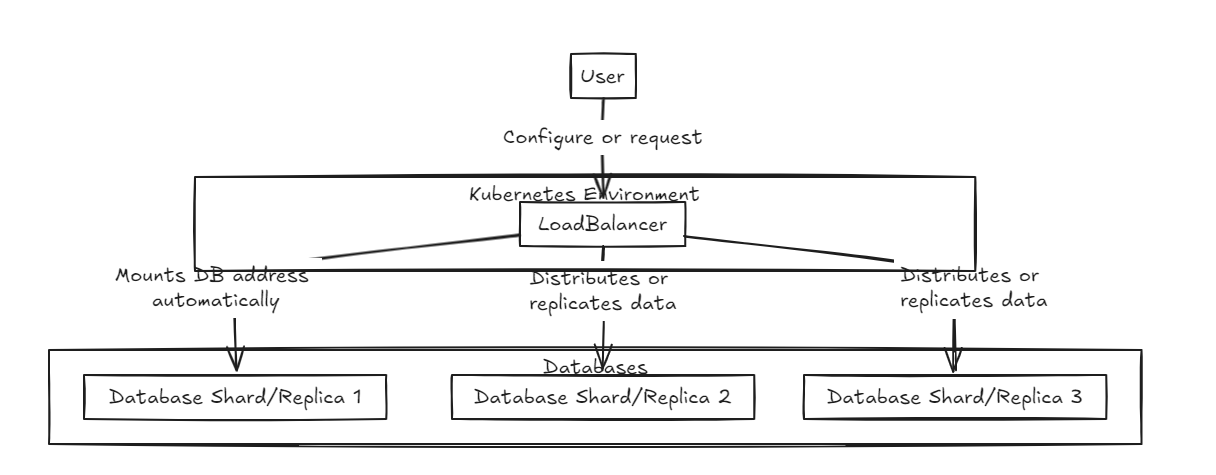
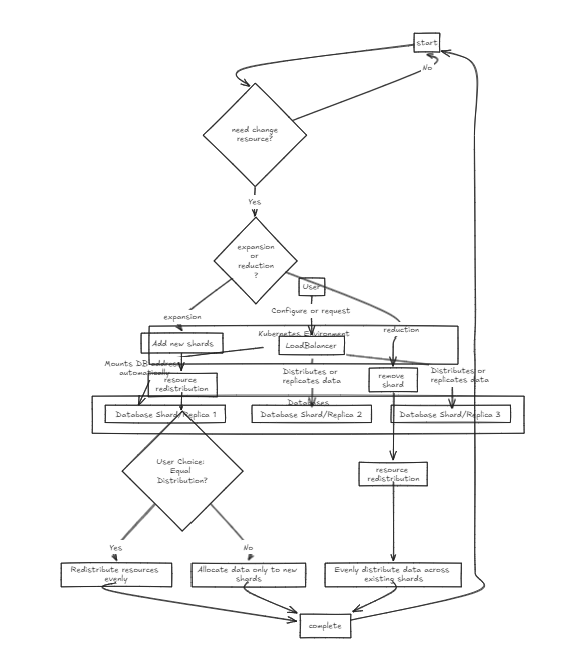
まず、ロードバランサーが正面に配置され、データのシャードと統合の両方をサポートします。内部データベースは純粋な状態に存在します。
 |  |
|---|---|
| レプリカLB | シャードlb |
レプリケーションロードバランサーは、すべてのデータベースがコミットまたはロールバックする前に正常に記入するのを待ちますが、シャードロードバランサーはシャードデータベースに均等にロードを配布して、同様のストレージ容量を確保します。
重要な違いは、複製が書き込み操作を遅くすることができるが、シャードロードバランサーと比較して中期における読み取りパフォーマンスを高速で提供することです。一方、シャードアプローチは特定のシャードにのみコミットするため、より高速な書き込み速度を提供しますが、読み取りではすべてのシャードからデータを収集する必要があります。
したがって、大量のデータを管理するために、シャードバランサーは少し推奨されます。ただし、両方のアーキテクチャの主なポイントは、セットアップと管理のシンプルさであり、典型的なバックエンドサーバーと同じくらい簡単に処理できるようにすることです。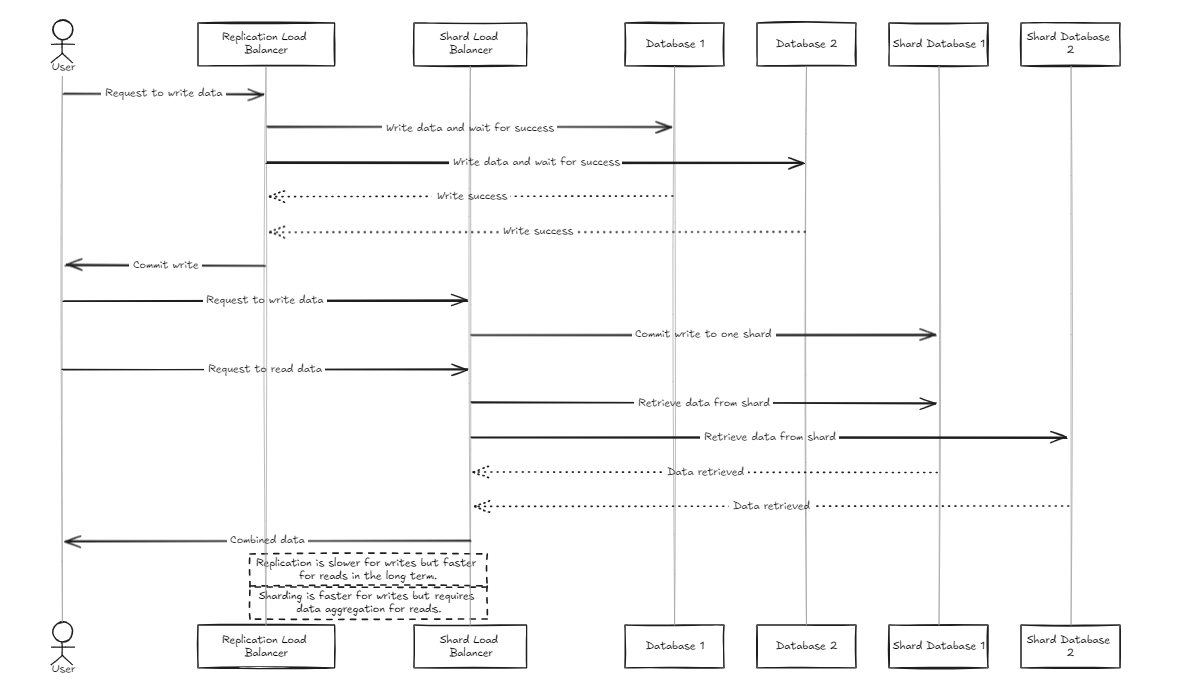
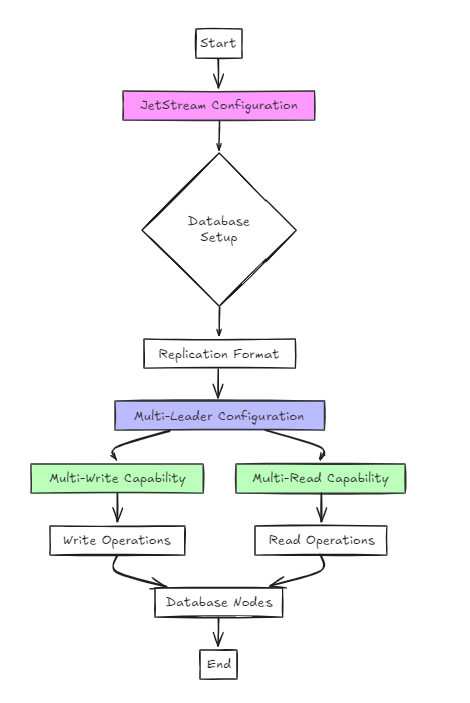
2番目のアプローチでは、構成にJetStreamを使用します。
これは以前のアプローチよりも建築的にシンプルですが、ユーザーの観点からは、セットアップはRAFTとは大きく違いはありません。
ただし、主な違いは、RAFTとは異なり、単一ライターやマルチリードではなく、マルチライターおよびマルチリード構成をサポートすることです。
このアプローチでは、データベースは複製形式で構成され、JetStreamはマルチリーダーの構成を有効にするために使用されます。
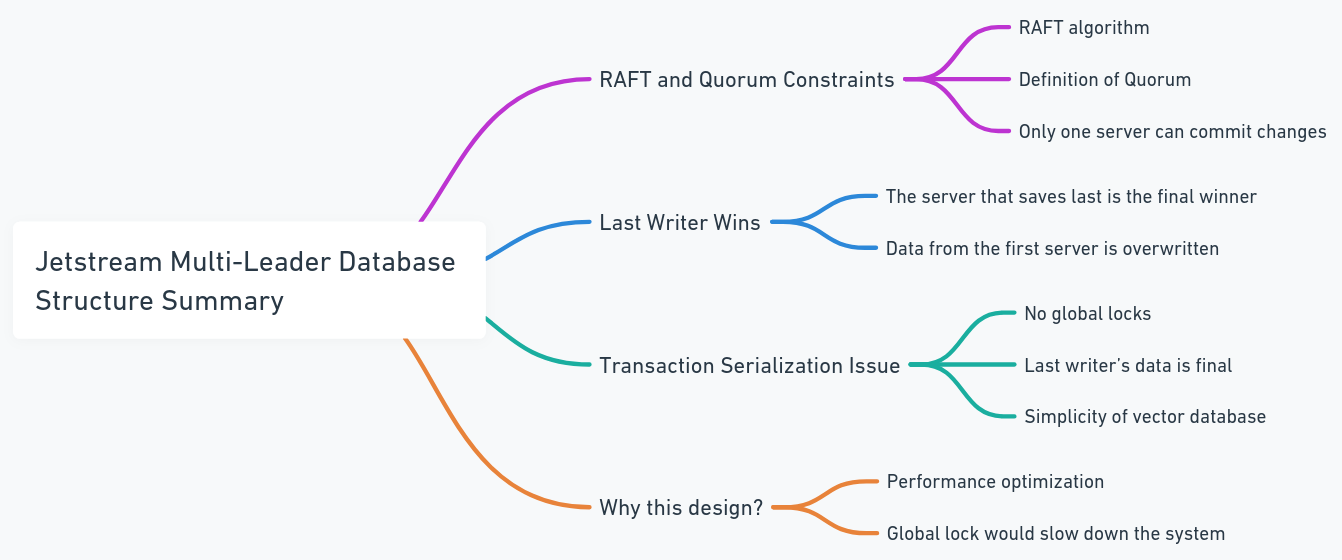
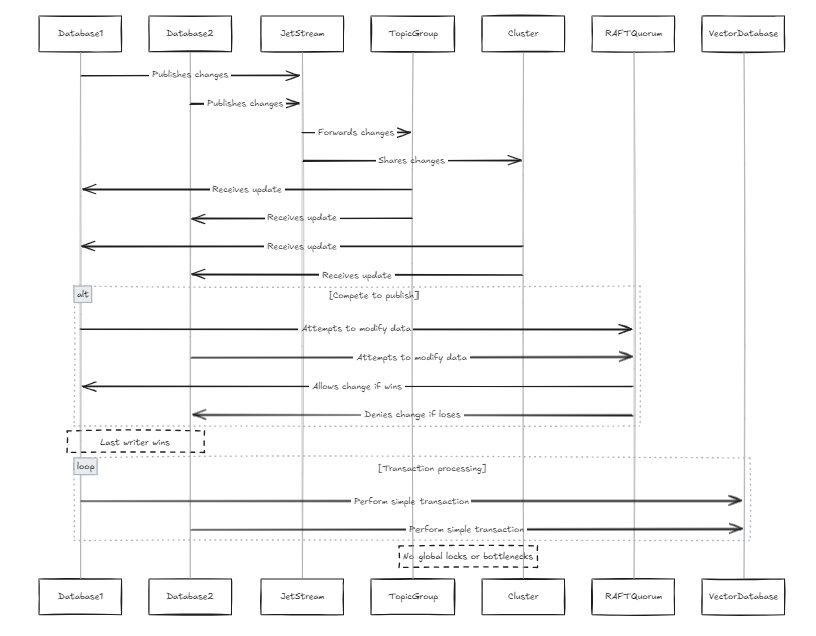 各データベースには独自のジェットストリームが含まれており、これらのジェットストリームは同じグループのトピックとクラスターのグループに参加します。この場合、すべてのノードが行の変更を公開しようとするたびに、同じジェットストリームを通過します。 2つのノードが同じデータを並行して変更しようとすると、変更を公開するために競合します。変更が伝播されないようにすることは可能ですが、これはデータの損失につながる可能性があります。 JetStreamのRaft Quorumの制約によると、変更を公開できる作家は1人だけです。したがって、私たちは最後の作家が勝つことを可能にするためにシステムを設計しました。これは、従来のデータベースと比較してデータ構造がより単純であるため、ベクターデータベースの問題ではありません(これは、システム自体が単純であることを意味するのではなく、トランザクションシリアル化などの複雑なトランザクションと手順が少ないことを意味します)。これにより、グローバルロックとパフォーマンスのボトルネックも回避されます。
各データベースには独自のジェットストリームが含まれており、これらのジェットストリームは同じグループのトピックとクラスターのグループに参加します。この場合、すべてのノードが行の変更を公開しようとするたびに、同じジェットストリームを通過します。 2つのノードが同じデータを並行して変更しようとすると、変更を公開するために競合します。変更が伝播されないようにすることは可能ですが、これはデータの損失につながる可能性があります。 JetStreamのRaft Quorumの制約によると、変更を公開できる作家は1人だけです。したがって、私たちは最後の作家が勝つことを可能にするためにシステムを設計しました。これは、従来のデータベースと比較してデータ構造がより単純であるため、ベクターデータベースの問題ではありません(これは、システム自体が単純であることを意味するのではなく、トランザクションシリアル化などの複雑なトランザクションと手順が少ないことを意味します)。これにより、グローバルロックとパフォーマンスのボトルネックも回避されます。
古いアーキテクチャを表示します
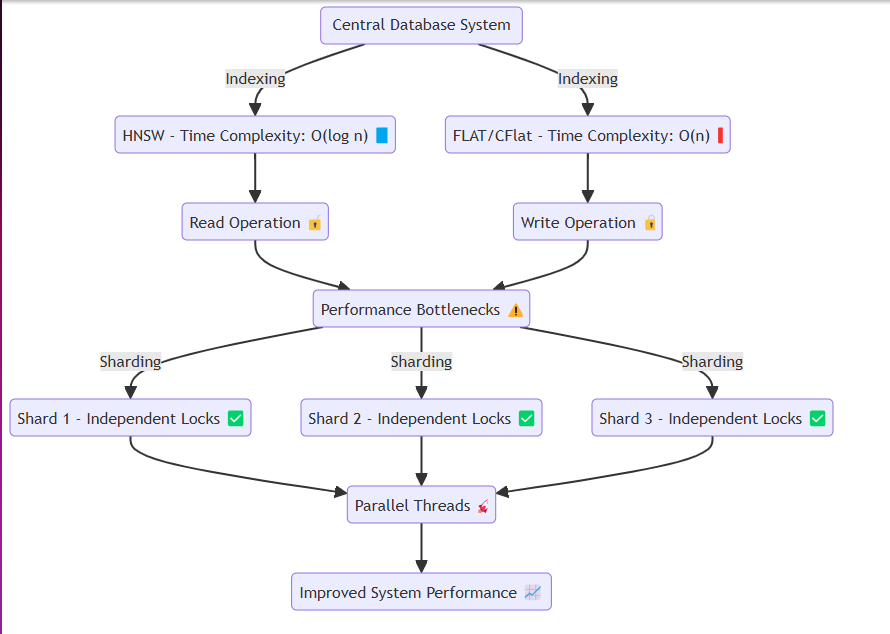 通常、データベースなどのシステムは同じメモリまたはディスクにアクセスし、読み取り操作を繰り返し実行します。このプロセスでは、HNSWのような方法は、O(log n)などの効率的な時間の複雑さを実現できます。ただし、フラットやCFLATなどの精度を必要とする手法は、一般にO(n)の時間の複雑さで線形検索を実行します。
通常、データベースなどのシステムは同じメモリまたはディスクにアクセスし、読み取り操作を繰り返し実行します。このプロセスでは、HNSWのような方法は、O(log n)などの効率的な時間の複雑さを実現できます。ただし、フラットやCFLATなどの精度を必要とする手法は、一般にO(n)の時間の複雑さで線形検索を実行します。
問題は、データ競合を回避するときに発生します。読み書きをするとき、ゴルチンのようなスレッドは、ロックを介してそれぞれのリソースを分離します。具体的には:
これに対処するために、システムの本質を失うことなく、メモリ内でシャードを効率的に作成し、各シャードにデータを割り当てるシステムを設計しました。各シャードには、次のことを可能にするロックメカニズムがあります。
高速のロックリリース:大量のデータを挿入したり、読み取り操作を実行したりする場合。パーティション化されたデータ挿入:データを分割セグメントに挿入できるようにすることにより、スムーズなシステム操作を促進します。この設計により、システムは、重いデータ挿入または高い読み取りリクエストシナリオの下でもシームレスに動作できるようになり、パフォーマンスのボトルネックを軽減できます。
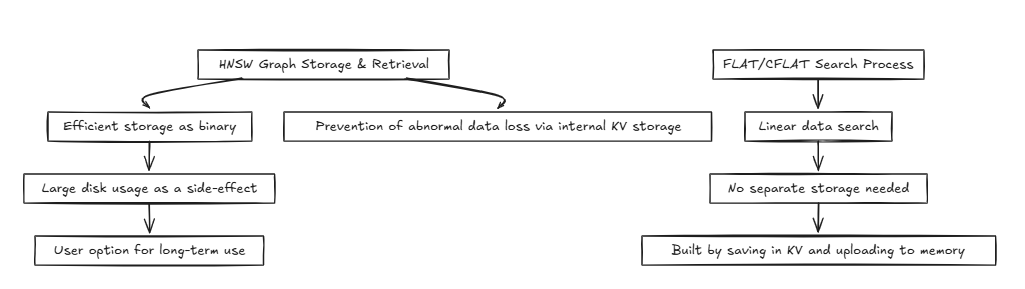
HNSW(階層航行可能な小さな世界):
フラット/cflat(複合フラット):
CFLAT(Composite Flat)は、複数のベクトルを検索し、2つのベクトルの重要性に基づいて複合結果を生成するインデックス作成方法です。
HNSWのようなグラフアルゴリズムに複合ベクトル検索を適用することは、かなりの量のメモリが必要であり、近隣構造とうまく調和せず、複数のグラフを必要とするため、困難です。検索の時間の複雑さはまだO(2 log n)≈O(log n)に収束しますが、空間の複雑さはかなり貧弱です。
これらの問題は、データの量が増えるにつれてますます問題になるようになります。さらに、グラフ構造内の複合キーに基づいてマージして評価する方法は、TOPKを無視し、単一の検索のヒープサイズを大幅に増加させます。
したがって、フラットに基づいて処理することを選択しました。時間の複雑さはo(n)(一定の低下なし)ですが、空間の複雑さはフラットと同じままであり、複合キーに基づいてマージして評価するのに非常に効果的です。
Magine私たちは、ユーザーが入力基準に基づいて理想的なパートナーを見つけるのを支援するマッチメイキング会社向けのサービスを開発しています。個性やその他の属性などのさまざまな要因を検討します。ただし、単一のベクトルを使用すると、これらの要因を検索のために1つの文に結合することを意味し、精度の歪みの可能性が大幅に増加します。
例えば: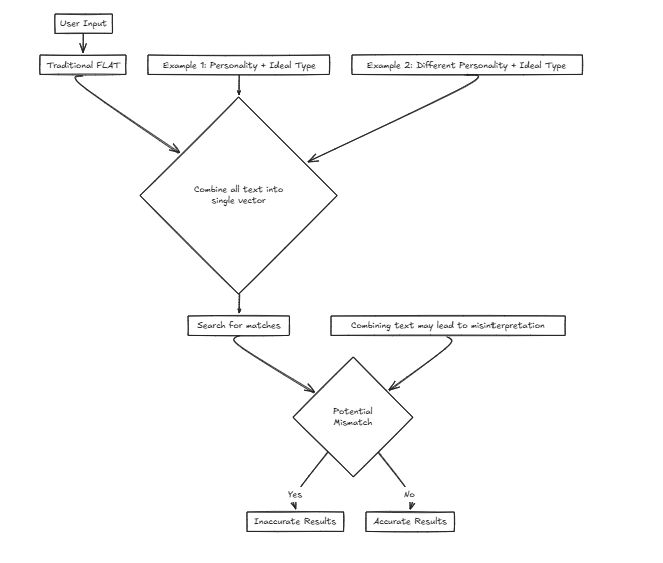 望ましい特徴:{人格:決定的、理想的なタイプ:背が高く、スリム}このシナリオでは、ユーザーは、外部属性に基づいてパートナーを見つけることに焦点を当てて、理想的なタイプを理解する可能性のある人格特性を好みます。
望ましい特徴:{人格:決定的、理想的なタイプ:背が高く、スリム}このシナリオでは、ユーザーは、外部属性に基づいてパートナーを見つけることに焦点を当てて、理想的なタイプを理解する可能性のある人格特性を好みます。
ただし、別のケースを検討してください。
望ましい特性:{人格:気楽な、理想的なタイプ:決定的}ここで、決定的な理想タイプとペアになったのんきな性格を望んでいる人は、ユーザーの本当の好みに合わない方法で決定的な個人と一致するなど、誤った一致をもたらす可能性があります。
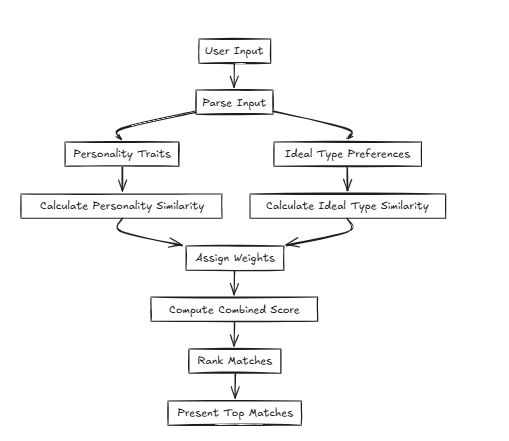 このような場合、CFLAT(Composite Flat)は、人格の類似性と理想的なタイプの類似性を共同で評価することにより、スコアを計算します。ユーザーは各属性に重要なレベルを割り当てることができ、ユーザー定義の優先順位に基づいてより大きな類似性を持つアスペクトに高いスコアを与えることができます。
このような場合、CFLAT(Composite Flat)は、人格の類似性と理想的なタイプの類似性を共同で評価することにより、スコアを計算します。ユーザーは各属性に重要なレベルを割り当てることができ、ユーザー定義の優先順位に基づいてより大きな類似性を持つアスペクトに高いスコアを与えることができます。
Edgeとは、中央サーバーと通信せずに近くのデバイスでデータを送信および受信する機能を指します。ただし、実際には、ソフトウェアの「Edge」は、中央サーバーと比較してより軽いリソースに制約のある環境で展開されることが多いため、この概念とは異なる場合があります。
NNV-Edgeは、小規模なベクトルデータセット(最大100万ベクター)で軽量な方法で迅速に動作するように設計されており、元のNNVから自動化されたタスクをユーザーに戻し、より大きなコントロールを転送します。
HNSW、Faiss、Assheなどの高度なアルゴリズムは優れていますが、小規模なスペックには少し重いと思いませんか?そして、アルゴリズムを脇に置いて、Milvus、Weaviate、Qdrantなどのプロジェクトは素晴らしい心によって構築されていますが、小型のポータブルデバイスで他のソフトウェアと一緒に実行するにはリソースが集中しすぎていませんか?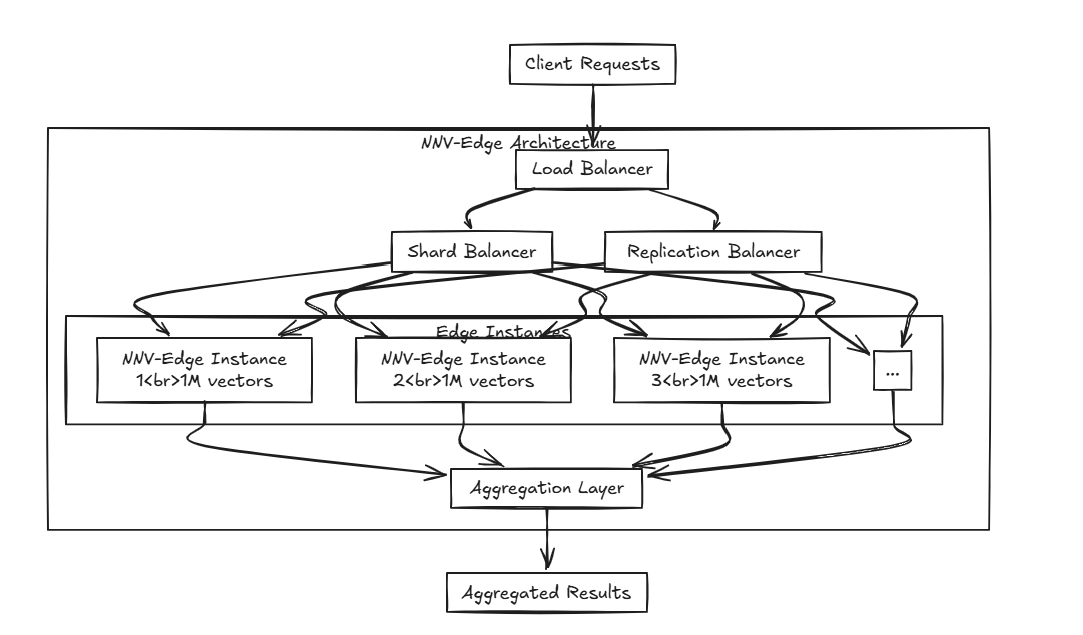 それがNNV-Edgeの登場です。
それがNNV-Edgeの登場です。
複数のエッジを配布した場合はどうなりますか?前述のLoad BalancerでNNV-Edgeを使用することにより、複数のエッジにデータを破棄し、シームレスに集約する高度なセットアップを作成できます。


