nnv
1.0.0

O NNV (não-named.v) é um banco de dados projetado para ser implementado do zero para a produção. O NNV pode ser implantado em ambientes de borda e usado em configurações de produção em pequena escala. Através da abordagem arquitetônica inovadora descrita abaixo, ela é prevista e desenvolvida para ser usada de maneira confiável em ambientes de produção em larga escala também.
Para o histórico completo de atualização, consulte o histórico de atualização.
Planejamos apoiar o CFLAT, que pode facilitar vários serviços por meio de operações mais complexas que permitem pesquisas multi-vetoriais. CFLAT é apenas um nome que eu cunhei. Por favor, tome nota!
O desempenho pode ser temporariamente reduzido devido ao desenvolvimento contínuo. Obrigado pela sua paciência!
Windows & Linux
git clone https://github.com/sjy-dv/nnv
cd nnv
# start edge
go run cmd/root/main.go -mode=edge
# start core
go run cmd/root/main.go -mode=root
MacOS
** The CPU acceleration (SSE, AVX2, AVX-512) code has caused an error where it does not function on Mac, and it is not a priority to address at this time. **
git clone https://github.com/sjy-dv/nnv
cd nnv
source .env
deploy
make edge-dockerCaracterísticas
ARQUITETURA
Bugfix
Ao planejar este projeto, pensei muito.
Ao configurar o ambiente de cluster, é natural que a maioria dos desenvolvedores escolha o algoritmo da balsa, como eu sempre fiz antes. A razão é que é uma abordagem comprovada usada por projetos bem -sucedidos.
No entanto, comecei a me perguntar: não é um pouco complexo? A jangada aumenta a disponibilidade de leitura, mas diminui a disponibilidade de gravação. Então, como eu resolveria isso se o Multi-Write se tornar necessário a longo prazo?
Dada a natureza dos bancos de dados de vetores, presumi que a maioria dos serviços seria estruturada em torno de trabalhos em lotes, em vez de escrever em tempo real. Mas isso significa que eu posso simplesmente pular abordando o problema? Eu não pensei assim. No entanto, a criação de uma configuração com vários líderes no topo da balsa usando algo como fofocas parecia extremamente complexa e difícil. 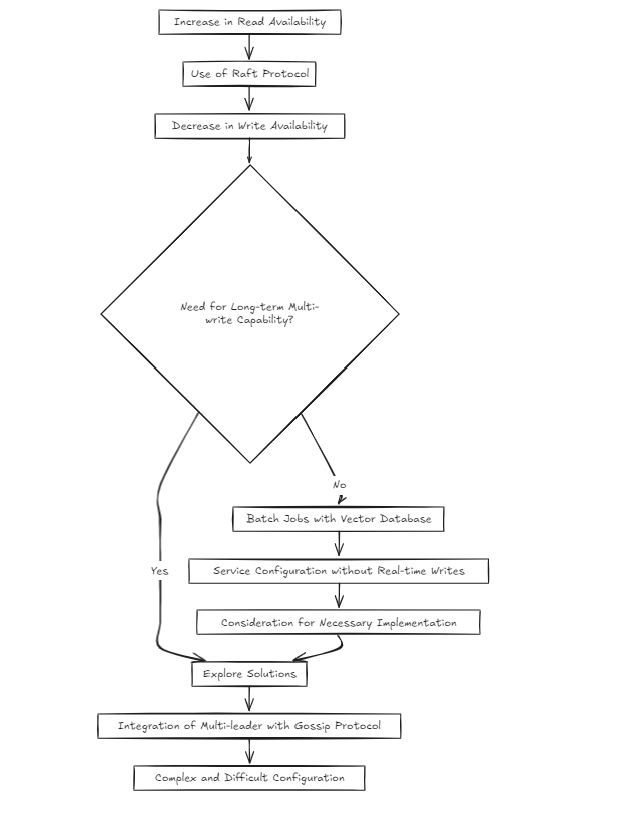
Portanto, até hoje (2024-10-20), estou considerando duas abordagens arquitetônicas.
A arquitetura é dividida em duas abordagens.
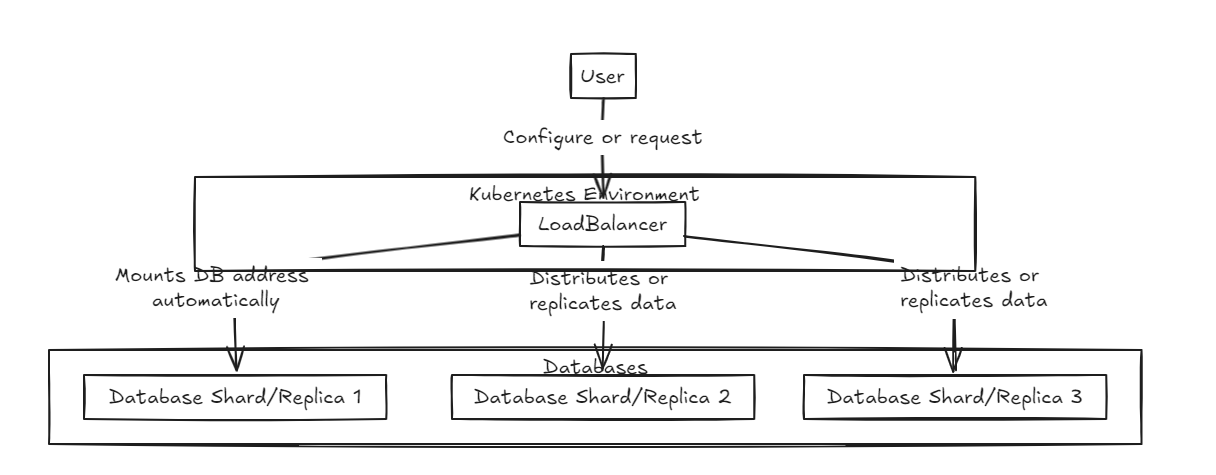
Primeiro, um balanceador de carga é colocado na frente, apoiando o sharding e a integração dos dados. O banco de dados interno existe em um estado puro.
 |  |
|---|---|
| Réplica lb | Shard lb |
O balanceador de carga de replicação aguarda que todos os bancos de dados concluam as gravações com êxito antes de se comprometer ou reverter, enquanto o balanceador de carga do Shard distribui a carga uniformemente nos bancos de dados do Shard para garantir capacidades de armazenamento semelhantes.
A principal diferença é que a replicação pode desacelerar as operações de gravação, mas fornece um desempenho de leitura mais rápido a médio a longo prazo em comparação com o balanceador de carga do Shard. Por outro lado, a abordagem do Shard oferece velocidades de gravação mais rápidas, porque só se compromete com um fragmento específico, mas a leitura requer a coleta de dados de todos os fragmentos, que são mais lentos inicialmente, mas podem se tornar mais rápidos que a replicação à medida que o conjunto de dados cresce.
Portanto, para gerenciar grandes volumes de dados, o balancer do Shard é um pouco mais recomendado. No entanto, o ponto principal de ambas as arquiteturas é sua simplicidade na configuração e gerenciamento, tornando -as fáceis de manusear como um servidor de back -end típico.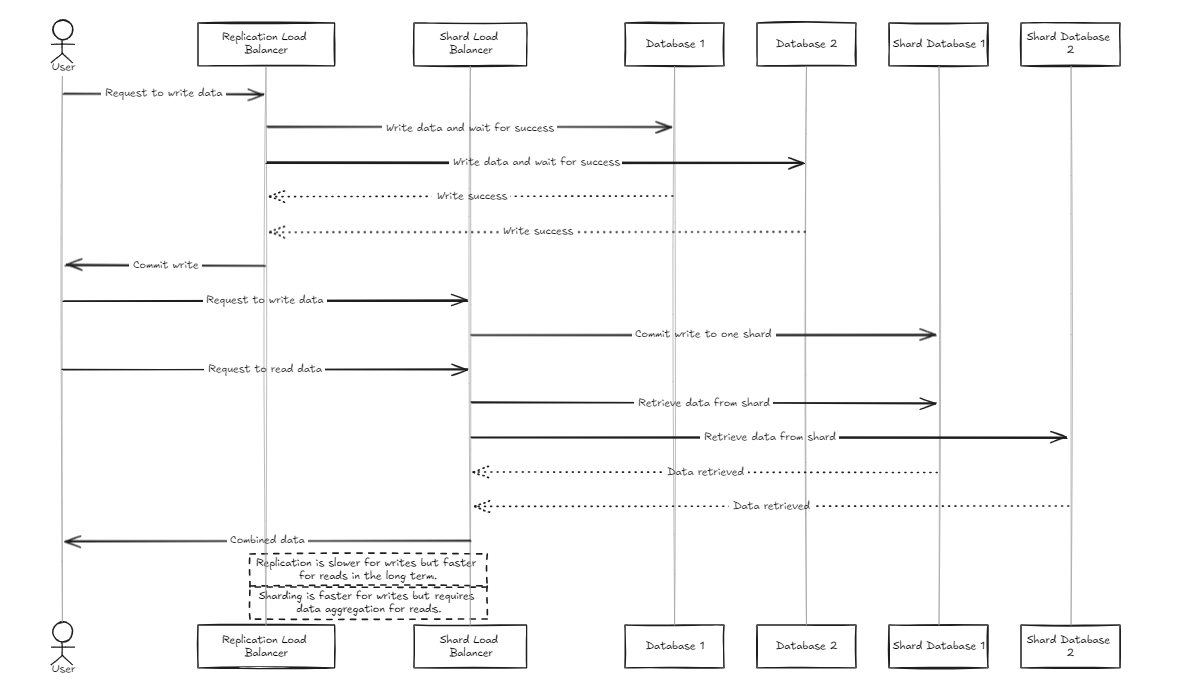
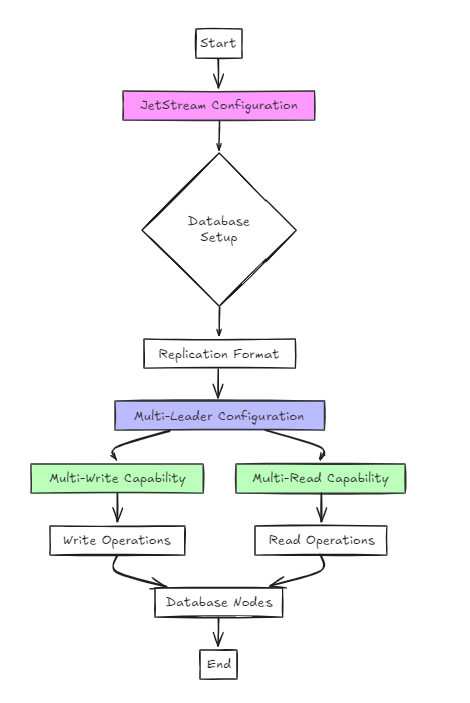
A segunda abordagem utiliza o JetStream para a configuração.
Embora isso seja arquitetonicamente mais simples que a abordagem anterior, da perspectiva do usuário, a configuração não é significativamente diferente da balsa.
No entanto, a principal diferença é que, diferentemente da RAFT, ele suporta configurações multi-escriv para leitura múltipla, em vez de uma gravação única e de leitura múltipla.
Nesta abordagem, o banco de dados é configurado em um formato de replicação, e o JetStream é usado para ativar as configurações de vários líderes.
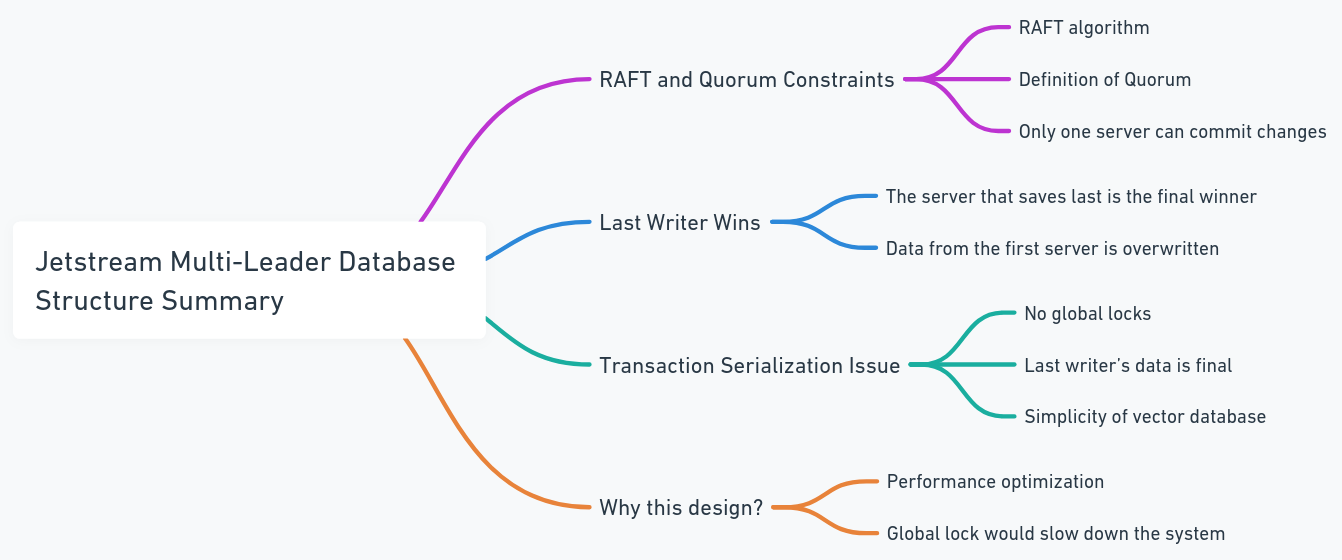
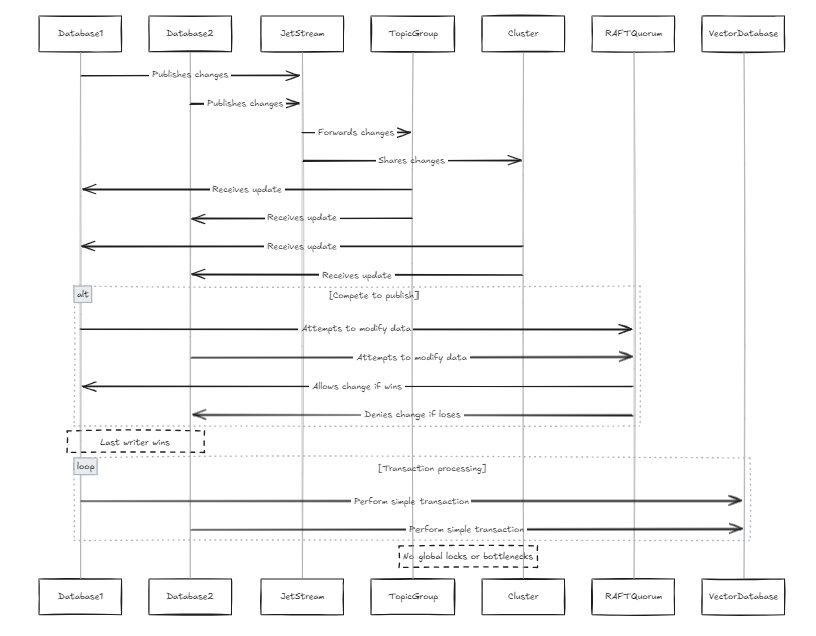 Cada banco de dados contém seu próprio JetStream, e esses JetsTreams se juntam ao mesmo grupo de tópicos e clusters. Nesse caso, sempre que todos os nós tentam publicar alterações em uma linha, eles passam pelo mesmo JetStream. Se dois nós tentarem modificar os mesmos dados em paralelo, eles competirão para publicar suas alterações. Embora seja possível impedir que as mudanças sejam propagadas, isso pode levar à perda de dados. De acordo com a restrição de quorum da balsa em JetStream, apenas um escritor pode publicar a mudança. Portanto, projetamos o sistema para permitir que o último escritor vence. Isso não é um problema para bancos de dados vetoriais porque, em comparação com os bancos de dados tradicionais, a estrutura de dados é mais simples (isso não implica que o sistema em si seja simples, mas sim que há menos transações e procedimentos complexos, como a serialização da transação). Isso também evita bloqueios globais e gargalos de desempenho.
Cada banco de dados contém seu próprio JetStream, e esses JetsTreams se juntam ao mesmo grupo de tópicos e clusters. Nesse caso, sempre que todos os nós tentam publicar alterações em uma linha, eles passam pelo mesmo JetStream. Se dois nós tentarem modificar os mesmos dados em paralelo, eles competirão para publicar suas alterações. Embora seja possível impedir que as mudanças sejam propagadas, isso pode levar à perda de dados. De acordo com a restrição de quorum da balsa em JetStream, apenas um escritor pode publicar a mudança. Portanto, projetamos o sistema para permitir que o último escritor vence. Isso não é um problema para bancos de dados vetoriais porque, em comparação com os bancos de dados tradicionais, a estrutura de dados é mais simples (isso não implica que o sistema em si seja simples, mas sim que há menos transações e procedimentos complexos, como a serialização da transação). Isso também evita bloqueios globais e gargalos de desempenho.
Veja a arquitetura antiga
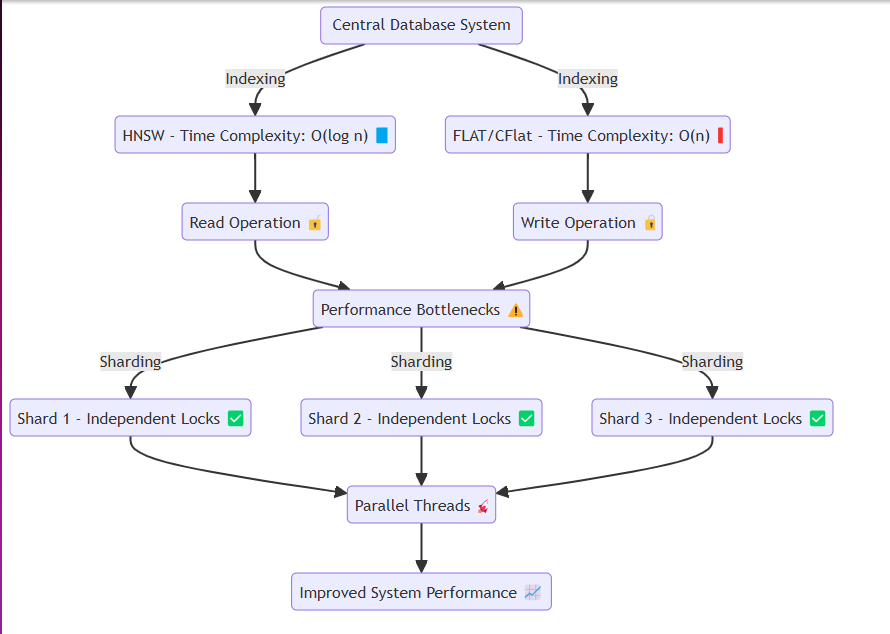 Normalmente, sistemas como bancos de dados acessam a mesma memória ou disco, executando repetidamente operações de leitura e gravação. Nesse processo, métodos como o HNSW podem obter complexidades de tempo eficientes como O (log n) . No entanto, técnicas que requerem precisão, como plana e cflat, geralmente executam pesquisas lineares com uma complexidade de tempo de O (n) .
Normalmente, sistemas como bancos de dados acessam a mesma memória ou disco, executando repetidamente operações de leitura e gravação. Nesse processo, métodos como o HNSW podem obter complexidades de tempo eficientes como O (log n) . No entanto, técnicas que requerem precisão, como plana e cflat, geralmente executam pesquisas lineares com uma complexidade de tempo de O (n) .
O problema surge ao evitar a contenção de dados. Ao ler ou escrever, tópicos como Goroutines isolam os respectivos recursos por meio de bloqueios. Especificamente:
Para resolver isso, projetamos o sistema para criar com eficiência fragmentos na memória e atribuir dados a cada shard sem perder a essência do sistema. Cada fragmento apresenta um mecanismo de travamento que permite:
Liberação mais rápida de bloqueio : ao inserir grandes quantidades de dados ou executar operações de leitura. Inserção de dados particionados : facilitando as operações suaves do sistema, permitindo que os dados sejam inseridos em segmentos divididos. Esse design garante que o sistema possa operar perfeitamente, mesmo sob inserção de dados pesados ou cenários de solicitação de alta leitura, atenuando assim os gargalos de desempenho.
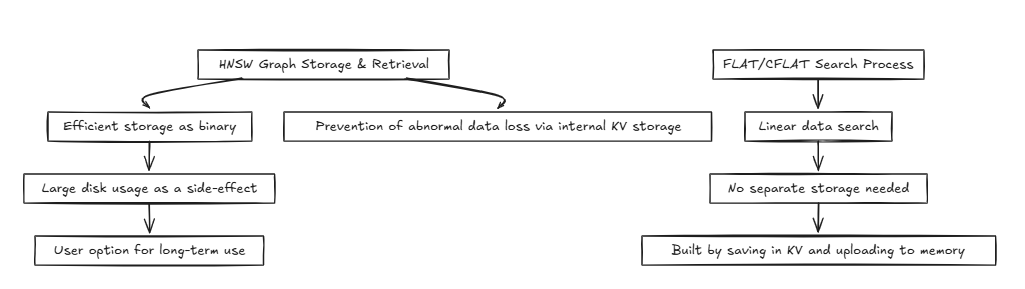
HNSW (mundo pequeno hierárquico navegável):
Plana/cflat (composto plano):
O CFLAT (Composite Flat) é um método de indexação que pesquisa vários vetores e produz resultados compostos com base na importância de dois vetores.
A aplicação da pesquisa de vetores compostos em gráficos de algoritmos como o HNSW é um desafio porque requer uma quantidade significativa de memória e não se alinha bem às estruturas da vizinhança, necessitando de vários gráficos. Embora a complexidade do tempo da pesquisa ainda converja para O (2 log n) ≈ O (log n), a complexidade do espaço é consideravelmente ruim.
Esses problemas se tornam cada vez mais problemáticos à medida que a quantidade de dados cresce. Além disso, o método de fusão e avaliação com base nas teclas compostas na estrutura do gráfico ignora Topk e aumenta significativamente o tamanho da pilha de uma única pesquisa.
Portanto, optamos por processar com base no plano. Embora a complexidade do tempo seja O (n) (sem quedas constantes), a complexidade do espaço permanece a mesma que plana e é altamente eficaz para mesclar e avaliar com base em teclas compostas.
Magine, estamos desenvolvendo um serviço para uma empresa de matchmaking que ajuda os usuários a encontrar seus parceiros ideais com base nos critérios de entrada. Estaremos considerando vários fatores, como personalidade e outros atributos. No entanto, o uso de um único vetor significa combinar esses fatores em uma frase para a pesquisa, o que aumenta muito a probabilidade de distorção da precisão.
Por exemplo: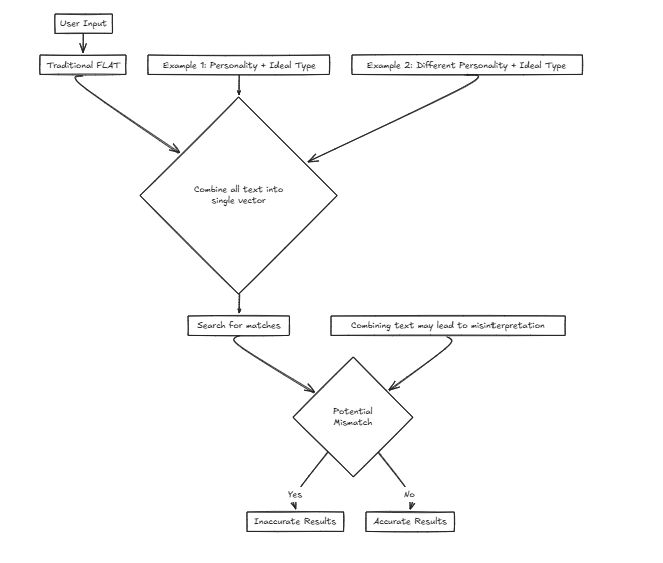 Características desejadas: {Personalidade: decisiva, tipo ideal: alto e fino} Nesse cenário, o usuário prefere um traço de personalidade que torna o tipo ideal que alguém provavelmente os apreciará, concentrando -se em encontrar um parceiro com base em atributos externos.
Características desejadas: {Personalidade: decisiva, tipo ideal: alto e fino} Nesse cenário, o usuário prefere um traço de personalidade que torna o tipo ideal que alguém provavelmente os apreciará, concentrando -se em encontrar um parceiro com base em atributos externos.
No entanto, considere outro caso:
Características desejadas: {Personalidade: Equilíbrio, Tipo Ideal: decisivo} Aqui, alguém que deseja uma personalidade descontraída emparelhada com um tipo ideal decisivo pode resultar em correspondências incorretas, como a correspondência com indivíduos que são decisivos de maneiras que não se alinham às verdadeiras preferências do usuário.
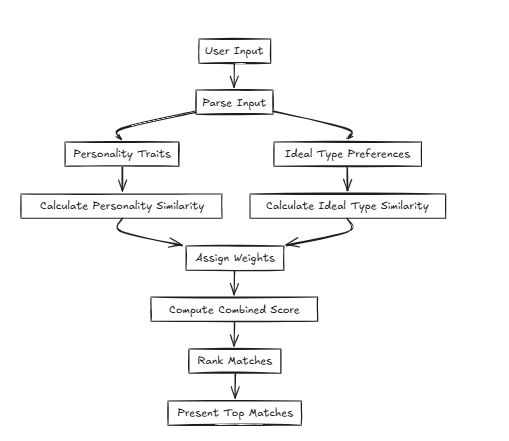 Nesses casos, o CFLAT (composto FLAT) calcula os escores avaliando em conjunto a similaridade na personalidade e a similaridade no tipo ideal. Os usuários podem atribuir níveis de importância a cada atributo, permitindo que pontuações mais altas sejam fornecidas aos aspectos com maior similaridade com base em prioridades definidas pelo usuário.
Nesses casos, o CFLAT (composto FLAT) calcula os escores avaliando em conjunto a similaridade na personalidade e a similaridade no tipo ideal. Os usuários podem atribuir níveis de importância a cada atributo, permitindo que pontuações mais altas sejam fornecidas aos aspectos com maior similaridade com base em prioridades definidas pelo usuário.
O Edge refere -se à capacidade de transmitir e receber dados em dispositivos próximos sem comunicação com um servidor central. No entanto, na prática, "Edge" no software às vezes pode diferir desse conceito, pois é frequentemente implantado em ambientes mais leves e com restrição de recursos em comparação com um servidor central.
O NNV-Edge foi projetado para operar rapidamente em conjuntos de dados vetoriais em menor escala (até 1 milhão de vetores) de maneira leve, transferindo tarefas automatizadas do NNV original de volta ao usuário para maior controle.
Algoritmos avançados como HNSW, FAISS e Irrita são excelentes, mas você não acha que eles podem ser um pouco pesados para especificações de menor escala? E deixando de lado os algoritmos, enquanto projetos como Milvus, Weaviate e Qdrant são construídos por mentes brilhantes, eles não são muito intensivos para executar ao lado de outros softwares em dispositivos pequenos e portáteis?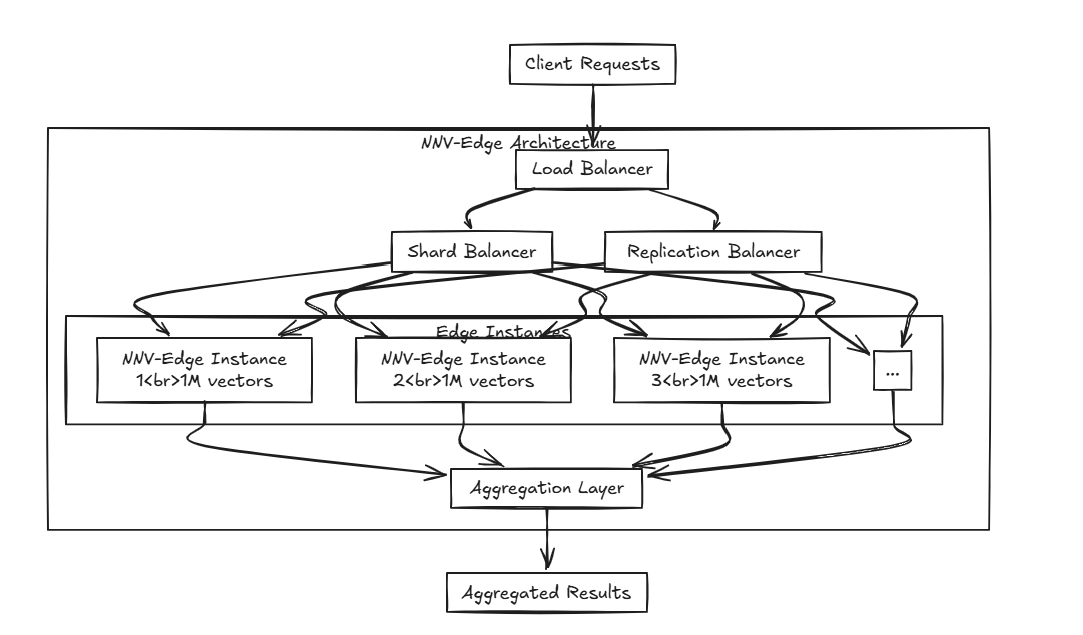 É aí que entra.
É aí que entra.
E se você distribuir várias arestas? Ao usar a borda NNV com o balanceador de carga mencionado anteriormente, você pode criar uma configuração avançada que encala os dados em várias arestas e agregue-os perfeitamente!


