nnv
1.0.0

NNV (no-named.v)-это база данных, предназначенная для реализации с нуля к производству. NNV может быть развернут в Edge Environments и используется в небольших настройках производства. Благодаря инновационному архитектурному подходу, описанному ниже, он предполагается и разработан для надежного использования и в крупномасштабных производственных средах.
Для полной истории обновления см. Историю обновления.
Мы планируем поддержать CFLAT, который может облегчить различные услуги благодаря более сложным операциям, которые позволяют поиск многоклереров. CFLAT - это просто имя, которое я придумал. Пожалуйста, примите к сведению!
Производительность может быть временно снижена из -за постоянной разработки. Спасибо за терпение!
Windows & Linux
git clone https://github.com/sjy-dv/nnv
cd nnv
# start edge
go run cmd/root/main.go -mode=edge
# start core
go run cmd/root/main.go -mode=root
MacOS
** The CPU acceleration (SSE, AVX2, AVX-512) code has caused an error where it does not function on Mac, and it is not a priority to address at this time. **
git clone https://github.com/sjy-dv/nnv
cd nnv
source .env
deploy
make edge-dockerФункции
АРХИТЕКТУРА
Bugfix
Планируя этот проект, я много думал.
При настройке кластерной среды для большинства разработчиков естественно выбирать алгоритм плота, как я всегда делал раньше. Причина в том, что это проверенный подход, используемый успешными проектами.
Тем не менее, я начал задаваться вопросом: разве это не сложно? Рэт увеличивает доступность чтения, но снижает доступность записи. Итак, как бы я решил это, если в долгосрочной перспективе станет необходимым мультипит?
Учитывая природу векторных баз данных, я предположил, что большинство услуг будут структурированы на партийных рабочих местах, а не в письменной форме в реальном времени. Но значит ли это, что я могу просто пропустить решение проблемы? Я так не думал. Тем не менее, создание многолудочной установки поверх плота, используя что-то вроде сплетен, было чрезвычайно сложным и трудным. 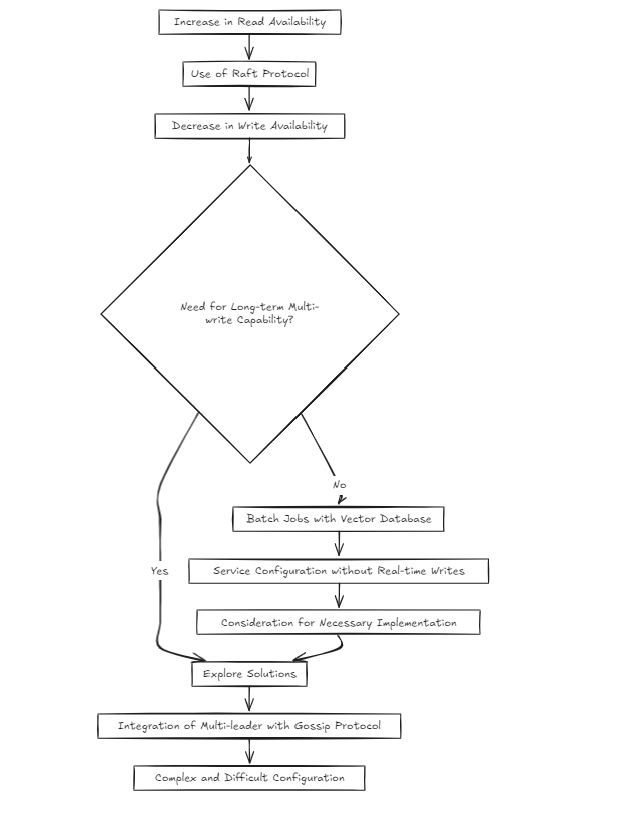
Поэтому на сегодняшний день (2024-10-20) я рассматриваю два архитектурных подхода.
Архитектура разделена на два подхода.
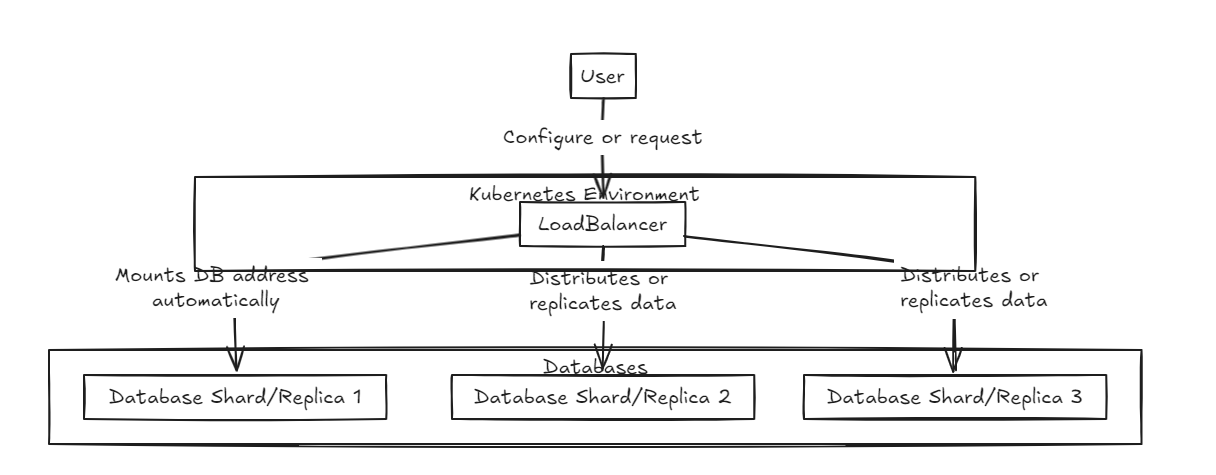
Во -первых, спереди расположен балансировщиком нагрузки, поддерживая как шардинг, так и интеграцию данных. Внутренняя база данных существует в чистом состоянии.
 |  |
|---|---|
| Реплика lb | Шард LB |
Балансировщик нагрузки на репликацию ждет успешного завершения всех баз данных, прежде чем совершать или откатываться назад, в то время как балансировщик нагрузки на шард распределяет нагрузку равномерно по базам данных Shard, чтобы обеспечить аналогичные возможности хранения.
Ключевое отличие состоит в том, что репликация может замедлить операции записи, но обеспечивает более быструю производительность считывания в среднем и долгосрочной перспективе по сравнению с балансировщиком нагрузки Shard. С другой стороны, подход Shard предлагает более быстрые скорости записи, потому что он только поступает в определенный осколок, но чтение требует сбора данных от всех осколков, что изначально медленнее, но может стать быстрее, чем репликация по мере роста набора данных.
Следовательно, для управления большими объемами данных, балансировщик Shard немного более рекомендуется. Тем не менее, основной момент обеих архитектур является их простота в настройке и управлении, что делает их такими же простыми для обработки, как типичный бэкэнд -сервер.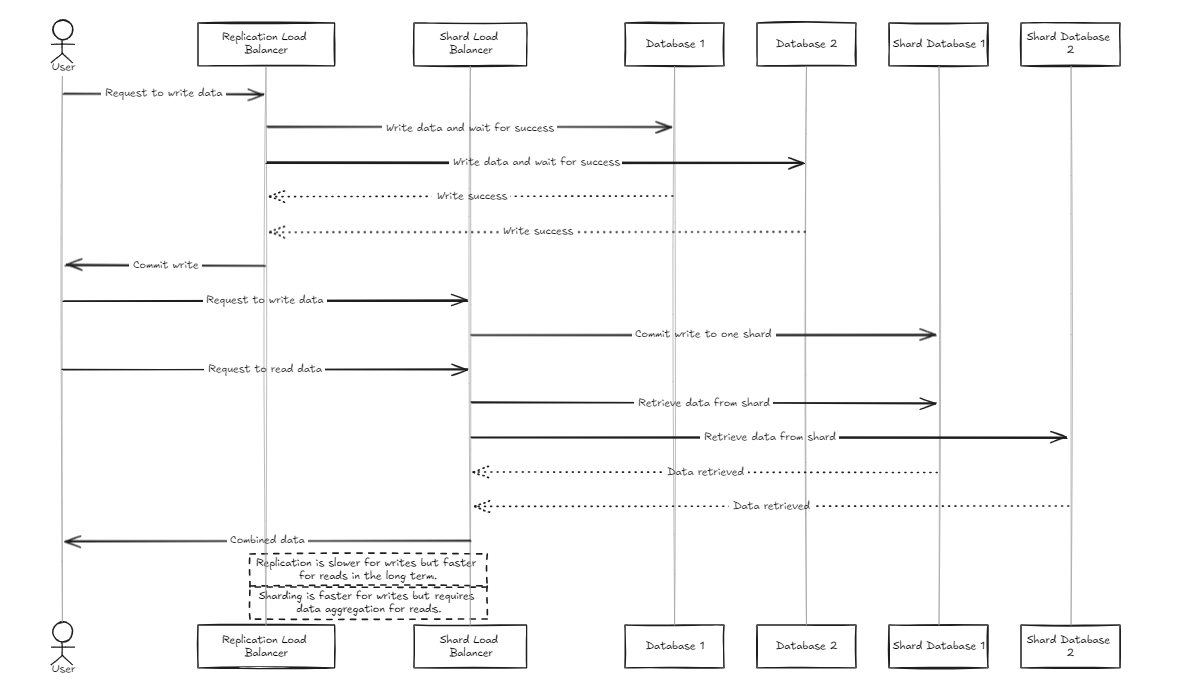
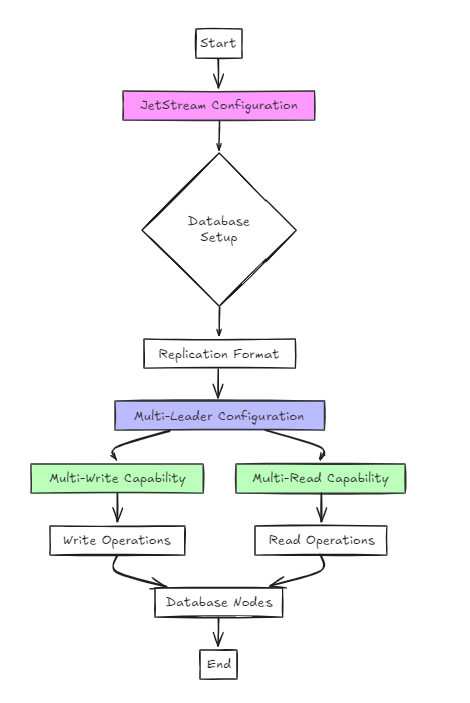
Второй подход использует JetStream для конфигурации.
Хотя это архитектурно проще, чем предыдущий подход, с точки зрения пользователя, настройка существенно не отличается от плота.
Тем не менее, ключевое отличие состоит в том, что, в отличие от RAFT, он поддерживает мультипийные и многочисленные конфигурации, а не однопийную и многочисленную.
В этом подходе база данных настроена в формате репликации, а JetStream используется для включения конфигураций с несколькими лидерами.
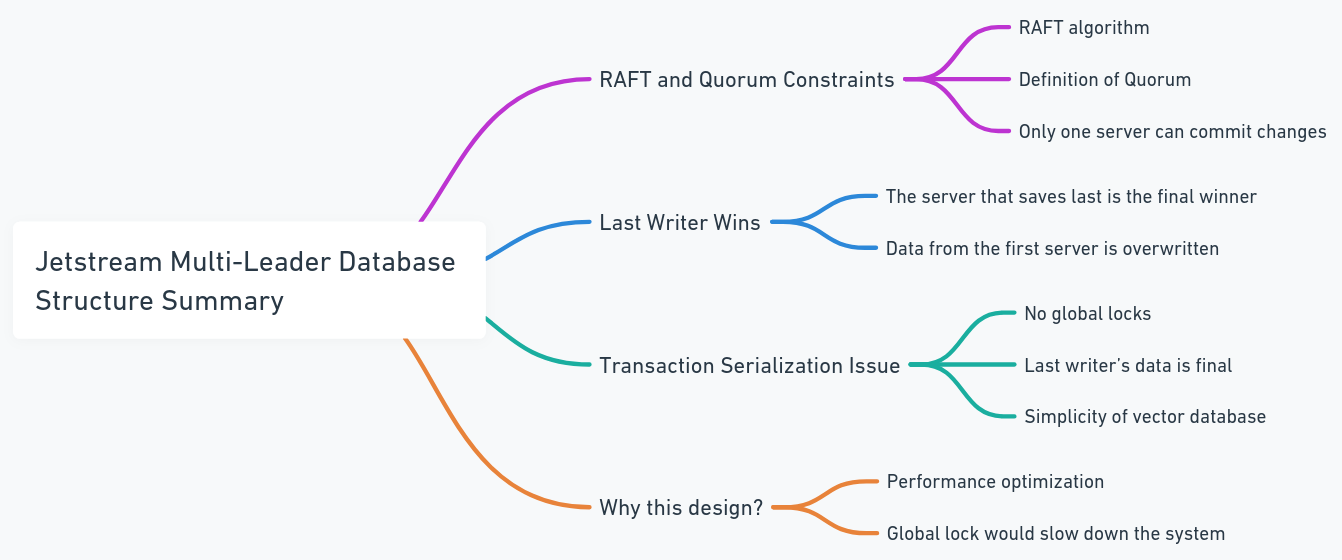
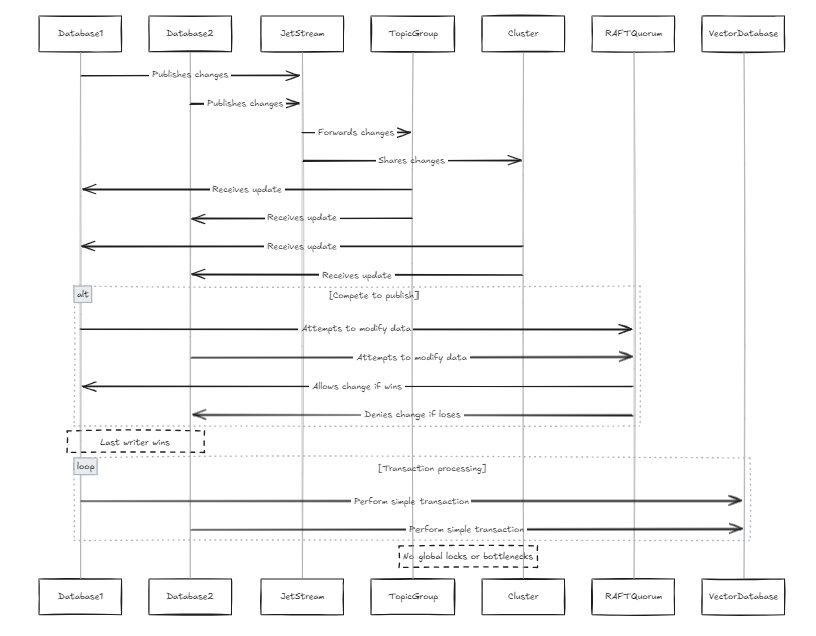 Каждая база данных содержит свой собственный JetStream, и эти JetStreams присоединяются к одной и той же группе тем и кластеров. В этом случае, когда все узлы пытаются публиковать изменения в строке, они проходят через один и тот же JetStream. Если два узла попытаются изменить одни и те же данные параллельно, они будут конкурировать, чтобы опубликовать свои изменения. Хотя можно предотвратить распространение изменений, это может привести к потере данных. Согласно ограничению плота кворума в JetStream, только один писатель может опубликовать изменения. Поэтому мы спроектировали систему, чтобы позволить последнему писателю победить. Это не проблема для векторных баз данных, потому что, по сравнению с традиционными базами данных, структура данных проще (это не означает, что сама система проста, а скорее, что существует меньше сложных транзакций и процедур, таких как сериализация транзакций). Это также избегает глобальных замков и узких мест производительности.
Каждая база данных содержит свой собственный JetStream, и эти JetStreams присоединяются к одной и той же группе тем и кластеров. В этом случае, когда все узлы пытаются публиковать изменения в строке, они проходят через один и тот же JetStream. Если два узла попытаются изменить одни и те же данные параллельно, они будут конкурировать, чтобы опубликовать свои изменения. Хотя можно предотвратить распространение изменений, это может привести к потере данных. Согласно ограничению плота кворума в JetStream, только один писатель может опубликовать изменения. Поэтому мы спроектировали систему, чтобы позволить последнему писателю победить. Это не проблема для векторных баз данных, потому что, по сравнению с традиционными базами данных, структура данных проще (это не означает, что сама система проста, а скорее, что существует меньше сложных транзакций и процедур, таких как сериализация транзакций). Это также избегает глобальных замков и узких мест производительности.
Посмотреть старую архитектуру
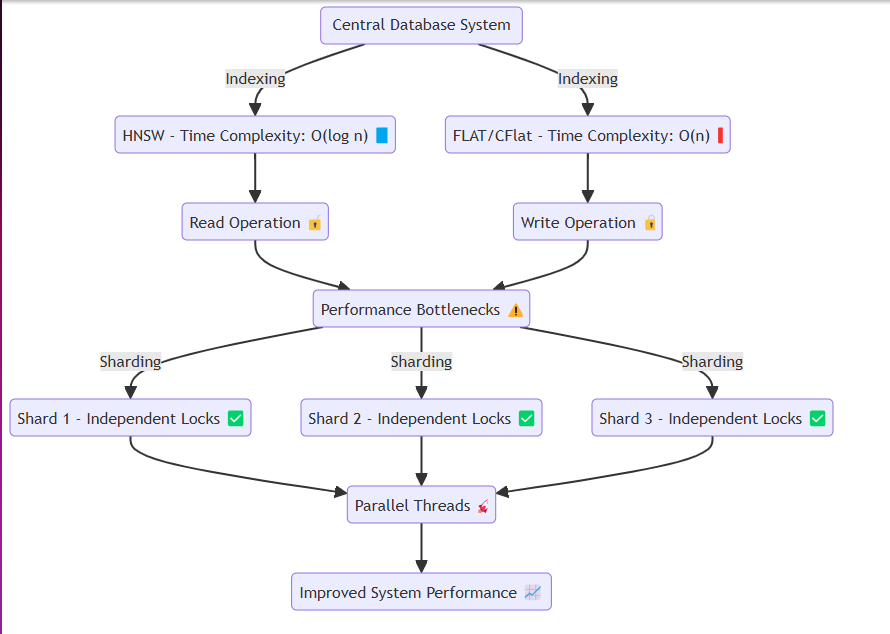 Как правило, такие системы, как базы данных, получают одну и ту же память или диск, многократно выполняя операции чтения и записи. В этом процессе, такие методы, как HNSW, могут достигать эффективных временных сложностей, таких как O (log n) . Тем не менее, методы, которые требуют точности, таких как плоский и CFLAT, обычно выполняют линейные поиски со сложностью времени O (n) .
Как правило, такие системы, как базы данных, получают одну и ту же память или диск, многократно выполняя операции чтения и записи. В этом процессе, такие методы, как HNSW, могут достигать эффективных временных сложностей, таких как O (log n) . Тем не менее, методы, которые требуют точности, таких как плоский и CFLAT, обычно выполняют линейные поиски со сложностью времени O (n) .
Проблема возникает при избегании спора данных. При чтении или написании, такие потоки, как Goroutines, изолируют соответствующие ресурсы через замки. Конкретно:
Чтобы решить эту проблему, мы разработали систему для эффективного создания осколков в памяти и назначения данных каждому осколкам, не теряя сущность системы. Каждый осколок имеет механизм блокировки, который позволяет:
Более быстрый выпуск блокировки : при вставке больших объемов данных или выполнения операций чтения. Разделенная вставка данных : облегчение операций с плавными системами, позволяя вставить данные в разделенные сегменты. Этот дизайн гарантирует, что система может беспрепятственно работать даже при тяжелой вставке данных или сценариях запросов с высоким чтением, тем самым смягчая узкие места производительности.
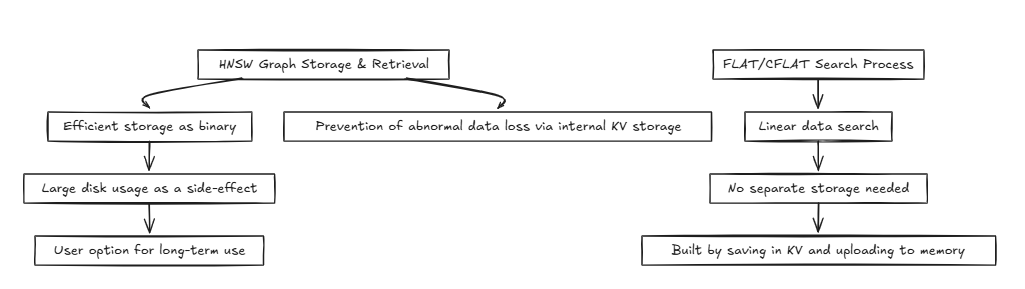
HNSW (иерархический судоходный маленький мир):
Flat/Cflat (составная плоская):
CFLAT (Composite Flat) - это метод индексации, который ищет несколько векторов и дает составные результаты на основе важности двух векторов.
Применение композитного векторного поиска к алгоритмам графиков, таких как HNSW, является сложным, поскольку он требует значительного объема памяти и плохо соответствует структурам соседства, что требует нескольких графиков. Хотя сложность времени для поиска по -прежнему сходится к O (2 log n) ≈ o (log n), сложность пространства значительно плохая.
Эти проблемы становятся все более проблематичными по мере роста объема данных. Кроме того, метод слияния и оценки на основе композитных клавиш в структуре графика игнорирует Topk и значительно увеличивает размер кучи для одного поиска.
Поэтому мы решили обрабатывать на основе квартиры. Несмотря на то, что временная сложность составляет O (n) (без каких -либо постоянных капель), сложность пространства остается такой же, как плоская, и она очень эффективна для слияния и оценки на основе композитных ключей.
Magine Мы разрабатываем сервис для компании, которая помогает пользователям найти своих идеальных партнеров на основе критериев ввода. Мы будем рассматривать различные факторы, такие как личность и другие атрибуты. Однако использование одного вектора означает объединение этих факторов в одно предложение для поиска, что значительно увеличивает вероятность искажения точности.
Например: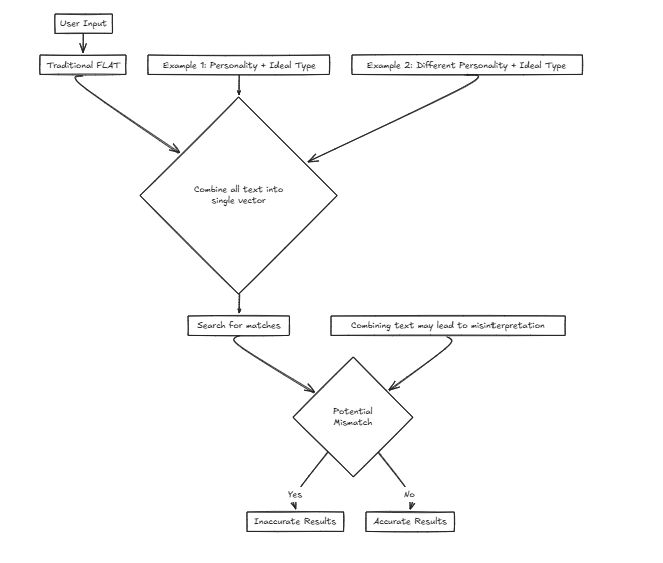 Желаемые черты: {Личность: решающий, идеальный тип: высокий и тонкий} В этом сценарии пользователь предпочитает личность, которая делает идеальный тип, который может оценить его, сосредоточившись на поиске партнера на основе внешних атрибутов.
Желаемые черты: {Личность: решающий, идеальный тип: высокий и тонкий} В этом сценарии пользователь предпочитает личность, которая делает идеальный тип, который может оценить его, сосредоточившись на поиске партнера на основе внешних атрибутов.
Однако рассмотрим другой случай:
Желаемые черты: {Личность: легкий, идеальный тип: решающий} Здесь кто -то, кто хочет легкую личность, сочетающуюся с решающим идеальным типом, может привести к неправильным совпадениям, таким как совпадение с людьми, которые решают так, чтобы не соответствовать истинным предпочтениям пользователя.
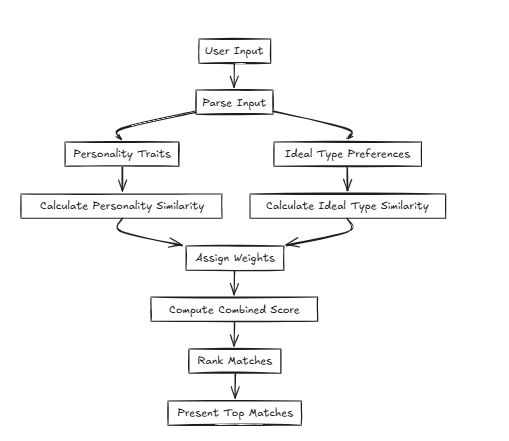 В таких случаях CFLAT (Composite Flat) вычисляет оценки, совместно оценивая сходство в личности и сходство в идеальном типе. Пользователи могут назначать уровни важности каждому атрибуту, позволяя предоставлять более высокие оценки аспектам с большим сходством на основе определенных пользовательских приоритетов.
В таких случаях CFLAT (Composite Flat) вычисляет оценки, совместно оценивая сходство в личности и сходство в идеальном типе. Пользователи могут назначать уровни важности каждому атрибуту, позволяя предоставлять более высокие оценки аспектам с большим сходством на основе определенных пользовательских приоритетов.
Edge относится к возможности передачи и получения данных на близлежащих устройствах без связи с центральным сервером. Однако на практике «Edge» в программном обеспечении иногда может отличаться от этой концепции, так как она часто используется в более легких, ограниченных ресурсных средах по сравнению с центральным сервером.
NNV-Edge предназначен для быстрого работы на наборах векторных данных меньшего масштаба (до 1 миллиона векторов) легким образом, передавая автоматические задачи из исходного NNV обратно пользователю для большего контроля.
Расширенные алгоритмы, такие как HNSW, Faiss и Any, превосходны, но вы не думаете, что они могут быть немного тяжелыми для более мелких характеристик? И отменить алгоритмы, в то время как такие проекты, как Milvus, Weaviate и Qdrant, создаются блестящими умами, разве они не слишком ресурсоемкие, чтобы работать вместе с другими программными средствами на небольших портативных устройствах?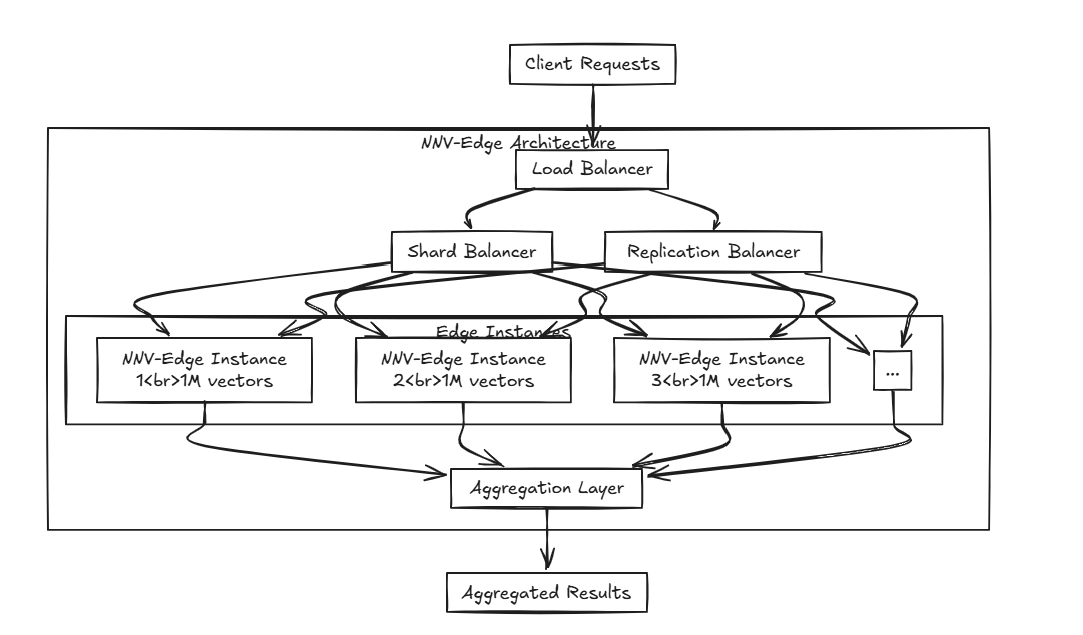 Вот где входит NNV-Edge.
Вот где входит NNV-Edge.
Что если вы распределяете несколько краев? Используя NNV-Edge с ранее упомянутым балансировщиком нагрузки, вы можете создать расширенную настройку, которая раскрывает данные по нескольким ребрам и агрегирует ее плавно!


