nnv
1.0.0

NNV (noamed.v) هي قاعدة بيانات مصممة لتنفيذها من الصفر إلى الإنتاج. يمكن نشر NNV في بيئات الحافة واستخدامها في إعدادات الإنتاج على نطاق صغير. من خلال النهج المعماري المبتكر الموضح أدناه ، من المتصور وتطوير استخدامها بشكل موثوق في بيئات الإنتاج على نطاق واسع أيضًا.
للاطلاع على سجل التحديث الكامل ، راجع تحديث سجل.
نحن نخطط لدعم CFLAT ، والتي يمكن أن تسهل الخدمات المختلفة من خلال العمليات الأكثر تعقيدًا تمكن عمليات البحث متعددة المجالات. CFLAT هو مجرد اسم صاغته. الرجاء أخذ ملاحظة!
قد يتم تقليل الأداء مؤقتًا بسبب التطوير المستمر. شكرا لك على صبرك!
Windows & Linux
git clone https://github.com/sjy-dv/nnv
cd nnv
# start edge
go run cmd/root/main.go -mode=edge
# start core
go run cmd/root/main.go -mode=root
MacOS
** The CPU acceleration (SSE, AVX2, AVX-512) code has caused an error where it does not function on Mac, and it is not a priority to address at this time. **
git clone https://github.com/sjy-dv/nnv
cd nnv
source .env
deploy
make edge-dockerسمات
بنيان
bugfix
عند التخطيط لهذا المشروع ، فكرت به الكثير من التفكير.
عند إعداد بيئة الكتلة ، من الطبيعي أن يختار معظم المطورين خوارزمية الطوافة ، كما فعلت دائمًا من قبل. والسبب هو أنه نهج مثبت تستخدمه المشاريع الناجحة.
ومع ذلك ، بدأت أتساءل: أليس معقدًا بعض الشيء؟ يزيد الطوافة من قراءة توافر ولكنها تقلل من توافر الكتابة. لذا ، كيف يمكنني حل هذا إذا أصبحت الكتابة المتعددة ضرورية على المدى الطويل؟
بالنظر إلى طبيعة قواعد بيانات المتجهات ، افترضت أن معظم الخدمات سيتم تنظيمها حول وظائف الدُفعات بدلاً من الكتابة في الوقت الفعلي. ولكن هل هذا يعني أنه يمكنني فقط تخطي معالجة المشكلة؟ لم أكن أعتقد ذلك. ومع ذلك ، فإن بناء إعداد متعدد القوانين على رأس الطوافة باستخدام شيء مثل القيل والقال ، شعر بالتعقيد للغاية وصعب. 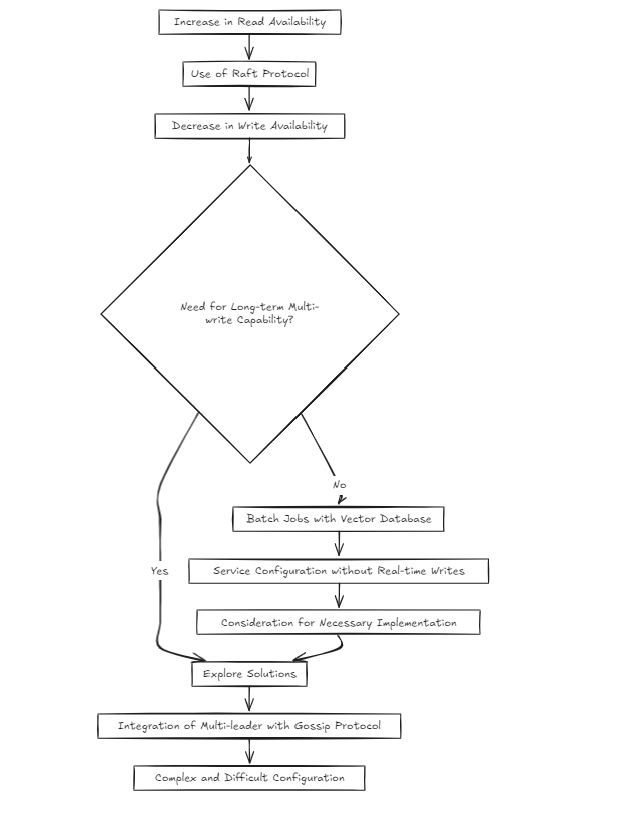
لذلك ، اعتبارا من اليوم (2024-10-20) ، أنا أفكر في نهجين معماريين.
تنقسم الهندسة المعمارية إلى نهجين.
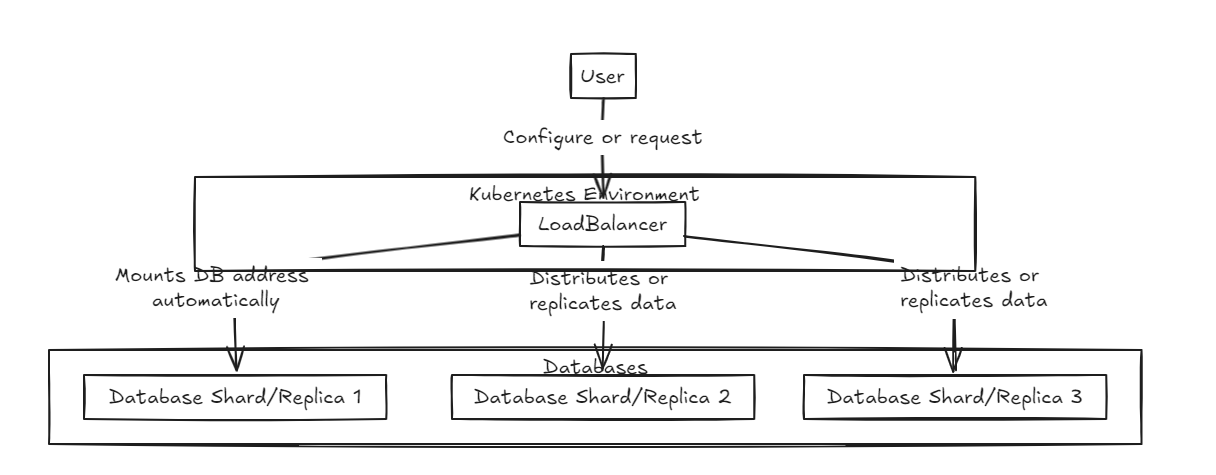
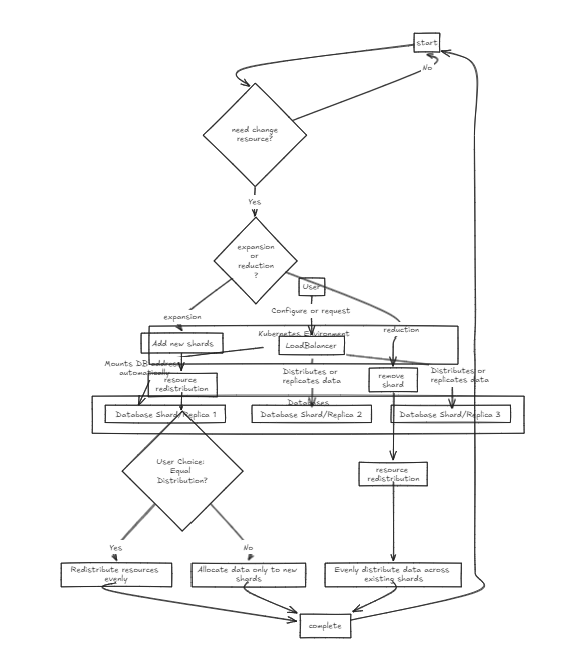
أولاً ، يتم وضع موازن الحمل في المقدمة ، مما يدعم كل من اختلال البيانات وتكاملها. قاعدة البيانات الداخلية موجودة في حالة نقية.
 |  |
|---|---|
| نسخة طبق الأصل LB | Shard LB |
ينتظر موازن تحميل النسخ المتماثل جميع قواعد البيانات لإكمال الكتابة بنجاح قبل الالتزام أو التراجع ، بينما يوزع موازن Shard Load the Load بالتساوي عبر قواعد بيانات Shard لضمان قدرات تخزين مماثلة.
الفرق الرئيسي هو أن النسخ المتماثل يمكن أن يبطئ عمليات الكتابة ولكنه يوفر أداء قراءة أسرع على المدى المتوسط إلى الطويل مقارنة مع موازن تحميل Shard. من ناحية أخرى ، يوفر نهج Shard سرعات أسرع في الكتابة لأنه يرتكب فقط إلى قشرة محددة ، لكن القراءة تتطلب جمع البيانات من جميع القطع ، والتي تكون أبطأ في البداية ولكن يمكن أن تصبح أسرع من النسخ المتماثل مع نمو مجموعة البيانات.
لذلك ، لإدارة كميات كبيرة من البيانات ، ينصح بوسائل الشرق أكثر قليلاً. ومع ذلك ، فإن النقطة الرئيسية لكلا البنيس هي بساطتها في الإعداد والإدارة ، مما يجعلها سهلة التعامل مع خادم الخلفية النموذجي.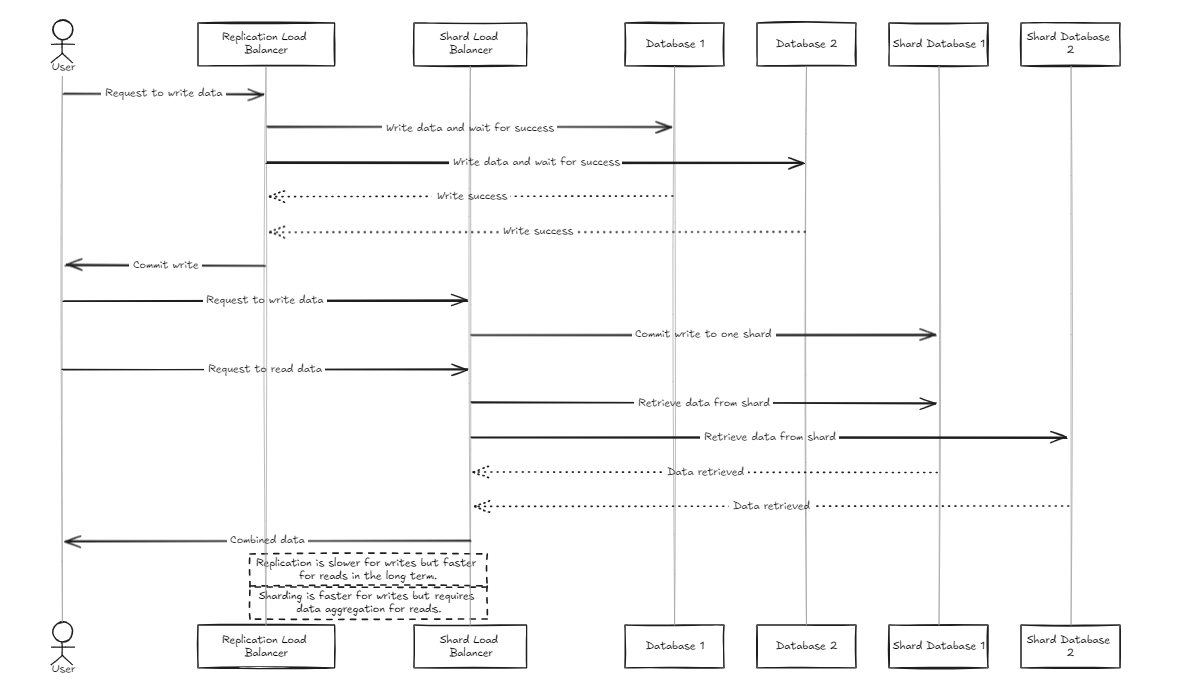
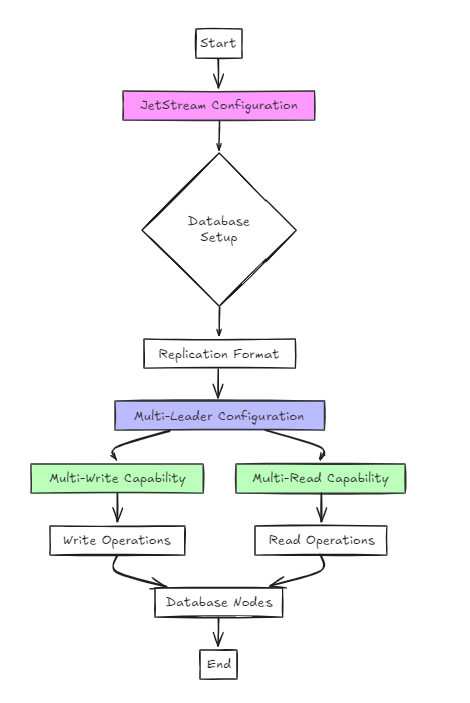
يستخدم النهج الثاني JetStream للتكوين.
في حين أن هذا أبسط من الناحية المعمارية من النهج السابق ، من وجهة نظر المستخدم ، فإن الإعداد لا يختلف اختلافًا كبيرًا عن الطوافة.
ومع ذلك ، فإن الفرق الرئيسي هو أنه ، على عكس الطوافة ، فإنه يدعم التكوينات متعددة الكبار والمتعددة القراءة ، بدلاً من القراءة الواحدة والكتابة.
في هذا النهج ، يتم تكوين قاعدة البيانات بتنسيق النسخ المتماثل ، ويتم استخدام JetStream لتمكين التكوينات متعددة القتلى.
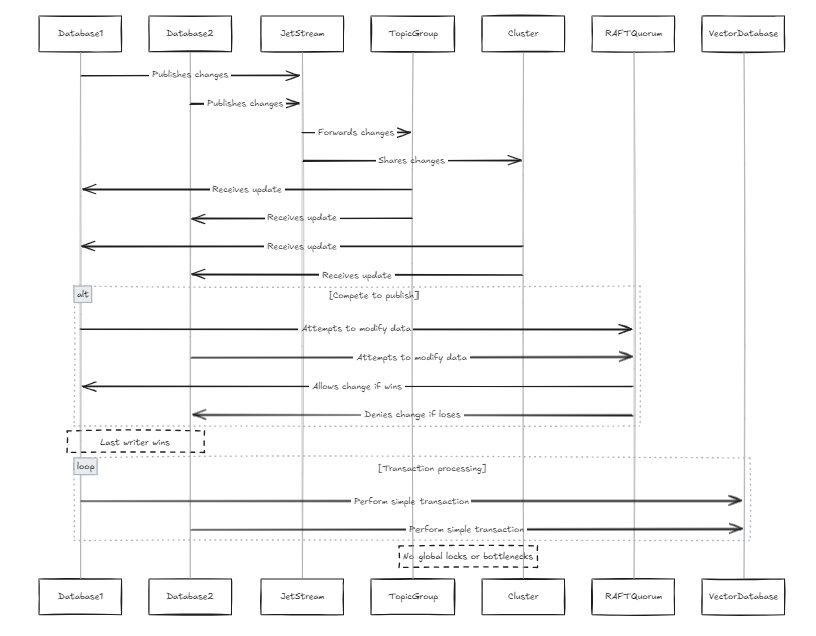 تحتوي كل قاعدة بيانات على JetStream الخاصة بها ، وتنضم هذه JetStreams إلى نفس المجموعة من الموضوعات والمجموعات. في هذه الحالة ، كلما حاولت جميع العقد نشر التغييرات على صف ، تمر عبر نفس JetStream. إذا حاولت العقدان تعديل نفس البيانات بالتوازي ، فسوف تتنافس لنشر تغييراتهما. على الرغم من أنه من الممكن منع التغييرات من الانتشار ، فقد يؤدي ذلك إلى فقدان البيانات. وفقًا لقيود النصاب الرافعة في JetStream ، يمكن للكاتب الوحيد أن ينشر التغيير. لذلك ، قمنا بتصميم النظام للسماح للكاتب الأخير بالفوز. هذه ليست مشكلة لقواعد بيانات المتجهات لأنه ، بالمقارنة مع قواعد البيانات التقليدية ، يكون بنية البيانات أكثر بساطة (هذا لا يعني أن النظام نفسه بسيط ، بل هناك عدد أقل من المعاملات والإجراءات المعقدة ، مثل تسلسل المعاملات). هذا يتجنب أيضا الأقفال العالمية واختناقات الأداء.
تحتوي كل قاعدة بيانات على JetStream الخاصة بها ، وتنضم هذه JetStreams إلى نفس المجموعة من الموضوعات والمجموعات. في هذه الحالة ، كلما حاولت جميع العقد نشر التغييرات على صف ، تمر عبر نفس JetStream. إذا حاولت العقدان تعديل نفس البيانات بالتوازي ، فسوف تتنافس لنشر تغييراتهما. على الرغم من أنه من الممكن منع التغييرات من الانتشار ، فقد يؤدي ذلك إلى فقدان البيانات. وفقًا لقيود النصاب الرافعة في JetStream ، يمكن للكاتب الوحيد أن ينشر التغيير. لذلك ، قمنا بتصميم النظام للسماح للكاتب الأخير بالفوز. هذه ليست مشكلة لقواعد بيانات المتجهات لأنه ، بالمقارنة مع قواعد البيانات التقليدية ، يكون بنية البيانات أكثر بساطة (هذا لا يعني أن النظام نفسه بسيط ، بل هناك عدد أقل من المعاملات والإجراءات المعقدة ، مثل تسلسل المعاملات). هذا يتجنب أيضا الأقفال العالمية واختناقات الأداء.
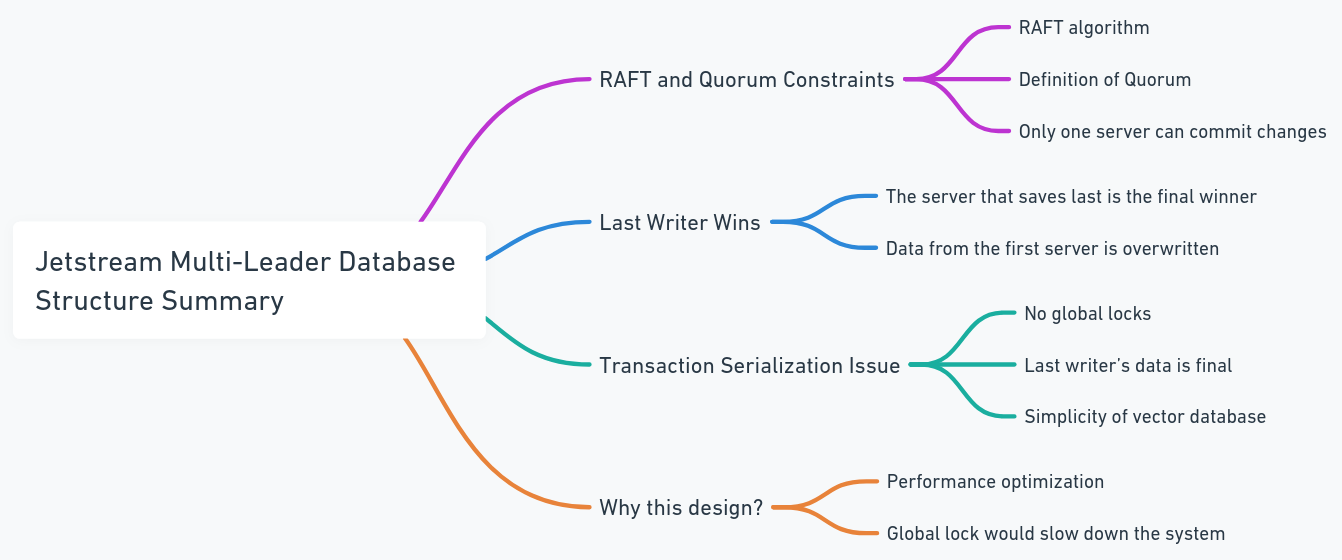
عرض الهندسة المعمارية القديمة
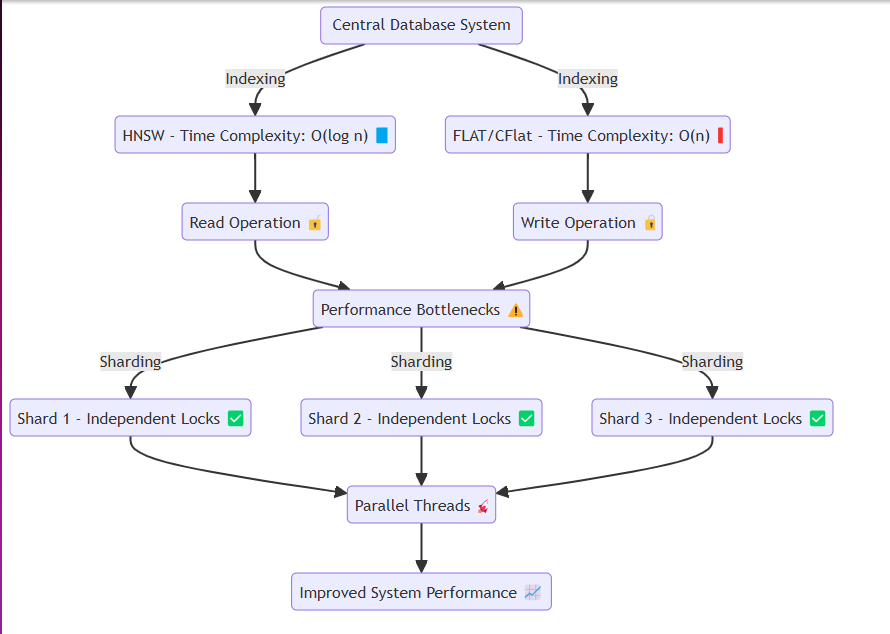 عادةً ما تصل أنظمة مثل قواعد البيانات إلى نفس الذاكرة أو القرص ، وتنفيذ عمليات القراءة والكتابة بشكل متكرر. في هذه العملية ، يمكن لطرق مثل HNSW تحقيق تعقيدات زمنية فعالة مثل O (log n) . ومع ذلك ، فإن التقنيات التي تتطلب دقة ، مثل Flat و CFLAT ، تنفذ عمليات البحث الخطية عمومًا بتعقيد زمني لـ O (N) .
عادةً ما تصل أنظمة مثل قواعد البيانات إلى نفس الذاكرة أو القرص ، وتنفيذ عمليات القراءة والكتابة بشكل متكرر. في هذه العملية ، يمكن لطرق مثل HNSW تحقيق تعقيدات زمنية فعالة مثل O (log n) . ومع ذلك ، فإن التقنيات التي تتطلب دقة ، مثل Flat و CFLAT ، تنفذ عمليات البحث الخطية عمومًا بتعقيد زمني لـ O (N) .
تنشأ المشكلة عند تجنب خلاف البيانات. عند القراءة أو الكتابة ، تقوم خيوط مثل goroutines بعزل الموارد المعنية من خلال الأقفال. خاصة:
لمعالجة هذا ، قمنا بتصميم النظام لإنشاء شظايا في الذاكرة بكفاءة وتعيين البيانات لكل قشرة دون فقدان جوهر النظام. تتميز كل قشرة بآلية قفل تسمح بما يلي:
إصدار قفل أسرع : عند إدخال كميات كبيرة من البيانات أو إجراء عمليات القراءة. إدخال البيانات المقسمة : تسهيل عمليات النظام السلس من خلال السماح بإدراج البيانات في قطاعات مقسمة. يضمن هذا التصميم أن النظام يمكن أن يعمل بسلاسة حتى تحت إدخال البيانات الثقيلة أو سيناريوهات طلب القراءة العالية ، وبالتالي تخفيف اختناقات الأداء.
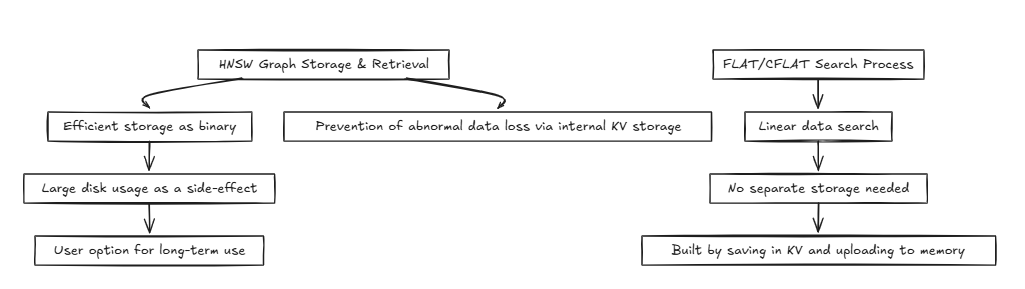
HNSW (عالم صغير قابل للملاحة):
مسطح/cflat (مسطح مركب):
CFLAT (مسطح مركب) هي طريقة فهرسة تبحث عن متجهات متعددة وتنتج نتائج مركبة بناءً على أهمية متجهين.
يعد تطبيق Search Composite Vector على خوارزميات الرسم البياني مثل HNSW أمرًا صعبًا لأنه يتطلب قدرًا كبيرًا من الذاكرة ولا يتماشى بشكل جيد مع هياكل الحي ، مما يستلزم الرسوم البيانية المتعددة. على الرغم من أن التعقيد الزمني للبحث لا يزال يتقارب مع O (2 log n) ≈ o (log n) ، فإن تعقيد الفضاء ضعيف إلى حد كبير.
تصبح هذه المشكلات مشكلة متزايدة مع نمو كمية البيانات. بالإضافة إلى ذلك ، تتجاهل طريقة دمج وتقييم المفاتيح المركبة داخل بنية الرسم البياني TopK وتزيد بشكل كبير من حجم الكومة لبحث واحد.
لذلك ، اخترنا المعالجة على أساس شقة. على الرغم من أن التعقيد الزمني هو O (n) (دون أي قطرات ثابتة) ، فإن تعقيد الفضاء يظل كما هو مسطح ، وهو فعال للغاية لدمج وتقييم المفاتيح المركبة.
Magine نحن نقوم بتطوير خدمة لشركة صناعة التوفيق التي تساعد المستخدمين في العثور على شركائهم المثاليين بناءً على معايير الإدخال. سندرس عوامل مختلفة مثل الشخصية والسمات الأخرى. ومع ذلك ، فإن استخدام ناقل واحد يعني الجمع بين هذه العوامل في جملة واحدة للبحث ، مما يزيد بشكل كبير من احتمال تشويه الدقة.
على سبيل المثال: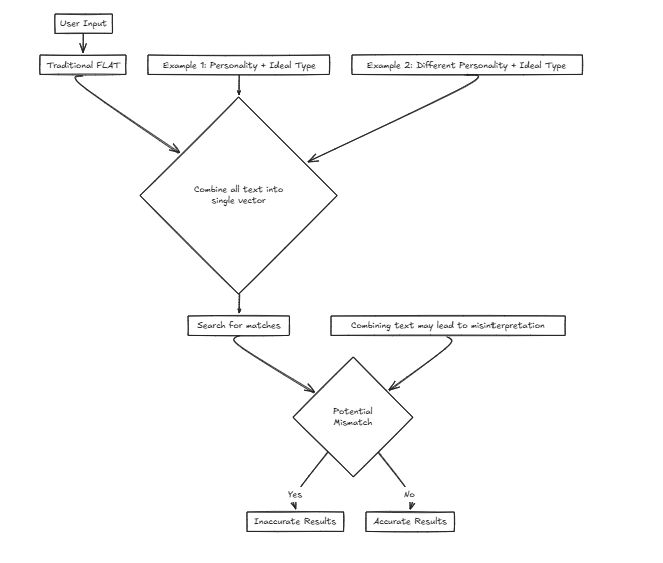 السمات المرغوبة: {الشخصية: الحاسمة ، النوع المثالي: طويل القامة ونحيف} في هذا السيناريو ، يفضل المستخدم سمة شخصية تجعل النوع المثالي من المحتمل أن يقدره ، مع التركيز على العثور على شريك بناءً على سمات خارجية.
السمات المرغوبة: {الشخصية: الحاسمة ، النوع المثالي: طويل القامة ونحيف} في هذا السيناريو ، يفضل المستخدم سمة شخصية تجعل النوع المثالي من المحتمل أن يقدره ، مع التركيز على العثور على شريك بناءً على سمات خارجية.
ومع ذلك ، فكر في حالة أخرى:
السمات المرغوبة: {الشخصية: سهلة ، النوع المثالي: حاسم} هنا ، قد يؤدي الشخص الذي يريد شخصية سهلة المقترنة بنوع مثالي حاسم إلى تطابقات غير صحيحة ، مثل المطابقة مع الأفراد الحاسمين بطرق لا تتماشى مع تفضيلات المستخدم الحقيقية.
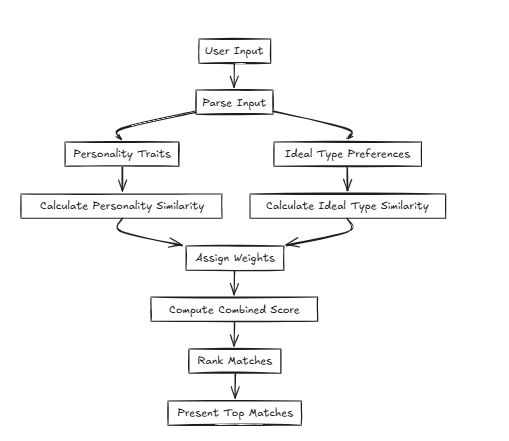 في مثل هذه الحالات ، يحسب CFLAT (مسطح مركب) الدرجات عن طريق تقييم مشترك بين التشابه في الشخصية والتشابه في النوع المثالي. يمكن للمستخدمين تعيين مستويات أهمية لكل سمة ، مما يتيح إعطاء درجات أعلى للجوانب مع تشابه أكبر بناءً على أولويات محددة من قبل المستخدم.
في مثل هذه الحالات ، يحسب CFLAT (مسطح مركب) الدرجات عن طريق تقييم مشترك بين التشابه في الشخصية والتشابه في النوع المثالي. يمكن للمستخدمين تعيين مستويات أهمية لكل سمة ، مما يتيح إعطاء درجات أعلى للجوانب مع تشابه أكبر بناءً على أولويات محددة من قبل المستخدم.
يشير Edge إلى القدرة على نقل واستقبال البيانات على الأجهزة القريبة دون اتصال مع خادم مركزي. ومع ذلك ، في الممارسة العملية ، قد تختلف "Edge" في البرامج في بعض الأحيان عن هذا المفهوم ، حيث يتم نشره غالبًا في بيئات أخف وزناً مكونة من الموارد مقارنة بالخادم المركزي.
تم تصميم NNV-Edge للعمل بسرعة على مجموعات بيانات المتجهات الأصغر على نطاق (ما يصل إلى مليون متجه) بطريقة خفيفة الوزن ، مما يؤدي إلى نقل المهام الآلية من NNV الأصلي إلى المستخدم لتحكم أكبر.
خوارزميات متقدمة مثل HNSW و FAISS و LIGHT ممتازة ، ولكن ألا تعتقد أنها قد تكون ثقيلة بعض الشيء بالنسبة للمواصفات الأصغر حجماً؟ وتخصيص الخوارزميات جانباً ، في حين أن مشاريع مثل Milvus و Weaviate و QDrant تم تصميمها من قبل العقول الرائعة ، أليس من المكثفات إلى حد ما للموارد التي لا يمكن تشغيلها إلى جانب البرامج الأخرى على الأجهزة الصغيرة المحمولة؟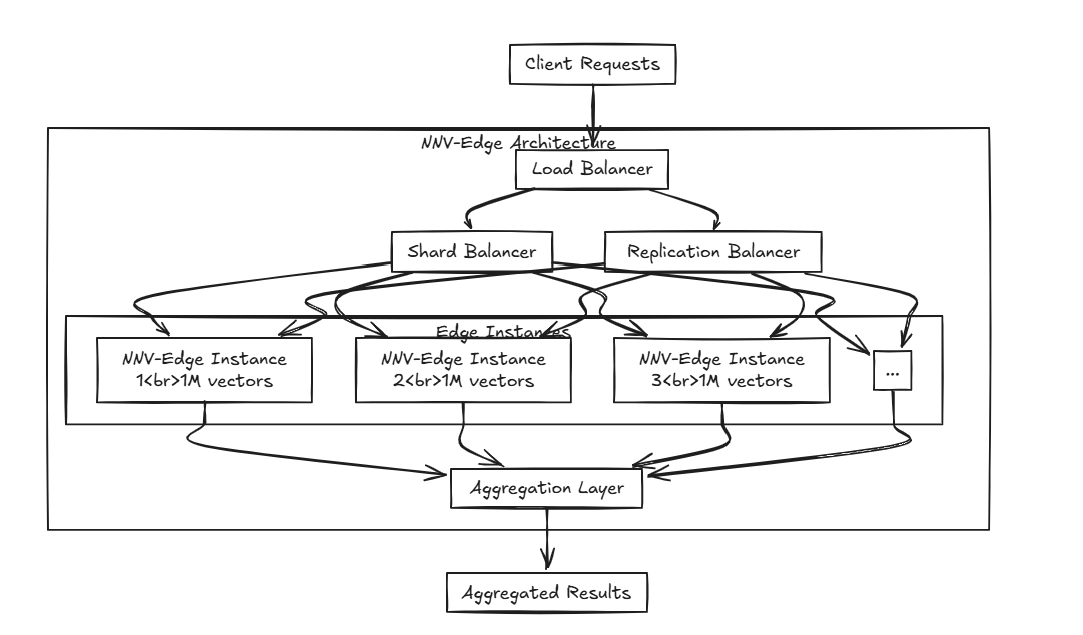 هذا هو المكان الذي يأتي فيه NNV Edge.
هذا هو المكان الذي يأتي فيه NNV Edge.
ماذا لو قمت بتوزيع حواف متعددة؟ باستخدام NNV-EDGE مع موازن التحميل المذكور مسبقًا ، يمكنك إنشاء إعداد متقدم يقود البيانات عبر حواف متعددة ويجمعه بسلاسة!


