nnv
1.0.0

NNV (no-named.v) เป็นฐานข้อมูลที่ออกแบบมาเพื่อนำไปใช้ตั้งแต่เริ่มต้นจนถึงการผลิต NNV สามารถปรับใช้ในสภาพแวดล้อมขอบและใช้ในการตั้งค่าการผลิตขนาดเล็ก ด้วยวิธีการทางสถาปัตยกรรมที่เป็นนวัตกรรมที่อธิบายไว้ด้านล่างมีการคาดการณ์และพัฒนาขึ้นเพื่อใช้อย่างน่าเชื่อถือในสภาพแวดล้อมการผลิตขนาดใหญ่เช่นกัน
สำหรับประวัติการอัปเดตแบบเต็มให้ดูประวัติอัปเดต
เราวางแผนที่จะสนับสนุน CFLAT ซึ่งสามารถอำนวยความสะดวกในการบริการที่หลากหลายผ่านการดำเนินงานที่ซับซ้อนมากขึ้นซึ่งเปิดใช้งานการค้นหาหลายเวกเตอร์ CFLAT เป็นเพียงชื่อที่ฉันประกาศเกียรติคุณ โปรดรับทราบ!
ประสิทธิภาพอาจลดลงชั่วคราวเนื่องจากการพัฒนาอย่างต่อเนื่อง ขอบคุณสำหรับความอดทน!
Windows & Linux
git clone https://github.com/sjy-dv/nnv
cd nnv
# start edge
go run cmd/root/main.go -mode=edge
# start core
go run cmd/root/main.go -mode=root
MacOS
** The CPU acceleration (SSE, AVX2, AVX-512) code has caused an error where it does not function on Mac, and it is not a priority to address at this time. **
git clone https://github.com/sjy-dv/nnv
cd nnv
source .env
deploy
make edge-dockerคุณสมบัติ
สถาปัตยกรรม
การแก้ไขข้อผิดพลาด
เมื่อวางแผนโครงการนี้ฉันให้ความคิดมากมาย
เมื่อตั้งค่าสภาพแวดล้อมของคลัสเตอร์มันเป็นเรื่องธรรมดาสำหรับนักพัฒนาส่วนใหญ่ที่จะเลือกอัลกอริทึมแพอย่างที่ฉันเคยทำมาก่อน เหตุผลที่เป็นวิธีการพิสูจน์ที่ใช้โดยโครงการที่ประสบความสำเร็จ
อย่างไรก็ตามฉันเริ่มสงสัย: มันซับซ้อนไปหน่อยเหรอ? แพเพิ่มความพร้อมใช้งานการอ่าน แต่ลดความพร้อมใช้งานการเขียน ดังนั้นฉันจะแก้ปัญหานี้ได้อย่างไรหากมีการเขียนหลายครั้งในระยะยาว?
เมื่อพิจารณาถึงลักษณะของฐานข้อมูลเวกเตอร์ฉันคิดว่าบริการส่วนใหญ่จะมีโครงสร้างรอบงานแบบแบตช์มากกว่าการเขียนแบบเรียลไทม์ แต่นั่นหมายความว่าฉันสามารถข้ามการแก้ไขปัญหาได้หรือไม่? ฉันไม่คิดอย่างนั้น อย่างไรก็ตามการสร้างการตั้งค่าหลายผู้นำที่ด้านบนของแพโดยใช้บางสิ่งเช่นซุบซิบรู้สึกซับซ้อนและยากมาก 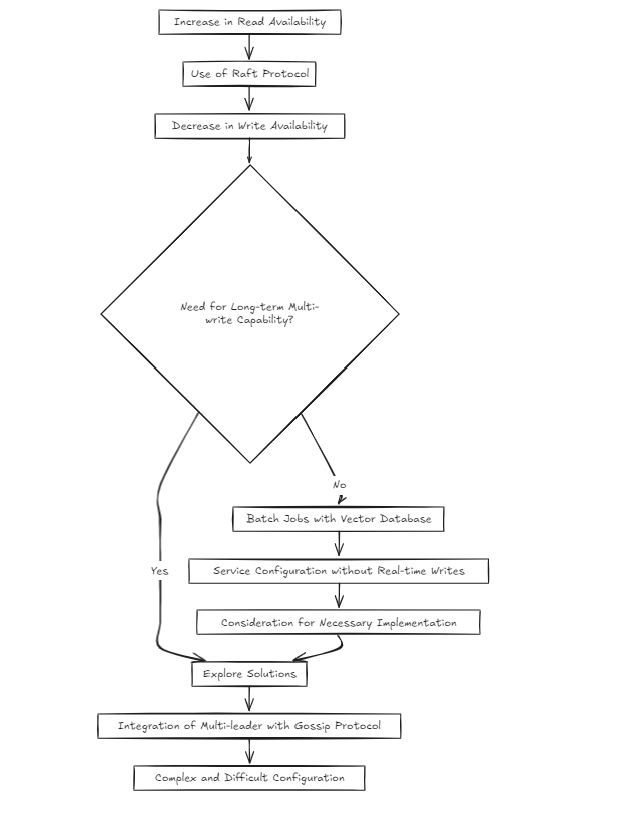
ดังนั้น ณ วันนี้ (2024-10-20) ฉันกำลังพิจารณาวิธีการทางสถาปัตยกรรมสองวิธี
สถาปัตยกรรมแบ่งออกเป็นสองวิธี
ก่อนอื่นตัวโหลดบัลแลนเซอร์จะถูกวางไว้ที่ด้านหน้ารองรับทั้งการแตกและการรวมข้อมูล ฐานข้อมูลภายในมีอยู่ในสถานะบริสุทธิ์
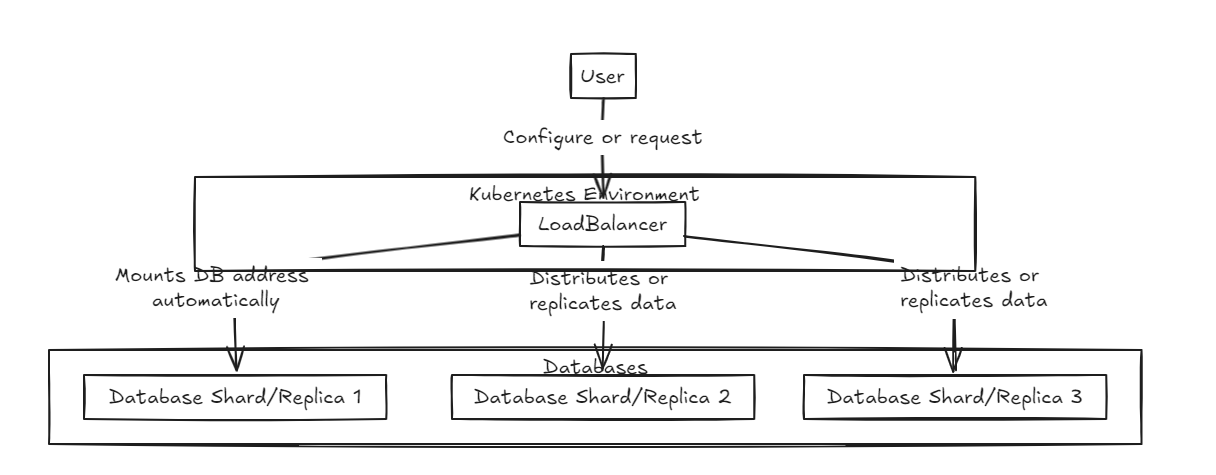 |  |
|---|---|
| แบบจำลอง LB | Shard LB |
การจำลองแบบโหลดบัลแลนเซอร์รอให้ฐานข้อมูลทั้งหมดเสร็จสิ้นการเขียนสำเร็จก่อนที่จะส่งหรือย้อนกลับในขณะที่เครื่องบาลานซ์โหลดชิ้นส่วนกระจายโหลดอย่างสม่ำเสมอทั่วทั้งฐานข้อมูลชาร์ดเพื่อให้แน่ใจว่ามีความสามารถในการจัดเก็บที่คล้ายกัน
ความแตกต่างที่สำคัญคือการจำลองแบบสามารถชะลอการทำงานของการเขียน แต่ให้ประสิทธิภาพการอ่านที่เร็วขึ้นในระยะกลางถึงระยะยาวเมื่อเทียบกับเครื่องบาลานซ์โหลด ในทางกลับกันวิธีการของ Shard มีความเร็วในการเขียนที่เร็วขึ้นเพราะมันมุ่งมั่นที่จะใช้กับเศษเล็กเศษน้อยเท่านั้น แต่การอ่านต้องมีการรวบรวมข้อมูลจากเศษทั้งหมดซึ่งช้ากว่าในตอนแรก แต่อาจกลายเป็นเร็วกว่าการจำลองแบบเมื่อชุดข้อมูลเติบโตขึ้น
ดังนั้นสำหรับการจัดการข้อมูลจำนวนมากขอแนะนำให้มีการแนะนำ Shard Balancer มากกว่าเล็กน้อย อย่างไรก็ตามประเด็นหลักของสถาปัตยกรรมทั้งสองคือความเรียบง่ายในการตั้งค่าและการจัดการทำให้ง่ายต่อการจัดการเป็นเซิร์ฟเวอร์แบ็กเอนด์ทั่วไป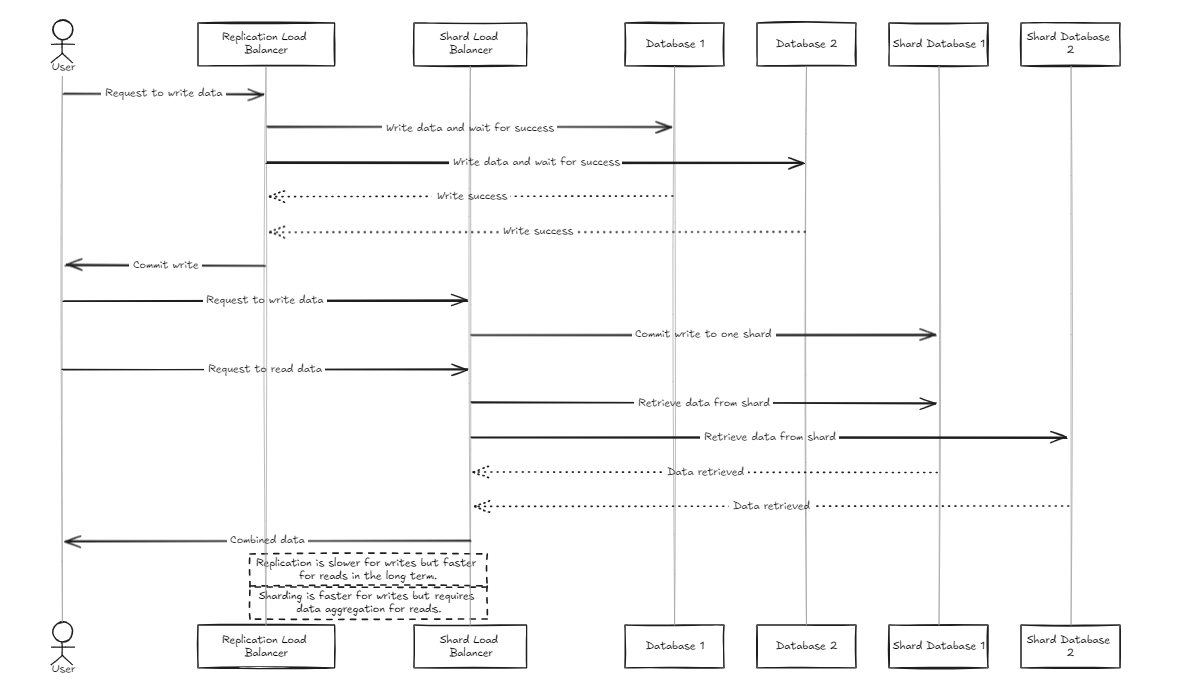
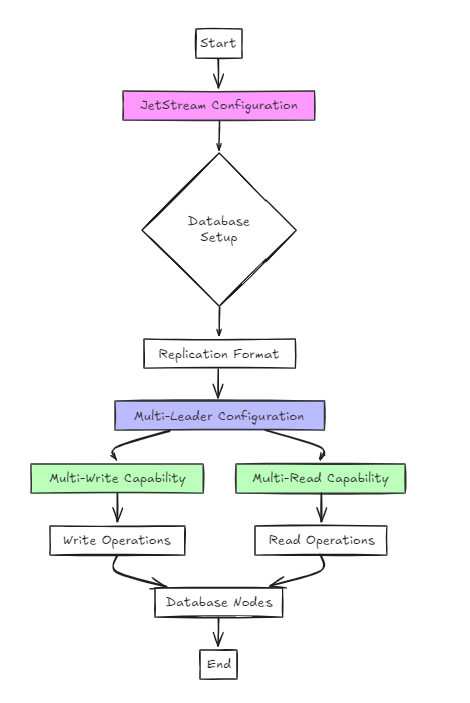
วิธีที่สองใช้ jetstream สำหรับการกำหนดค่า
แม้ว่าสิ่งนี้จะง่ายกว่าวิธีการทางสถาปัตยกรรมก่อนหน้านี้จากมุมมองของผู้ใช้การตั้งค่าไม่แตกต่างจากแพอย่างมีนัยสำคัญ
อย่างไรก็ตามความแตกต่างที่สำคัญคือแตกต่างจาก RAFT รองรับการกำหนดค่ามัลติเขียนและมัลติอ่านมากกว่าการเขียนเดี่ยวและมัลติอ่าน
ในวิธีการนี้ฐานข้อมูลได้รับการกำหนดค่าในรูปแบบการจำลองแบบและ Jetstream ใช้เพื่อเปิดใช้งานการกำหนดค่าหลายผู้นำ
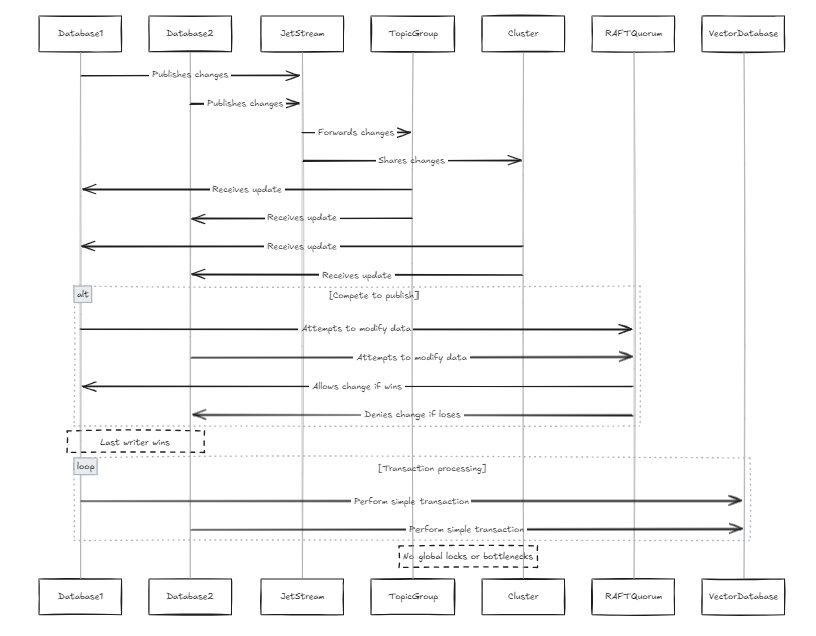 แต่ละฐานข้อมูลมี Jetstream ของตัวเองและ Jetstreams เหล่านี้เข้าร่วมกลุ่มและกลุ่มกลุ่มเดียวกัน ในกรณีนี้เมื่อใดก็ตามที่โหนดทั้งหมดพยายามเผยแพร่การเปลี่ยนแปลงเป็นแถวพวกเขาจะผ่าน Jetstream เดียวกัน หากสองโหนดพยายามแก้ไขข้อมูลเดียวกันในแบบคู่ขนานพวกเขาจะแข่งขันเพื่อเผยแพร่การเปลี่ยนแปลงของพวกเขา ในขณะที่เป็นไปได้ที่จะป้องกันการเปลี่ยนแปลงจากการแพร่กระจายสิ่งนี้อาจนำไปสู่การสูญเสียข้อมูล ตามข้อ จำกัด ของ Raft Quorum ใน Jetstream มีเพียงนักเขียนเพียงคนเดียวเท่านั้นที่สามารถเผยแพร่การเปลี่ยนแปลงได้ ดังนั้นเราจึงออกแบบระบบเพื่อให้นักเขียนคนสุดท้ายชนะ นี่ไม่ใช่ปัญหาสำหรับฐานข้อมูลเวกเตอร์เพราะเมื่อเทียบกับฐานข้อมูลดั้งเดิมโครงสร้างข้อมูลนั้นง่ายกว่า (นี่ไม่ได้หมายความว่าระบบนั้นง่าย แต่มีธุรกรรมและขั้นตอนที่ซับซ้อนน้อยลงเช่นการทำธุรกรรมต่อเนื่อง) นอกจากนี้ยังหลีกเลี่ยงการล็อคทั่วโลกและคอขวดประสิทธิภาพ
แต่ละฐานข้อมูลมี Jetstream ของตัวเองและ Jetstreams เหล่านี้เข้าร่วมกลุ่มและกลุ่มกลุ่มเดียวกัน ในกรณีนี้เมื่อใดก็ตามที่โหนดทั้งหมดพยายามเผยแพร่การเปลี่ยนแปลงเป็นแถวพวกเขาจะผ่าน Jetstream เดียวกัน หากสองโหนดพยายามแก้ไขข้อมูลเดียวกันในแบบคู่ขนานพวกเขาจะแข่งขันเพื่อเผยแพร่การเปลี่ยนแปลงของพวกเขา ในขณะที่เป็นไปได้ที่จะป้องกันการเปลี่ยนแปลงจากการแพร่กระจายสิ่งนี้อาจนำไปสู่การสูญเสียข้อมูล ตามข้อ จำกัด ของ Raft Quorum ใน Jetstream มีเพียงนักเขียนเพียงคนเดียวเท่านั้นที่สามารถเผยแพร่การเปลี่ยนแปลงได้ ดังนั้นเราจึงออกแบบระบบเพื่อให้นักเขียนคนสุดท้ายชนะ นี่ไม่ใช่ปัญหาสำหรับฐานข้อมูลเวกเตอร์เพราะเมื่อเทียบกับฐานข้อมูลดั้งเดิมโครงสร้างข้อมูลนั้นง่ายกว่า (นี่ไม่ได้หมายความว่าระบบนั้นง่าย แต่มีธุรกรรมและขั้นตอนที่ซับซ้อนน้อยลงเช่นการทำธุรกรรมต่อเนื่อง) นอกจากนี้ยังหลีกเลี่ยงการล็อคทั่วโลกและคอขวดประสิทธิภาพ
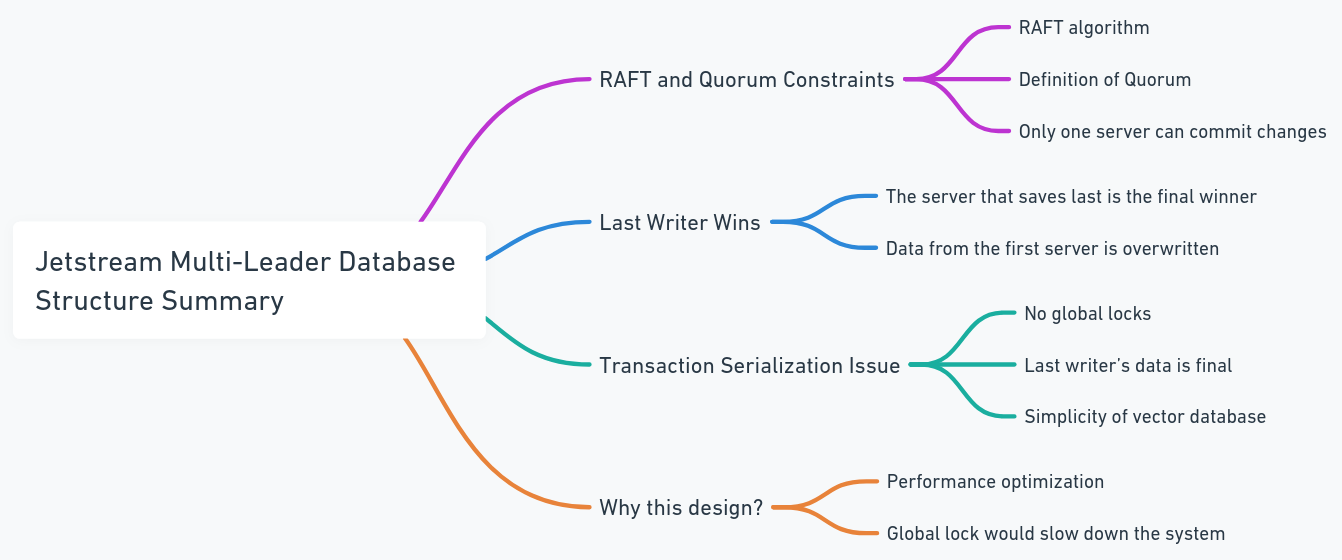
ดูสถาปัตยกรรมเก่า
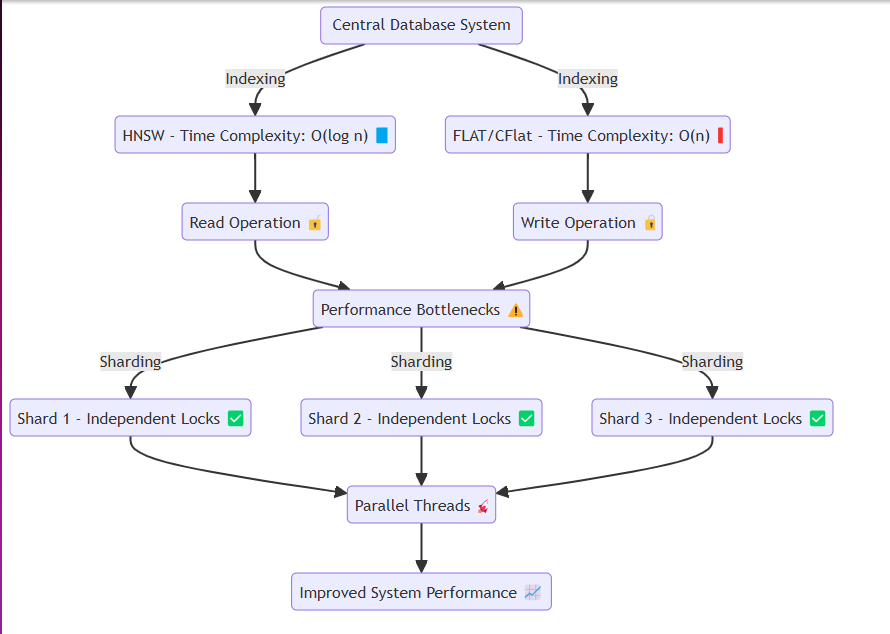 โดยทั่วไปแล้วระบบเช่นฐานข้อมูลเข้าถึงหน่วยความจำหรือดิสก์เดียวกันทำการดำเนินการอ่านและเขียนซ้ำ ๆ ในกระบวนการนี้วิธีการเช่น HNSW สามารถบรรลุความซับซ้อนของเวลาที่มีประสิทธิภาพเช่น O (log n) อย่างไรก็ตามเทคนิคที่ต้องใช้ความแม่นยำเช่นแบนและ CFLAT โดยทั่วไปจะดำเนินการค้นหาเชิงเส้นด้วยความซับซ้อนของเวลาของ O (n)
โดยทั่วไปแล้วระบบเช่นฐานข้อมูลเข้าถึงหน่วยความจำหรือดิสก์เดียวกันทำการดำเนินการอ่านและเขียนซ้ำ ๆ ในกระบวนการนี้วิธีการเช่น HNSW สามารถบรรลุความซับซ้อนของเวลาที่มีประสิทธิภาพเช่น O (log n) อย่างไรก็ตามเทคนิคที่ต้องใช้ความแม่นยำเช่นแบนและ CFLAT โดยทั่วไปจะดำเนินการค้นหาเชิงเส้นด้วยความซับซ้อนของเวลาของ O (n)
ปัญหาเกิดขึ้นเมื่อหลีกเลี่ยงการโต้แย้งข้อมูล เมื่ออ่านหรือเขียนเธรดเช่น goroutines จะแยกทรัพยากรที่เกี่ยวข้องผ่านล็อค โดยเฉพาะ:
เพื่อแก้ไขปัญหานี้เราได้ออกแบบระบบเพื่อสร้างเศษในหน่วยความจำอย่างมีประสิทธิภาพและกำหนดข้อมูลให้กับแต่ละชิ้นโดยไม่สูญเสียสาระสำคัญของระบบ แต่ละชิ้นมีกลไกการล็อคที่อนุญาต:
การล็อคที่เร็วขึ้น : เมื่อแทรกข้อมูลจำนวนมากหรือดำเนินการอ่าน การแทรกข้อมูลที่แบ่งพาร์ติชัน : อำนวยความสะดวกในการดำเนินการระบบที่ราบรื่นโดยอนุญาตให้ข้อมูลแทรกเข้าไปในส่วนที่แบ่งออก การออกแบบนี้ช่วยให้มั่นใจได้ว่าระบบสามารถทำงานได้อย่างราบรื่นแม้ภายใต้การแทรกข้อมูลหนักหรือสถานการณ์คำขออ่านสูงซึ่งจะช่วยลดปัญหาคอขวด
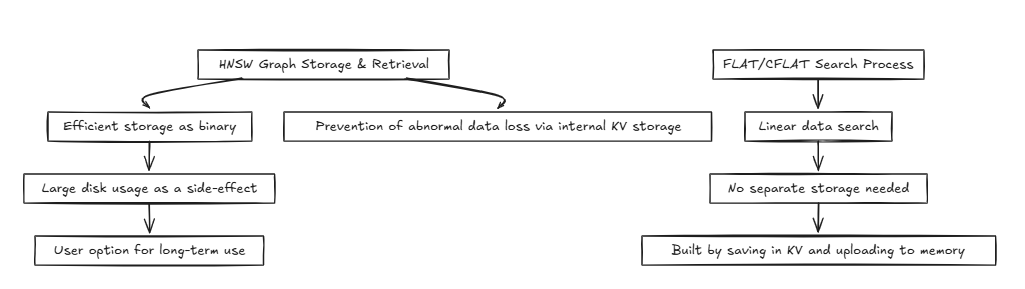
HNSW (โลกขนาดเล็กที่นำทางได้ตามลำดับชั้น):
แบน/cflat (คอมโพสิตแบน):
CFLAT (คอมโพสิตแฟลต) เป็นวิธีการจัดทำดัชนีที่ค้นหาเวกเตอร์หลายตัวและให้ผลลัพธ์คอมโพสิตตามความสำคัญของเวกเตอร์สองตัว
การใช้การค้นหาเวกเตอร์คอมโพสิตกับอัลกอริทึมกราฟเช่น HNSW นั้นเป็นสิ่งที่ท้าทายเพราะต้องใช้หน่วยความจำจำนวนมากและไม่สอดคล้องกับโครงสร้างพื้นที่ใกล้เคียงซึ่งจำเป็นต้องใช้กราฟหลายกราฟ แม้ว่าความซับซ้อนของเวลาสำหรับการค้นหายังคงมาบรรจบกันกับ O (2 log n) ≈ O (log n) ความซับซ้อนของอวกาศนั้นแย่มาก
ปัญหาเหล่านี้กลายเป็นปัญหามากขึ้นเมื่อปริมาณข้อมูลเพิ่มขึ้น นอกจากนี้วิธีการรวมและประเมินผลตามคีย์คอมโพสิตภายในโครงสร้างกราฟจะไม่สนใจ TOPK และเพิ่มขนาดฮีปอย่างมีนัยสำคัญสำหรับการค้นหาครั้งเดียว
ดังนั้นเราจึงเลือกที่จะดำเนินการตามแฟลต แม้ว่าความซับซ้อนของเวลาคือ O (n) (โดยไม่มีการลดลงอย่างต่อเนื่อง) ความซับซ้อนของพื้นที่ยังคงเหมือนเดิมและมีประสิทธิภาพสูงสำหรับการรวมและการประเมินผลตามคีย์คอมโพสิต
Magine เรากำลังพัฒนาบริการสำหรับ บริษัท การจับคู่ที่ช่วยให้ผู้ใช้ค้นหาพันธมิตรในอุดมคติของพวกเขาตามเกณฑ์การป้อนข้อมูล เราจะพิจารณาปัจจัยต่าง ๆ เช่นบุคลิกภาพและคุณลักษณะอื่น ๆ อย่างไรก็ตามการใช้เวกเตอร์เดียวหมายถึงการรวมปัจจัยเหล่านี้เป็นหนึ่งประโยคสำหรับการค้นหาซึ่งจะเพิ่มโอกาสในการบิดเบือนความแม่นยำอย่างมาก
ตัวอย่างเช่น: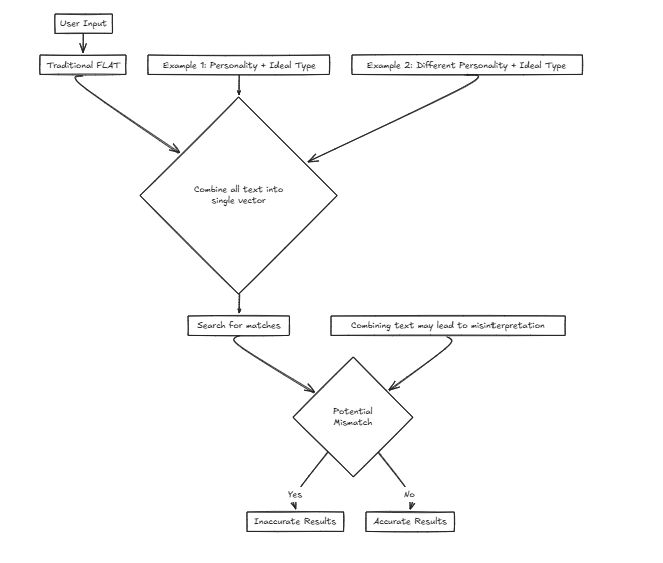 ลักษณะที่ต้องการ: {บุคลิกภาพ: เด็ดขาดประเภทอุดมคติ: สูงและผอม} ในสถานการณ์นี้ผู้ใช้ชอบลักษณะบุคลิกภาพที่ทำให้คนในอุดมคติคนน่าจะชื่นชมพวกเขาโดยมุ่งเน้นไปที่การค้นหาพันธมิตรตามคุณลักษณะภายนอก
ลักษณะที่ต้องการ: {บุคลิกภาพ: เด็ดขาดประเภทอุดมคติ: สูงและผอม} ในสถานการณ์นี้ผู้ใช้ชอบลักษณะบุคลิกภาพที่ทำให้คนในอุดมคติคนน่าจะชื่นชมพวกเขาโดยมุ่งเน้นไปที่การค้นหาพันธมิตรตามคุณลักษณะภายนอก
อย่างไรก็ตามพิจารณากรณีอื่น:
ลักษณะที่ต้องการ: {บุคลิกภาพ: ง่าย ๆ ประเภทอุดมคติ: เด็ดขาด} ที่นี่ใครบางคนที่ต้องการบุคลิกที่ง่าย ๆ ที่จับคู่กับประเภทในอุดมคติที่เด็ดขาดอาจส่งผลให้เกิดการแข่งขันที่ไม่ถูกต้องเช่นการจับคู่กับบุคคลที่แตกต่างกันในวิธีที่ไม่สอดคล้องกับการตั้งค่าที่แท้จริงของผู้ใช้
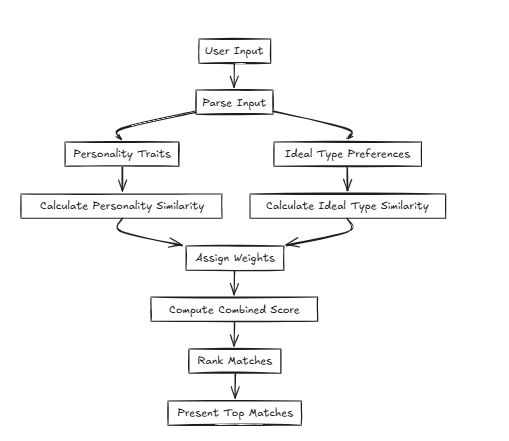 ในกรณีเช่นนี้ CFLAT (คอมโพสิตแฟลต) จะคำนวณคะแนนโดยการประเมินความคล้ายคลึงกันในบุคลิกภาพและความคล้ายคลึงกันในประเภทอุดมคติ ผู้ใช้สามารถกำหนดระดับความสำคัญให้กับแต่ละแอตทริบิวต์ช่วยให้คะแนนที่สูงขึ้นจะได้รับในแง่มุมที่มีความคล้ายคลึงกันมากขึ้นตามลำดับความสำคัญที่ผู้ใช้กำหนด
ในกรณีเช่นนี้ CFLAT (คอมโพสิตแฟลต) จะคำนวณคะแนนโดยการประเมินความคล้ายคลึงกันในบุคลิกภาพและความคล้ายคลึงกันในประเภทอุดมคติ ผู้ใช้สามารถกำหนดระดับความสำคัญให้กับแต่ละแอตทริบิวต์ช่วยให้คะแนนที่สูงขึ้นจะได้รับในแง่มุมที่มีความคล้ายคลึงกันมากขึ้นตามลำดับความสำคัญที่ผู้ใช้กำหนด
Edge หมายถึงความสามารถในการส่งและรับข้อมูลบนอุปกรณ์ใกล้เคียงโดยไม่ต้องสื่อสารกับเซิร์ฟเวอร์กลาง อย่างไรก็ตามในทางปฏิบัติ "Edge" ในซอฟต์แวร์บางครั้งอาจแตกต่างจากแนวคิดนี้เนื่องจากมักจะถูกปรับใช้ในสภาพแวดล้อมที่มีน้ำหนักเบาและ จำกัด ทรัพยากรเมื่อเทียบกับเซิร์ฟเวอร์กลาง
NNV-edge ได้รับการออกแบบให้ทำงานอย่างรวดเร็วในชุดข้อมูลเวกเตอร์ขนาดเล็ก (มากถึง 1 ล้านเวกเตอร์) ในลักษณะที่มีน้ำหนักเบาถ่ายโอนงานอัตโนมัติจาก NNV ดั้งเดิมกลับไปยังผู้ใช้เพื่อควบคุมมากขึ้น
อัลกอริทึมขั้นสูงเช่น HNSW, FAISS และการรบกวนนั้นยอดเยี่ยม แต่คุณไม่คิดว่าพวกเขาอาจจะหนักสำหรับรายละเอียดขนาดเล็กหรือไม่? และการแยกอัลกอริทึมในขณะที่โครงการเช่น Milvus, Weaviate และ Qdrant ถูกสร้างขึ้นโดย Minds ที่ยอดเยี่ยมพวกเขาไม่ได้ใช้ทรัพยากรมากเกินไปที่จะทำงานร่วมกับซอฟต์แวร์อื่น ๆ บนอุปกรณ์ขนาดเล็กพกพาหรือไม่?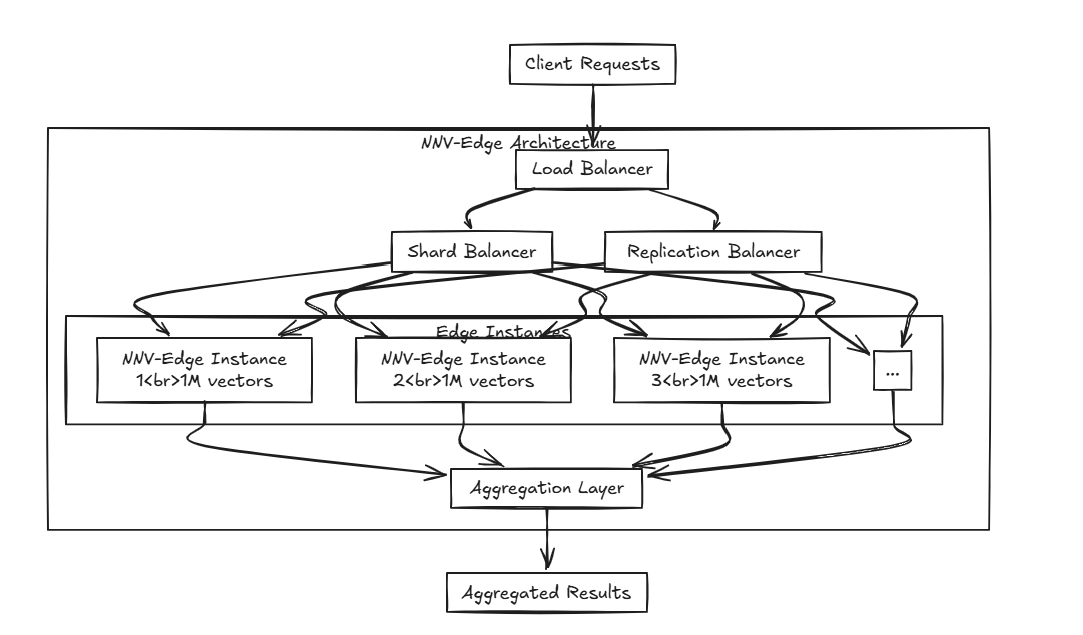 นั่นคือสิ่งที่ NNV-edge เข้ามา
นั่นคือสิ่งที่ NNV-edge เข้ามา
ถ้าคุณแจกจ่ายหลายขอบ ด้วยการใช้ NNV-Edge กับ Load Balancer ที่กล่าวถึงก่อนหน้านี้คุณสามารถสร้างการตั้งค่าขั้นสูงที่ให้ข้อมูลในหลายขอบและรวมมันอย่างราบรื่น!


