doc rag harness
1.0.0
檢索增強發電的區域正在迅速發展。實施檢索有許多不同的方法。有些人使用嵌入式和矢量數據庫,一些其他使用語義圖。因此,有不同的設計,還有不同的任務,與任務1匹配的設計很重要。
該線束的目的是提供收集定義,抽象和構建塊,以幫助理解,基準測試,比較和選擇特定的檢索設計,該設計最能匹配手頭的任務。
安全帶的目的是與技術 +技術兼容性套件(TCK)有些相似 - 提供:
Java被選為具有豐富語言和大型成熟生態系統的企業世界中的主要技術。之所以選擇EMF Ecore,是因為有功能:
此頁面提供了核心概念的介紹,並概述了幾種用例(任務)和設計(替代方案)。
下圖概述了線束結構和上下文:
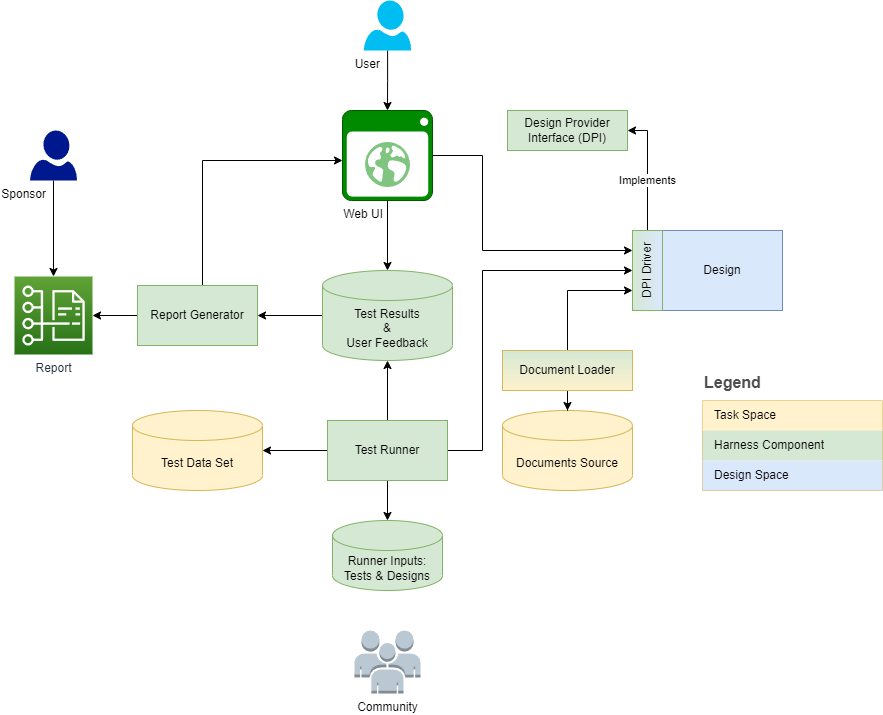
以下各節為每個定義提供了定義和概述任務/設計維度。元模型將一些定義捕獲為模型元素,並將其詳細說明,並將其詳細說明。
文檔是紀念思想或信息的代表。出於此線束文件的目的:
“物理”實現:
“邏輯”實現:
pom.xml加載到項目對像模型中,Java文件可以加載到語法樹中,也可以加載具有分析類型/字段/方法參考的圖形。將一個文檔表示形式轉換為另一個文檔。例如,PDF或OCR JSON到Swift MT 700消息的對像模型。
以特定格式或格式存儲文檔。例如帶有PDF文檔的文件系統。文檔源可以轉換/改編。文檔源的示例之一是git commit。 Nasdanika GitLab模型可用於實現GitLab的文檔加載。
提供存儲和檢索功能的文檔集合。 DPI的主要接口(見下文)由設計實現。
存儲文檔時,存儲庫可能執行諸如圖像識別之類的任務。
可能有多種檢索方式,例如:
存儲庫可以從其他存儲庫和數據加載程序組成。例如,可以從PDF->對像模型數據加載程序和對像模型存儲庫中組裝PDF存儲庫。文檔存儲庫也可能不必存儲/重新創建源文檔 - 他們可以將其引用並從文檔存儲中檢索 - 已加載文檔的原件或特定於存儲庫的文檔商店。
也有可能構成不同的存儲庫。例如,一個支持關鍵字搜索和支持語義搜索的存儲庫的存儲庫。在這種情況下,關鍵字搜索存儲庫查詢結果將是必要的,但不足,可能被用來驗證語義搜索存儲庫的結果。
用戶通過Web UI查詢文檔存儲庫。他們可以作為工作職能的一部分來做或評估特定設計的查詢功能並提供反饋。這兩種方式可能會結合在一起 - 用戶可以選擇僅使用“冠軍”查詢引擎/設計,例如關鍵字搜索,或者選擇“挑戰者”引擎/設計。
Web UI可能會捕獲用戶上下文,例如組織中的角色/位置,並將其作為查詢的一部分傳遞到設計。
有興趣通過利用文件檢索增強發電來提高用戶工作質量(例如生產率)的一方。
贊助商需要平衡多個標準,以最大程度地減少“損失函數”:
設計是技術及其配置參數的實例化/實施例。
設計變化點 - 可以在不同的實施方案/實例化和值源中更改的內容。例如:
設計維度可以形成樹,也可以更精確地形成有向圖。例如,矢量數據庫版本將是特定矢量數據庫節點下的節點。
設計提供商界面(DPI)從特定的設計實現中提取了線束。它是必須實現的一組接口和抽像類。例如DocumentRepository接口。 DPI在Java/ecore中定義,可以為不同技術提供適配器。尤其:
任務是文檔檢索的特定用途。例如,在組織特定技術文檔中的語義搜索“我如何將春季微服務部署到AKS?”。
響應的測試文檔,查詢和評估者的集合。
測試數據集 /設計組合的集合將由測試跑者執行。
測試跑步者只能根據輸入執行以上步驟的一部分。例如:
測試運行可以分佈在多個代理/機器上。
存儲測試結果和用戶反饋。測試結果和用戶反饋應參考測試數據集和設計。因此,它本質上是一個線束元數據存儲庫,其中包含設計定義樹/圖表,測試數據集定義以及測試運行的結果。
生成報告。該報告可能採用可視化的HTML格式。可能的報告格式:
報告可能包含指向Web UI甚至“主機” Web UI的鏈接,如果將其作為單頁應用程序(SPA)實現,例如React或Vue.js/Bootstrapvue
各方為線束,設計和測試數據集做出貢獻。社區成員可能會在不同的組件上扮演不同的角色。
---正在進行中的工作---
本節概述了幾個任務(用例),用於檢索增強生成和搜索。
方面:
示例 - 大型企業中的技術功能:
對於上面的每一個都有一個時間維度 - 頂部的技術堆棧更新,底部發行。有關可視化,請參見Togaf架構景觀。
在這樣的環境中,用戶需要檢索解決方案,該解決方案允許檢索特定於用戶在企業中的位置和角色的文檔及其分配的努力。例如,一名Java開發人員,例如當前的發布可能需要有關Java 17的信息。如果將同一開發人員分配為未來發布的工作,則可能需要有關Java 20的信息。當他們使用Kubernetes和Kubernetes和Azure Aks等技術時,供應商文檔可能會很大程度上是用途,但需要使用一般信息。
方面:
方面:
托多。根據行業信息,針對大量文檔 - 匹配操作文件用例
托多。對於少量文檔(過程)可能會更好 - 它們可能都適合內存,並且可以在語義圖上執行搜索。在矢量數據庫中,構建索引的一種方法是使用圖形 - 層次可導航的小世界(HNSW)
托多。可能非常適合技術文檔用例:
此過程將導致大量(數百個)相對較小的圖形/模型(知識庫),並具有數万個文檔。
圖形神經網絡的設計空間,斯坦福CS224W的演講部分:帶有圖形的ML,幻燈片↩


