doc rag harness
1.0.0
Область извлечения дополненного поколения быстро развивается. Есть много разных способов реализации поиска. Некоторые люди используют встроенные и векторные базы данных, некоторые другие используют семантические графики. Таким образом, существуют разные дизайны, а также есть разные задачи, и важно соответствовать дизайну с задачей 1 .
Цель этого жгута по предоставлению определений, абстракций и строительных блоков сбора, чтобы помочь понять, сравнивать, сравнивать и выбрать конкретный дизайн поиска, который лучше всего соответствует задаче.
Жгут предназначен для того, чтобы быть несколько похожим на набор для совместной технологии технологий (TCK) - для предоставления:
Java была выбрана в качестве доминирующей технологии в корпоративном мире с богатой выразительной силой языка и большой зрелой экосистемы. EMF Ecore был выбран, потому что есть возможности:
На этой странице представлено введение в основные концепции и описывает несколько вариантов использования (задачи) и проектов (альтернативы).
Приведенная ниже диаграмма описывает структуру и контекст жгута:
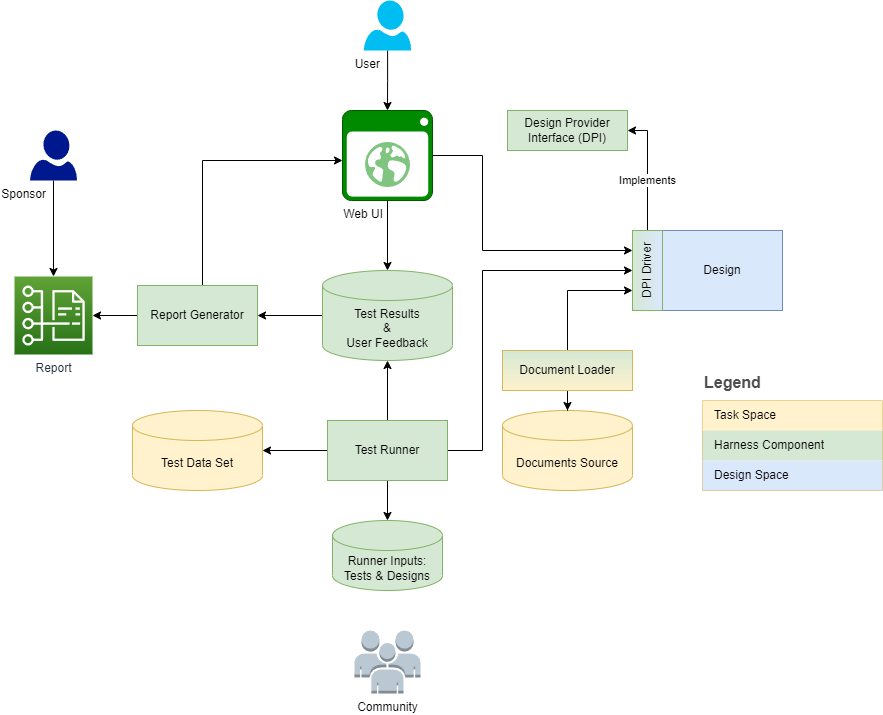
В следующих разделах предоставляются определения и измерения задач/дизайна для каждого определения. Метамодель отражает некоторые определения как модельные элементы и разрабатывает их в функции, операции и подклассы.
Документ - это увековеченное представление мысли или информации. Для целей этих документов жгута:
«Физические» реализации:
«Логические» реализации:
pom.xml может быть загружен в модель объекта проекта, файл Java может быть загружен в синтаксисное дерево или график с разрешенным типом/полевым/методом ссылок.Конвертирует одно представление документа в другой. Например, PDF или OCR JSON для объектной модели сообщения Swift MT 700.
Хранение документов в определенном формате или форматах. Например, файловая система с PDF -документами. Документы источники могут быть преобразованы/адаптированы. Одним из примеров источника документа является коммит GIT. Модель Nasdanika Gitlab может использоваться для реализации загрузки документов из Gitlab.
Коллекция документов, обеспечивающих функциональность хранения и поиска. Основной интерфейс DPI (см. Ниже), который будет реализован с помощью проектов.
При хранении документа репозиторий может выполнять такие задачи, как распознавание изображений.
Может быть несколько методов поиска, таких как:
Репозитории могут быть собраны из других репозиториев и погрузчиков данных. Например, репозиторий PDF может быть собран из загрузчика данных данных PDF -> модели объекта и репозитория объектной модели. Также документируют репозитории, возможно, не придется хранить/воссоздать исходный документ - они могут ссылаться на его и извлекать из хранилища документов - оригинал, из которого был загружен документ, или хранилище документов, специфичных для репозитория.
Также может быть возможно составить различные конструкции репозиториев. Например, репозиторий, который поддерживает поиск ключевых слов и репозиторий, который поддерживает семантический поиск. В этом случае результаты запроса поиска ключевых слов будут необходимы, но не достаточные и могут использоваться для проверки результатов репозитория семантического поиска.
Пользователи запрашивают хранилище документа через веб -интерфейс. Они могут сделать это как часть своей функции работы или оценить функциональность запроса конкретного дизайна и обеспечить обратную связь. Эти две модальности могут быть объединены - пользователи могут выбрать только «Чемпионский» двигатель/дизайн запроса, например, поиск ключевых слов или также выбрать двигатели/проекты «Challenger».
Веб -интерфейс может захватить пользовательский контекст, такой как роль/позиция в организации, и передать его дизайну как часть запроса.
Сторона, заинтересованная в улучшении качеств пользовательской работы, таких как производительность, путем использования добычи документов.
Спонсоры должны сбалансировать несколько критериев, чтобы минимизировать «функцию потери»:
Дизайн - это экземпляр/воплощение технологий и их параметры конфигурации.
Точки вариации дизайна - что можно изменить в различных вариантах осуществления/экземпляров и источника значений. Например:
Размеры дизайна могут сформировать дерево или, точнее, направленный график. Например, версии векторной базы данных будут узлами под узлом для конкретной векторной базы данных.
Интерфейс поставщика дизайна (DPI) абстрагирует жгут из конкретной реализации дизайна. Это набор интерфейсов и абстрактных классов, которые Design должен реализовать. Например, интерфейс DocumentRepository . DPI определяется в Java/Ecore и может предоставлять адаптеры для различных технологий. В частности:
Задача - это конкретное использование поиска документа. Например, семантический поиск в технической документации по конкретной организации «Как мне развернуть пружинный микросервис в AKS?».
Коллекция тестовых документов, запросов и оценщиков ответов.
Коллекция набора тестовых данных / комбинаций проектирования, выполненных тестовым бегуном.
Тестовый бегун может выполнять только части вышеуказанных шагов в зависимости от входов. Например:
Тестовые прогоны могут быть распределены по нескольким агентам/машинах.
Хранение результатов теста и отзывов пользователей. Результаты тестирования и отзывы пользователей должны ссылаться на наборы данных и конструкции тестирования. Таким образом, это, по сути, репозиторий метаданных жгута, содержащий деревья/графики определения дизайна, определения набора данных тестирования и результаты тестовых прогонов.
Генерирует отчет. Отчет может быть в формате HTML с визуализацией. Возможный формат отчета:
Отчет может содержать ссылки на веб -интерфейс или даже «Хости» веб -интерфейса, если он реализован как одно страница (SPA) с, скажем, React или Vue.js/Bootstrapvue
Стороны, способствующие жгуту, проектированию и тестированию данных. Члены сообщества могут играть разные роли на разных компонентах.
--- Работа в процессе ---
В этом разделе описывается несколько задач (варианты использования) для получения добычи и поиска в целом.
Размеры:
Пример - технологическая функция на крупном предприятии:
Для каждого из вышеперечисленных есть размер времени - обновления технического стека вверху, выпуски внизу. См. Архитектурный ландшафт TOGAF для визуализации.
В такой среде пользователям необходимо для поиска решения, которое позволяет извлекать документы, специфичные для позиции и роли пользователя в предприятии, и усилия, которые они назначены. Например, разработчик Java, работающий над тем, что текущий релиз может понадобиться информация о Java 17. Если один и тот же разработчик будет назначен для работы над будущим выпуском, им может понадобиться информация, скажем, Java 20. Когда они работают с такими технологиями, как Kubernetes и Azure AKS, документация по поставщику может быть в значительной степени бесполезным и вызывают непрерывность, потому что он содержит общие вещи, которые они должны знать, что они должны знать, что они могут знать, что они могут знать, что они могут знать, что они могут понять, что они могут понять, что они могут понять, что они могут понять, что они могут понять, что они могут понять, что они могут понять, что в ней может быть в целях.
Размеры:
Размеры:
Тодо. В соответствии с отраслевой информацией предназначена очень большое количество документов - соответствует варианту использования операционных документов
Тодо. Может быть лучше для меньшего количества документов (процедур) - все они могут соответствовать памяти, и поиск может быть выполнен на семантических графиках. В случае векторной базы данных одним из способов построения индексов является использование графиков - иерархический судоходной маленький мир (HNSW)
Тодо. Может быть, подходит для технической документации:
Этот процесс приведет к большому количеству (сотни) относительно небольших графиков/моделей (базы знаний) с десятками тысяч документов.
Пространство дизайна для нейронных сетей, лекционная часть Stanford CS224W: ML с графиками, слайды ↩


