doc rag harness
1.0.0
检索增强发电的区域正在迅速发展。实施检索有许多不同的方法。有些人使用嵌入式和矢量数据库,一些其他使用语义图。因此,有不同的设计,还有不同的任务,与任务1匹配的设计很重要。
该线束的目的是提供收集定义,抽象和构建块,以帮助理解,基准测试,比较和选择特定的检索设计,该设计最能匹配手头的任务。
安全带的目的是与技术 +技术兼容性套件(TCK)有些相似 - 提供:
Java被选为具有丰富语言和大型成熟生态系统的企业世界中的主要技术。之所以选择EMF Ecore,是因为有功能:
此页面提供了核心概念的介绍,并概述了几种用例(任务)和设计(替代方案)。
下图概述了线束结构和上下文:
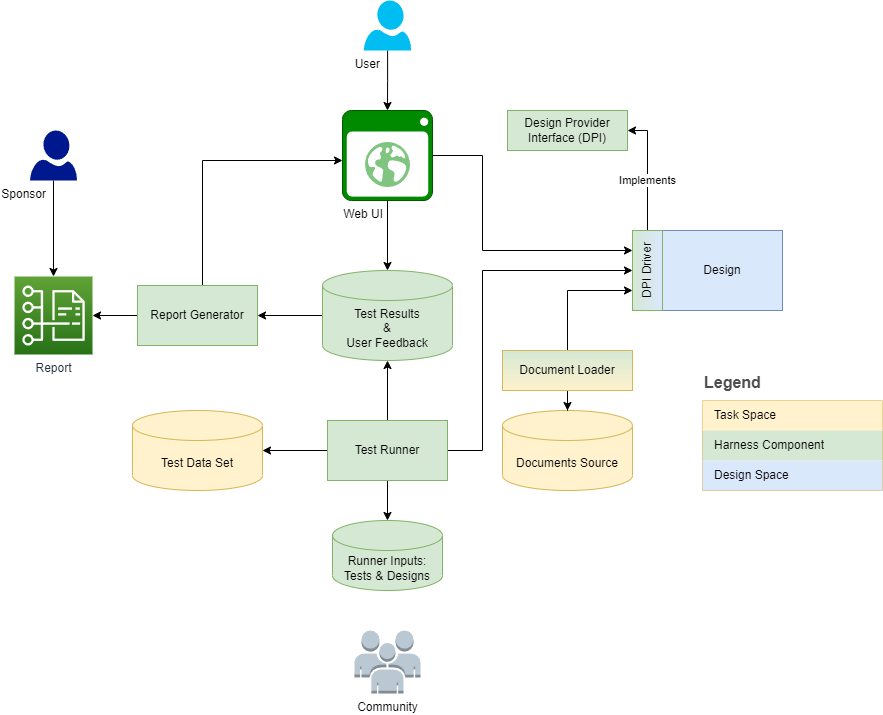
以下各节为每个定义提供了定义和概述任务/设计维度。元模型将一些定义捕获为模型元素,并将其详细说明,并将其详细说明。
文档是纪念思想或信息的代表。出于此线束文件的目的:
“物理”实现:
“逻辑”实现:
pom.xml加载到项目对象模型中,Java文件可以加载到语法树中,也可以加载具有分析类型/字段/方法参考的图形。将一个文档表示形式转换为另一个文档。例如,PDF或OCR JSON到Swift MT 700消息的对象模型。
以特定格式或格式存储文档。例如带有PDF文档的文件系统。文档源可以转换/改编。文档源的示例之一是git commit。 Nasdanika GitLab模型可用于实现GitLab的文档加载。
提供存储和检索功能的文档集合。 DPI的主要接口(见下文)由设计实现。
存储文档时,存储库可能执行诸如图像识别之类的任务。
可能有多种检索方式,例如:
存储库可以从其他存储库和数据加载程序组成。例如,可以从PDF->对象模型数据加载程序和对象模型存储库中组装PDF存储库。文档存储库也可能不必存储/重新创建源文档 - 他们可以将其引用并从文档存储中检索 - 已加载文档的原件或特定于存储库的文档商店。
也有可能构成不同的存储库。例如,一个支持关键字搜索和支持语义搜索的存储库的存储库。在这种情况下,关键字搜索存储库查询结果将是必要的,但不足,可能被用来验证语义搜索存储库的结果。
用户通过Web UI查询文档存储库。他们可以作为工作职能的一部分来做或评估特定设计的查询功能并提供反馈。这两种方式可能会结合在一起 - 用户可以选择仅使用“冠军”查询引擎/设计,例如关键字搜索,或者选择“挑战者”引擎/设计。
Web UI可能会捕获用户上下文,例如组织中的角色/位置,并将其作为查询的一部分传递到设计。
有兴趣通过利用文件检索增强发电来提高用户工作质量(例如生产率)的一方。
赞助商需要平衡多个标准,以最大程度地减少“损失函数”:
设计是技术及其配置参数的实例化/实施例。
设计变化点 - 可以在不同的实施方案/实例化和值源中更改的内容。例如:
设计维度可以形成树,也可以更精确地形成有向图。例如,矢量数据库版本将是特定矢量数据库节点下的节点。
设计提供商界面(DPI)从特定的设计实现中提取了线束。它是必须实现的一组接口和抽象类。例如DocumentRepository接口。 DPI在Java/ecore中定义,可以为不同技术提供适配器。尤其:
任务是文档检索的特定用途。例如,在组织特定技术文档中的语义搜索“我如何将春季微服务部署到AKS?”。
响应的测试文档,查询和评估者的集合。
测试数据集 /设计组合的集合将由测试跑者执行。
测试跑步者只能根据输入执行以上步骤的一部分。例如:
测试运行可以分布在多个代理/机器上。
存储测试结果和用户反馈。测试结果和用户反馈应参考测试数据集和设计。因此,它本质上是一个线束元数据存储库,其中包含设计定义树/图表,测试数据集定义以及测试运行的结果。
生成报告。该报告可能采用可视化的HTML格式。可能的报告格式:
报告可能包含指向Web UI甚至“主机” Web UI的链接,如果将其作为单页应用程序(SPA)实现,例如React或Vue.js/Bootstrapvue
各方为线束,设计和测试数据集做出贡献。社区成员可能会在不同的组件上扮演不同的角色。
---正在进行中的工作---
本节概述了几个任务(用例),用于检索增强生成和搜索。
方面:
示例 - 大型企业中的技术功能:
对于上面的每一个都有一个时间维度 - 顶部的技术堆栈更新,底部发行。有关可视化,请参见Togaf架构景观。
在这样的环境中,用户需要检索解决方案,该解决方案允许检索特定于用户在企业中的位置和角色的文档及其分配的努力。例如,一名Java开发人员,例如当前的发布可能需要有关Java 17的信息。如果将同一开发人员分配为未来发布的工作,则可能需要有关Java 20的信息。当他们使用Kubernetes和Kubernetes和Azure Aks等技术时,供应商文档可能会很大程度上是用途,但需要使用一般信息。
方面:
方面:
托多。根据行业信息,针对大量文档 - 匹配操作文件用例
托多。对于少量文档(过程)可能会更好 - 它们可能都适合内存,并且可以在语义图上执行搜索。在矢量数据库中,构建索引的一种方法是使用图形 - 层次可导航的小世界(HNSW)
托多。可能非常适合技术文档用例:
此过程将导致大量(数百个)相对较小的图形/模型(知识库),并具有数万个文档。
图形神经网络的设计空间,斯坦福CS224W的演讲部分:带有图形的ML,幻灯片↩


