doc rag harness
1.0.0
Das Gebiet der erweiterten Erzeugung von Abruf entwickelt sich schnell. Es gibt viele verschiedene Möglichkeiten, das Abruf umzusetzen. Einige Leute verwenden Emetten- und Vektor -Datenbanken, andere verwenden semantische Diagramme. Es gibt also verschiedene Designs und auch unterschiedliche Aufgaben, und es ist wichtig, ein Design zu einer Aufgabe 1 anzupassen.
Das Ziel dieses Kabelbaums, Definitionen, Abstraktionen und Bausteine für Sammeldefinitionen zu erstellen, um ein bestimmtes Abrufdesign zu verstehen, Benchmarking, Vergleich und Auswahl eines spezifischen Abrufdesigns zu unterstützen, das am besten zu einer aufgeschlossenen Aufgabe passt.
Der Kabelbaum soll einem Technology + Technology Compatibility Kit (TCK) etwas ähnlich sein, um:
Java wurde als dominierende Technologie in der Enterprise -Welt mit reicher Ausdruckskraft der Sprache und einem großen reifen Ökosystem ausgewählt. EMF Ecore wurde ausgewählt, weil es Fähigkeiten gibt:
Diese Seite bietet eine Einführung in Kernkonzepte und beschreibt mehrere Anwendungsfälle (Aufgaben) und Designs (Alternativen).
Das folgende Diagramm beschreibt die Gurtstruktur und den Kontext:
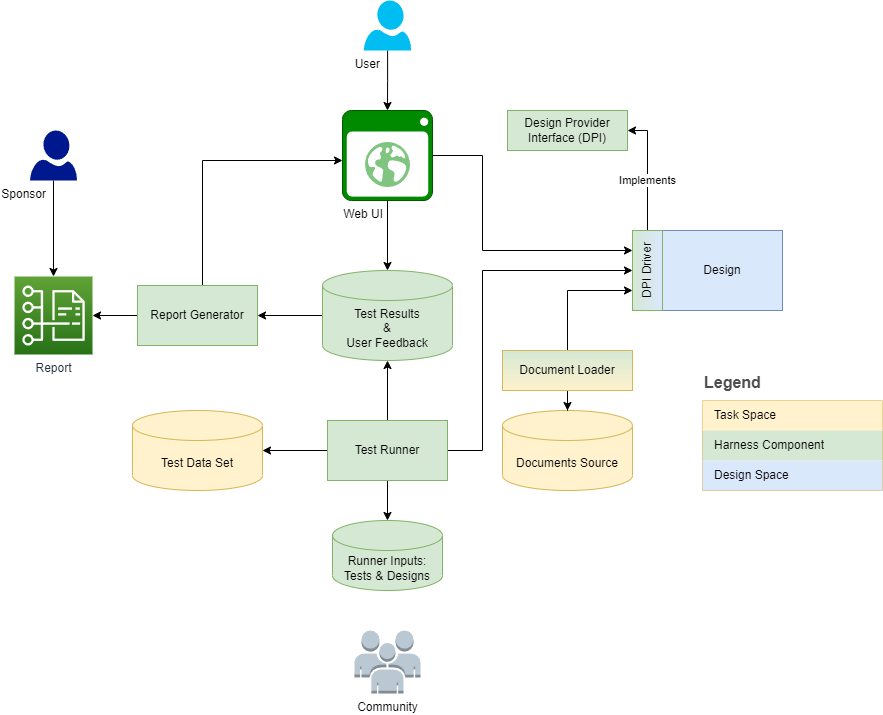
Die folgenden Abschnitte bieten Definitionen und Umrissaufgaben-/Designabmessungen für jede Definition. Das Metamodel erfasst einige der Definitionen als Modellelemente und erläutert sie in Merkmale, Operationen und Unterklassen.
Das Dokument ist eine erinnerte Darstellung von Gedanken oder Informationen. Für die Zwecke dieses Kabelbaumdokumente:
"Physische" Implementierungen:
"Logische" Implementierungen:
pom.xml kann in ein Projektobjektmodell geladen werden. Die Java -Datei kann in einen Syntaxbaum oder einen Diagramm mit aufgelöstem Typ/Feld/Methodenreferenzen geladen werden.Konvertiert eine Dokumentdarstellung in eine andere. ZB PDF oder OCR JSON an ein Objektmodell einer Swift MT 700 -Nachricht.
Speicherung von Dokumenten in einem bestimmten Format oder Formaten. ZB ein Dateisystem mit PDF -Dokumenten. Dokumentequellen können umgewandelt/angepasst werden. Eines der Beispiele für die Dokumentquelle ist ein Git -Commit. Das Nasdanika Gitlab -Modell kann verwendet werden, um das Laden von Dokumenten aus GitLab zu implementieren.
Eine Sammlung von Dokumenten, die Speicher- und Abruffunktionen bieten. Die primäre Schnittstelle des DPI (siehe unten), die von Designs implementiert werden soll.
Beim Speichern eines Dokuments kann das Repository Aufgaben wie die Bilderkennung ausführen.
Es kann mehrere Abrufmodalitäten geben, wie z. B.:
Repositorys können aus anderen Repositorys und Datenladern zusammengestellt werden. ZB ein PDF -Repository kann aus einem PDF -> Objektmodelldatenlader und einem Objektmodell -Repository zusammengestellt werden. Dokument -Repositories müssen auch das Quelldokument möglicherweise nicht speichern/neu erstellen - sie können es referenzieren und aus einem Dokumentgeschäft abrufen - das Original, aus dem das Dokument geladen wurde, oder auf einen repository -spezifischen Dokumentstore.
Es kann auch möglich sein, verschiedene Entwürfe von Repositories zu bestimmen. Zum Beispiel ein Repository, das die Keyword -Suche und ein Repository unterstützt, das die semantische Suche unterstützt. In diesem Fall wären die Ergebnisse der Keyword -Suchrepository -Abfragen erforderlich, aber nicht ausreichend und können verwendet werden, um die Ergebnisse des semantischen Suchrepositorys zu validieren.
Benutzer fragen ein Dokument -Repository über die Web -Benutzeroberfläche ab. Sie können dies als Teil ihrer Jobfunktion oder um die Abfragefunktionalität eines bestimmten Designs zu bewerten und Feedback zu geben. Diese beiden Modalitäten können kombiniert werden - Benutzer verwenden möglicherweise nur die "Champion" -Anfrage -Engine/-design, z. B. die Suche nach Schlüsselwörtern oder auch "Challenger" -Motoren/-designs.
Die Web -Benutzeroberfläche kann den Benutzerkontext wie Rolle/Position in der Organisation erfassen und als Teil einer Abfrage an das Design weitergeben.
Eine Partei, die sich für die Verbesserung der Eigenschaften der Benutzerarbeit interessiert, z. B. die Produktivität durch die Verwendung von Dokumentenab Abruf Augmented Generation.
Sponsoren müssen mehrere Kriterien ausgleichen, um die "Verlustfunktion" zu minimieren:
Das Design ist eine Instanziierung/Verkörperung von Technologien und deren Konfigurationsparametern.
Entwurfsvariationspunkte - Was kann in verschiedenen Ausführungsformen/Instanziationen und Wertenquellen geändert werden. Zum Beispiel:
Designabmessungen können einen Baum oder genauer gesagt ein gerichteter Diagramm bilden. EG -Vektor -Datenbankversionen wären Knoten unter einem Knoten für eine bestimmte Vektordatenbank.
DPI -Designanbieter Interface (DPI) wird den Kabelbaum aus einer bestimmten Design -Implementierung abstrahiert. Es handelt sich um eine Reihe von Schnittstellen und abstrakten Klassen, die das Design implementieren muss. ZB DocumentRepository -Schnittstelle. DPI ist in Java/Ecore definiert und kann Adapter für verschiedene Technologien zur Verfügung stellen. Insbesondere:
Die Aufgabe ist eine spezifische Verwendung des Dokumentenabrufs. Beispielsweise semantische Suche in organisationspezifischen technischen Dokumentation "Wie stelle ich einen Spring Microservice für AKs bereit?".
Eine Sammlung von Testdokumenten, Abfragen und Bewertern von Antworten.
Eine Sammlung von Testdatensatz- / Designkombinationen, die vom Testläufer ausgeführt werden sollen.
Der Testläufer kann je nach Eingängen nur Teile der obigen Schritte ausführen. Zum Beispiel:
Testläufe können über mehrere Agenten/Maschinen verteilt werden.
Speicherung von Testergebnissen und Benutzerfeedback. Testergebnisse und Benutzerfeedback müssen Testdatensätze und -designs referenzieren. Daher handelt es sich im Wesentlichen um ein Gurtmetadaten -Repository mit Entwurfsdefinitionsbäumen/-grafiken, Testdatensatzdefinitionen und Ergebnissen von Testläufen.
Generiert einen Bericht. Der Bericht könnte im HTML -Format mit Visualisierungen sein. Ein mögliches Berichtsformat:
Der Bericht kann Links zur Web -Benutzeroberfläche oder sogar "Host" der Web -Benutzeroberfläche enthalten, wenn sie als Einzelseiten -Anwendung (SPA) mit beispielsweise React oder Vue.js/Bootstrapvue implementiert ist
Parteien, die zum Geschirr, Designs und Testdatensätzen beitragen. Community -Mitglieder spielen möglicherweise unterschiedliche Rollen in verschiedenen Komponenten.
--- Arbeit in Arbeit ----
Dieser Abschnitt beschreibt mehrere Aufgaben (Anwendungsfälle) für die Abrufen der Augmented -Generation und -Suche im Allgemeinen.
Abmessungen:
Beispiel - Technologiefunktion in einem großen Unternehmen:
Für jedes der oben genannten gibt es eine zeitliche Dimension - Tech -Stapel -Updates oben, veröffentlicht unten. Siehe Togaf Architecture Landscape für eine Visualisierung.
In einer solchen Umgebung benötigen Benutzer eine Abruflösung, mit der Dokumente abgerufen werden können, die für die Position und Rolle des Benutzers im Unternehmen und die Anstrengungen, denen sie zugewiesen werden, spezifisch sind. Zum Beispiel, an dem ein Java -Entwickler arbeitet, beispielsweise die aktuelle Veröffentlichung benötigt möglicherweise Informationen über Java 17. Wenn derselbe Entwickler zu einer künftigen Veröffentlichung zugewiesen wird, benötigt sie möglicherweise Informationen darüber, über die sie mit Technologien wie Kubernetes und Azure -Ak -AKs arbeiten. Wenn sie mit technologischen Dokumentation weitgehend nutzlos sind, können Sie bei allgemeinen Informationen über allgemeine Informationen verfügen.
Abmessungen:
Abmessungen:
Todo. Laut Brancheninformationen zielt eine sehr große Anzahl von Dokumenten ab - entspricht dem Anwendungsfall der Betriebsdokumente
Todo. Möglicherweise ist besser für eine geringere Anzahl von Dokumenten (Verfahren) - sie passen alle in den Speicher und Suchvorgänge können in semantischen Graphen durchgeführt werden. Im Vektor -Datenbankfall besteht eine Möglichkeit zum Erstellen von Indizes darin, Diagramme zu verwenden - hierarchische navigable kleine Welt (HNSW)
Todo. Möglicherweise passt gut für den Anwendungsfall für technische Dokumentation:
Dieser Prozess führt zu einer großen Anzahl (Hunderten) relativ kleiner Diagramme/Modelle (Wissensbasis) mit Zehntausenden von Dokumenten.
Konstruktionsraum für Grafik Neuronale Netze, Vortrag Teil von Stanford CS224W: ML mit Diagramme, Folien ↩


