doc rag harness
1.0.0
The area of Retrieval Augmented Generation is rapidly evolving. There are many different ways to implement retrieval. Some people use embeddings and vector databases, some other use semantic graphs. So, there are different designs and also there are different tasks and it is important to match a design to a task1.
The goal of this harness to provide a collection definitions, abstractions, and building blocks to aid in understanding, benchmarking, comparing, and selecting a specific retrieval design which best matches a task at hand.
The harness is intended to be somewhat similar to a Technology + Technology Compatibility Kit (TCK) - to provide:
Java was selected as a dominant technology in the enterprise world with rich expressive power of the language and large mature ecosystem. EMF Ecore was selected because there are capabilities:
This page provides an introduction to core concepts and outlines several use cases (tasks) and designs (alternatives).
The below diagram outlines the harness structure and context:
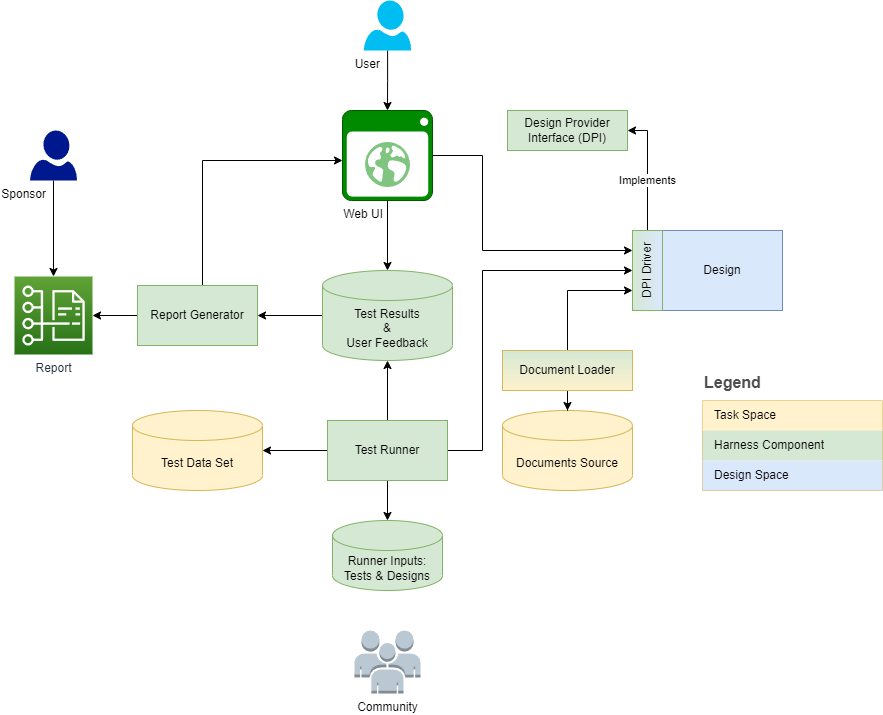
The following sections provide definitions and outline task/design dimensions for each definition. The metamodel captures some of the definitions as model elements and elaborates them into features, operations, and subclasses.
Document is memorialized representation of thought or information. For the purposes of this harness documents:
"Physical" implementations:
"Logical" implementations:
pom.xml can be loaded into a Project Object Model, Java file can be loaded into a syntax tree or a graph with resolved type/field/method references.Converts one document representation to another. E.g. PDF or OCR JSON to an object model of a SWIFT MT 700 message.
Storage of documents in a specific format or formats. E.g. a file system with PDF documents. Documents sources may be converted/adapted. One of examples of document source is a Git commit. Nasdanika GitLab model can be used to implement document loading from GitLab.
A collection of documents providing storage and retrieval functionality. The primary interface of the DPI (see below) to be implemented by designs.
When storing a document the repository may perform tasks such as image recognition.
There might be multiple retrieval modalities such as:
Repositories can be assembled from other repositories and data loaders. E.g. a PDF repository may be assembled from a PDF -> Object model data loader and an object model repository. Also document repositories may not have to store/recreate the source document - they may reference it and retrieve from a document store - the original from which the document was loaded, or a repository-specific document store.
It might also be possible to compose different designs of repositories. For example, a repository which supports keyword search and a repository which supports semantic search. In this case the keyword search repository query results would be necessary, but not sufficient and might be use to validate results of the semantic search repository.
Users query a document repository via the Web UI. They can do it as part of their job function or to evaluate query functionality of a specific design and provide feedback. These two modalities may be combined - users may choose to use only the "champion" query engine/design, e.g. keyword search, or also select "challenger" engines/designs.
The Web UI might capture user context such as role/position in the organization and pass it to the design as part of a query.
A party interested in improving qualities of user work such as productivity by utilizing document retrieval augmented generation.
Sponsors need to balance multiple criteria to minimize the "loss function":
Design is an instantiation/embodiment of technologies and their configuration parameters.
Design variation points - what can be changed in different embodiments/instantiations and source of values. For example:
Design dimensions can form a tree or, more precisely, a directed graph. E.g. vector database versions would be nodes under a node for a specific vector database.
Design Provider Interface (DPI) abstracts the harness from a particular design implementation. It is a set of interfaces and abstract classes which design has to implement.
E.g. DocumentRepository interface. DPI is defined in Java/Ecore and may provide adapters to different technologies. In particular:
Task is a specific use of document retrieval. For example, semantic search in organizaiton-specific technical documentation "How do I deploy a Spring microservice to AKS?".
A collection of test documents, queries, and evaluators of responses.
A collection of Test Data Set / Design combinations to be executed by the test runner.
Test runner may execute only parts of the above steps depending on inputs. For example:
Test runs can be distributed across multiple agents/machines.
Storage of test results and user feedback. Test results and user feedback shall reference test data sets and designs. As such, it is essentially a harness metadata repository containing design definition trees/graphs, test data set definitions, and results of test runs.
Generates a report. The report might be in HTML format with visualizations. A possible report format:
Report may contain links to the Web UI or even "host" the Web UI if it is implemented as a Single Page Application (SPA) with, say, React or Vue.js/BootstrapVue
Parties contributing to the harness, designs, and test data sets. Community members may play different roles on different components.
--- Work in progress ---
This section outlines several tasks (use cases) for retrieval augmented generation and search in general.
Dimensions:
Example - technology function in a large enterprise:
For each of the above there is a time dimension - tech stack updates on the top, releases on the bottom. See TOGAF Architecture Landscape for a visualization.
In such an environment users need a retrieval solution which allows to retrieve documents specific to the user's position and role in the enterprise and the effort they are assigned to. E.g. a Java developer working on, say the current release may need information about Java 17. If the same developer is assigned to work on the future release they might need information about, say, Java 20. When they work with technologies such as Kubernetes and Azure AKS, the vendor documentation might be largely useless and cause confusion because it contains general information, but they need to know about enterprise/segment specific ways of doing things.
Dimensions:
Dimensions:
TODO. According to industry information targets a very large number of documents - matches the Operational Documents Use Case
TODO. May be better for a smaller number of documents (procedures) - they may all fit in memory and searches can be performed on semantic graphs. In the vector database case one way to build indexes is to use graphs - Hierarchical Navigable Small World (HNSW)
TODO. Might be a good fit for the technical documentation use case:
This process will result in a large number (hundreds) of relatively small graphs/models (knowledge bases) with tens of thousands of documents.
Design Space for Graph Neural Networks, Lecture part of Stanford CS224W: ML with Graphs, Slides ↩


