doc rag harness
1.0.0
Le domaine de la génération augmentée de récupération évolue rapidement. Il existe de nombreuses façons de mettre en œuvre la récupération. Certaines personnes utilisent des intégres et des bases de données vectorielles, d'autres utilisent des graphiques sémantiques. Donc, il existe différents conceptions et il existe également différentes tâches et il est important de faire correspondre une conception à une tâche 1 .
L'objectif de ce harnais de fournir des définitions de collecte, des abstractions et des blocs de construction pour aider à comprendre, comparer, comparer et sélectionner une conception de récupération spécifique qui correspond le mieux à une tâche à accomplir.
Le harnais est destiné à être quelque peu similaire à un kit Technology + Technology Compatibilité (TCK) - pour fournir:
Java a été sélectionné comme technologie dominante dans le monde de l'entreprise avec un riche pouvoir expressif de la langue et un grand écosystème mature. EMF Ecore a été sélectionné car il existe des capacités:
Cette page fournit une introduction aux concepts de base et décrit plusieurs cas d'utilisation (tâches) et conceptions (alternatives).
Le diagramme ci-dessous décrit la structure et le contexte du harnais:
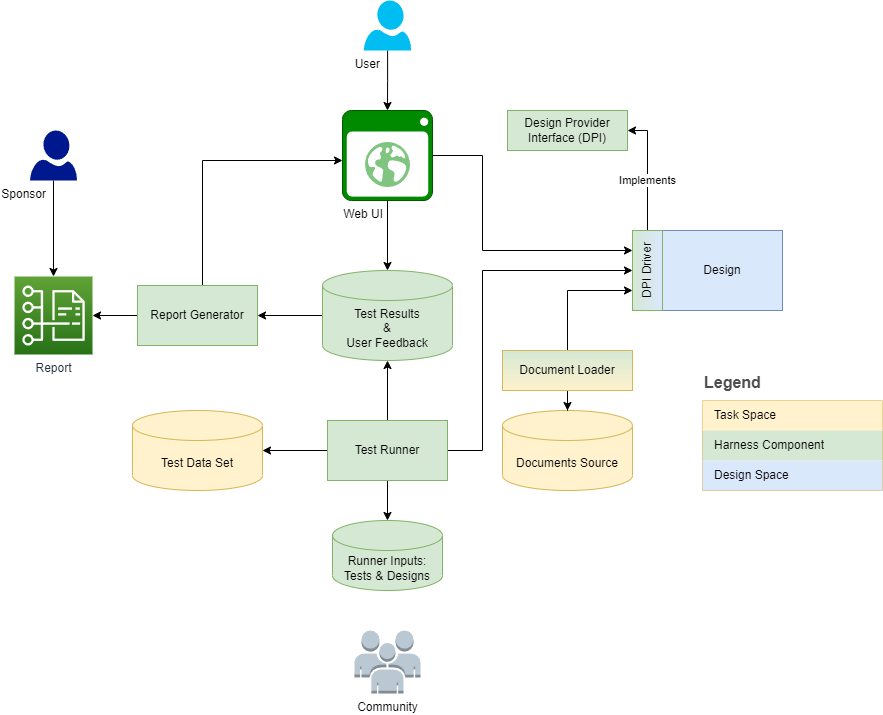
Les sections suivantes fournissent des définitions et des dimensions de tâche / de conception de contour pour chaque définition. Le métamodel capture certaines des définitions en tant qu'éléments de modèle et les élabore en fonctionnalités, opérations et sous-classes.
Le document est une représentation commémorative de la pensée ou de l'information. Aux fins de ces documents de harnais:
Implémentations "physiques":
Implémentations "logiques":
pom.xml peut être chargé dans un modèle d'objet de projet, le fichier Java peut être chargé dans une arborescence de syntaxe ou un graphique avec des références de type / champ / méthode résolues.Convertit une représentation de document à une autre. EG PDF ou OCR JSON à un modèle d'objet d'un message Swift MT 700.
Stockage de documents dans un format ou des formats spécifiques. Par exemple, un système de fichiers avec des documents PDF. Les sources de documents peuvent être converties / adaptées. L'un des exemples de source de documents est un engagement GIT. Le modèle Nasdanika Gitlab peut être utilisé pour implémenter le chargement de documents à partir de GitLab.
Une collection de documents offrant des fonctionnalités de stockage et de récupération. L'interface principale du DPI (voir ci-dessous) à implémenter par des conceptions.
Lors du stockage d'un document, le référentiel peut effectuer des tâches telles que la reconnaissance d'image.
Il peut y avoir plusieurs modalités de récupération telles que:
Les référentiels peuvent être assemblés à partir d'autres référentiels et chargeurs de données. Par exemple, un référentiel PDF peut être assemblé à partir d'un chargeur de données du modèle d'objet PDF - et d'un référentiel de modèle d'objet. Les référentiels de documents peuvent également ne pas avoir à stocker / recréer le document source - ils peuvent le référencer et récupérer dans un magasin de documents - l'original à partir duquel le document a été chargé ou un magasin de documents spécifique au référentiel.
Il pourrait également être possible de composer différents conceptions de référentiels. Par exemple, un référentiel qui prend en charge la recherche de mots clés et un référentiel qui prend en charge la recherche sémantique. Dans ce cas, les résultats de la requête du référentiel de recherche de mots clés seraient nécessaires, mais pas suffisants et peuvent être utilisés pour valider les résultats du référentiel de recherche sémantique.
Les utilisateurs interrogent un référentiel de documents via l'interface utilisateur Web. Ils peuvent le faire dans le cadre de leur fonction de travail ou pour évaluer la fonctionnalité de requête d'une conception spécifique et fournir des commentaires. Ces deux modalités peuvent être combinées - les utilisateurs peuvent choisir d'utiliser uniquement le moteur / conception de requête "champion", par exemple la recherche de mots clés, ou également sélectionner des moteurs / conceptions "Challenger".
L'interface utilisateur Web peut capturer un contexte utilisateur tel que le rôle / la position dans l'organisation et le transmettre à la conception dans le cadre d'une requête.
Une partie intéressée à améliorer les qualités du travail des utilisateurs telles que la productivité en utilisant la génération augmentée de récupération de documents.
Les sponsors doivent équilibrer plusieurs critères pour minimiser la "fonction de perte":
La conception est une instanciation / mode de réalisation des technologies et leurs paramètres de configuration.
Points de variation de conception - Ce qui peut être modifié dans différents modes de réalisation / instanciations et source de valeurs. Par exemple:
Les dimensions de conception peuvent former un arbre ou, plus précisément, un graphique dirigé. Par exemple, les versions de base de données vectorielles seraient des nœuds sous un nœud pour une base de données vectorielle spécifique.
L'interface du fournisseur de conception (DPI) résume le harnais d'une implémentation de conception particulière. Il s'agit d'un ensemble d'interfaces et de classes abstraites que la conception doit mettre en œuvre. EG Interface DocumentRepository . Le DPI est défini dans Java / Ecore et peut fournir des adaptateurs à différentes technologies. En particulier:
La tâche est une utilisation spécifique de la récupération de documents. Par exemple, la recherche sémantique dans la documentation technique spécifique à l'organisation "Comment déployer un microservice de printemps sur AKS?".
Une collection de documents de test, de requêtes et d'évaluateurs des réponses.
Une collection de combinaisons de données / conception de données à exécuter par le Runner de test.
Test Runner peut exécuter uniquement les parties des étapes ci-dessus en fonction des entrées. Par exemple:
Les essais peuvent être distribués sur plusieurs agents / machines.
Stockage des résultats des tests et commentaires des utilisateurs. Les résultats des tests et les commentaires des utilisateurs doivent référencer les ensembles de données et les conceptions de tests. En tant que tel, il s'agit essentiellement d'un référentiel de métadonnées de harnais contenant des arbres / graphiques de définition de conception, des définitions d'ensemble de données et des résultats des essais.
Génère un rapport. Le rapport pourrait être au format HTML avec des visualisations. Un format de rapport possible:
Le rapport peut contenir des liens vers l'interface utilisateur Web ou même "hôte" l'interface utilisateur Web s'il est implémenté en une seule application de page (SPA) avec, par exemple, react ou vue.js / bootstrapvue
Parties contribuant aux ensembles de harnais, de conceptions et de tests de test. Les membres de la communauté peuvent jouer des rôles différents sur différents composants.
--- travail en cours ---
Cette section décrit plusieurs tâches (cas d'utilisation) pour récupérer la génération et la recherche augmentées en général.
Dimensions:
Exemple - Fonction technologique dans une grande entreprise:
Pour chacun des éléments ci-dessus, il y a une dimension temporelle - des mises à jour de la pile technologique en haut, libère en bas. Voir le paysage de l'architecture TOGAF pour une visualisation.
Dans un tel environnement, les utilisateurs ont besoin d'une solution de récupération qui permet de récupérer des documents spécifiques à la position et au rôle de l'utilisateur dans l'entreprise et aux efforts auxquels ils sont affectés. Par exemple, un développeur Java travaillant sur, disons que la version actuelle peut avoir besoin d'informations sur Java 17. Si le même développeur est affecté à travailler sur la future version, ils pourraient avoir besoin d'informations, par exemple, Java 20. Lorsqu'ils travaillent avec des technologies telles que Kubernetes et Azure AKS, la documentation du vendeur peut être largement inutilisée et provoque des informations, mais ils contiennent des informations générales, mais ils ont besoin de savoir sur les spécifications de l'assistance / segment de l'entreprise.
Dimensions:
Dimensions:
FAIRE. Selon l'information de l'industrie cible un très grand nombre de documents - correspond au cas d'utilisation des documents opérationnels
FAIRE. Peut être meilleur pour un plus petit nombre de documents (procédures) - ils peuvent tous tenir dans la mémoire et les recherches peuvent être effectuées sur des graphiques sémantiques. Dans le cas de la base de données vectorielle, une façon de créer des index est d'utiliser des graphiques - Hiérarchical Navigable Small World (HNSW)
FAIRE. Pourrait être un bon ajustement pour le cas d'utilisation de la documentation technique:
Ce processus se traduira par un grand nombre (centaines) de graphiques / modèles relativement petits (bases de connaissances) avec des dizaines de milliers de documents.
Espace de conception pour les réseaux de neurones graphiques, partie de cours de Stanford CS224W: ML avec graphiques, diapositives ↩


