doc rag harness
1.0.0
A área de geração aumentada de recuperação está evoluindo rapidamente. Existem muitas maneiras diferentes de implementar a recuperação. Algumas pessoas usam bancos de dados de incorporação e vetor, outros usam gráficos semânticos. Portanto, existem designs diferentes e também existem tarefas diferentes e é importante corresponder a um design a uma tarefa 1 .
O objetivo desse arnês para fornecer definições de coleta, abstrações e blocos de construção para ajudar na compreensão, benchmarking, comparação e selecionando um design de recuperação específico que melhor corresponde a uma tarefa em questão.
O arnês pretende ser um pouco semelhante a um kit de compatibilidade de tecnologia + tecnologia (TCK) - para fornecer:
Java foi selecionado como uma tecnologia dominante no mundo corporativo, com rico poder expressivo do idioma e um grande ecossistema maduro. O EMF Ecore foi selecionado porque existem recursos:
Esta página fornece uma introdução aos conceitos principais e descreve vários casos de uso (tarefas) e projetos (alternativas).
O diagrama abaixo descreve a estrutura e o contexto do arnês:
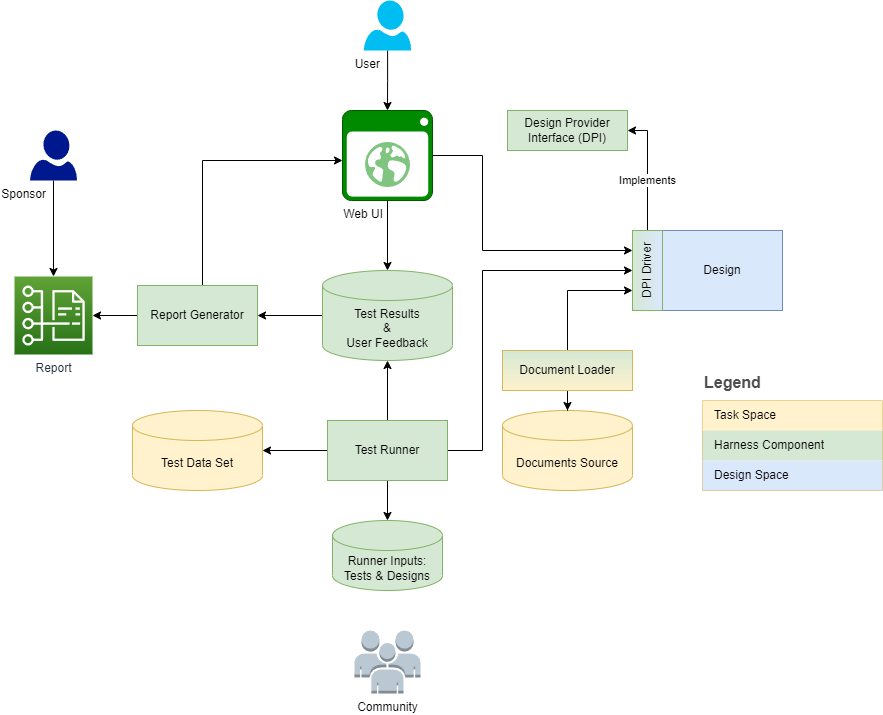
As seções a seguir fornecem definições e esboço das dimensões de tarefa/design para cada definição. O metamodelo captura algumas das definições como elementos do modelo e os elabora em recursos, operações e subclasses.
O documento é memorizado representação de pensamento ou informação. Para os propósitos deste chicote documentos:
Implementações "físicas":
Implementações "lógicas":
pom.xml pode ser carregado em um modelo de objeto de projeto, o arquivo Java pode ser carregado em uma árvore de sintaxe ou em um gráfico com referências de tipo/campo/método resolvidas.Converte uma representação de um documento para outra. Por exemplo, PDF ou OCR JSON para um modelo de objeto de uma mensagem Swift MT 700.
Armazenamento de documentos em um formato ou formato específico. Por exemplo, um sistema de arquivos com documentos em PDF. As fontes de documentos podem ser convertidas/adaptadas. Um dos exemplos de fonte de documentos é um commit git. O modelo Nasdanika GitLab pode ser usado para implementar o carregamento de documentos do GitLab.
Uma coleção de documentos que fornecem funcionalidade de armazenamento e recuperação. A interface principal do DPI (veja abaixo) a ser implementada por projetos.
Ao armazenar um documento, o repositório pode executar tarefas como reconhecimento de imagem.
Pode haver várias modalidades de recuperação, como:
Os repositórios podem ser montados em outros repositórios e carregadores de dados. Por exemplo, um repositório PDF pode ser montado a partir de um carregador de dados do modelo de objeto PDF -> e um repositório de modelo de objeto. Além disso, os repositórios de documentos podem não precisar armazenar/recriar o documento de origem - eles podem fazer referência e recuperar um armazenamento de documentos - o original do qual o documento foi carregado ou de um armazenamento de documentos específico do repositório.
Também pode ser possível compor diferentes projetos de repositórios. Por exemplo, um repositório que suporta pesquisa de palavras -chave e um repositório que suporta pesquisa semântica. Nesse caso, os resultados da consulta do repositório de pesquisa de palavras -chave seriam necessárias, mas não suficientes e podem ser usadas para validar os resultados do repositório de pesquisa semântica.
Os usuários consultam um repositório de documentos por meio da interface do usuário da web. Eles podem fazer isso como parte de sua função de trabalho ou avaliar a funcionalidade de consulta de um design específico e fornecer feedback. Essas duas modalidades podem ser combinadas - os usuários podem optar por usar apenas o mecanismo/design de consulta "Champion", por exemplo, pesquisa de palavras -chave ou também selecionar motores/designs "Challenger".
A interface do usuário da web pode capturar o contexto do usuário, como função/posição na organização e passá -lo para o design como parte de uma consulta.
Uma parte interessada em melhorar as qualidades do trabalho do usuário, como a produtividade, utilizando a geração aumentada de recuperação de documentos.
Os patrocinadores precisam equilibrar vários critérios para minimizar a "função de perda":
O design é uma instanciação/incorporação das tecnologias e seus parâmetros de configuração.
Pontos de variação de design - o que pode ser alterado em diferentes modalidades/instanciações e fonte de valores. Por exemplo:
As dimensões do design podem formar uma árvore ou, mais precisamente, um gráfico direcionado. Por exemplo, as versões do banco de dados vetoriais seriam nós em um nó para um banco de dados vetorial específico.
A interface do provedor de design (DPI) abstrairá o chicote de uma implementação específica do design. É um conjunto de interfaces e classes abstratas que o design deve implementar. Por exemplo, interface DocumentRepository . O DPI é definido em Java/Ecore e pode fornecer adaptadores para diferentes tecnologias. Em particular:
A tarefa é um uso específico da recuperação de documentos. Por exemplo, pesquisa semântica na documentação técnica específica da Organização "Como implanto um microsserviço de primavera no AKS?".
Uma coleção de documentos de teste, consultas e avaliadores de respostas.
Uma coleção de combinações de conjunto de dados de teste / design a serem executadas pelo Test Runner.
O corredor de teste pode executar apenas partes das etapas acima, dependendo das entradas. Por exemplo:
As execuções de teste podem ser distribuídas por vários agentes/máquinas.
Armazenamento dos resultados dos testes e feedback do usuário. Os resultados dos testes e o feedback do usuário devem fazer referência a conjuntos e projetos de dados de teste. Como tal, é essencialmente um repositório de metadados de arnês que contém árvores/gráficos de definição de projeto, definições de conjunto de dados de teste e resultados das execuções de teste.
Gera um relatório. O relatório pode estar em formato HTML com visualizações. Um possível formato de relatório:
O relatório pode conter links para a interface do usuário da web ou até mesmo "hospedar" a interface da web se for implementada como um aplicativo de página única (spa) com, digamos, react ou vue.js/bootstrapvue
Partes contribuindo para os conjuntos de dados de arnês, desenhos e dados de teste. Os membros da comunidade podem desempenhar papéis diferentes em diferentes componentes.
--- trabalho em andamento ---
Esta seção descreve várias tarefas (casos de uso) para geração aumentada de recuperação e pesquisa em geral.
Dimensões:
Exemplo - Função de tecnologia em uma grande empresa:
Para cada um dos itens acima, há uma dimensão de tempo - atualizações de pilha de tecnologia na parte superior, lançamentos na parte inferior. Veja o cenário da arquitetura TOGAF para uma visualização.
Nesse meio ambiente, os usuários precisam de uma solução de recuperação que permita recuperar documentos específicos para a posição e a função do usuário na empresa e o esforço para o qual são atribuídos. Por exemplo, um desenvolvedor de Java trabalhando, digamos que a liberação atual pode precisar de informações sobre o Java 17. Se o mesmo desenvolvedor for designado para trabalhar na versão futura, eles podem precisar de informações, digamos, Java 20. Quando trabalham com tecnologias como Kubernetes e Azure Aks, a documentação do fornecedor pode ser um pouco considerável e causar uma confusão por que o Azure contém o que a documentação do fornecedor pode ser um dos que se conhecem em geral, o que se sabe como se o que é o que se une a seriedade, mas a documentação do fornecedor é que a documentação do fornecedor é que a Kubernetes e a que contém o que é um dos que se conhecem, mas a documentação do fornecedor é que a documentação do fornecedor é que a Kubernetes e o que contém o que é o que se diz que é o que se diz que é o que se diz que é o que se diz que é um dos que se conhecem, mas a documentação do fornecedor.
Dimensões:
Dimensões:
PENDÊNCIA. De acordo com as informações do setor, visam um número muito grande de documentos - corresponde aos documentos operacionais que usam caso
PENDÊNCIA. Pode ser melhor para um número menor de documentos (procedimentos) - todos eles podem se encaixar na memória e as pesquisas podem ser executadas em gráficos semânticos. No caso do banco de dados vetorial, uma maneira de construir índices é usar gráficos - Hierárquica Small World (HNSW)
PENDÊNCIA. Pode ser uma boa opção para o caso de uso da documentação técnica:
Esse processo resultará em um grande número (centenas) de gráficos/modelos relativamente pequenos (bases de conhecimento) com dezenas de milhares de documentos.
Espaço de design para redes neurais gráficas, parte da palestra de Stanford CS224W: ML com gráficos, slides ↩


