doc rag harness
1.0.0
검색 증강 세대의 영역은 빠르게 진화하고 있습니다. 검색을 구현하는 방법에는 여러 가지가 있습니다. 어떤 사람들은 임베딩과 벡터 데이터베이스를 사용하고 다른 사람들은 시맨틱 그래프를 사용합니다. 따라서 디자인이 다르고 다른 작업이 있으며 디자인을 작업 1 과 일치시키는 것이 중요합니다.
이 하네스의 목표는 컬렉션 정의, 추상화 및 빌딩 블록을 제공하여 당면한 작업과 가장 잘 어울리는 특정 검색 설계를 이해, 벤치마킹, 비교 및 선택하는 데 도움이됩니다.
하네스는 기술 + 기술 호환 키트 (TCK)와 다소 유사합니다.
Java는 언어의 풍부한 표현력과 대규모 성숙한 생태계를 가진 기업 세계에서 지배적 인 기술로 선정되었습니다. EMF Ecore는 기능이 있기 때문에 선택되었습니다.
이 페이지는 핵심 개념에 대한 소개를 제공하고 몇 가지 사용 사례 (작업) 및 설계 (대안)에 대한 설명을 제공합니다.
아래 다이어그램은 하네스 구조와 컨텍스트를 간략하게 설명합니다.
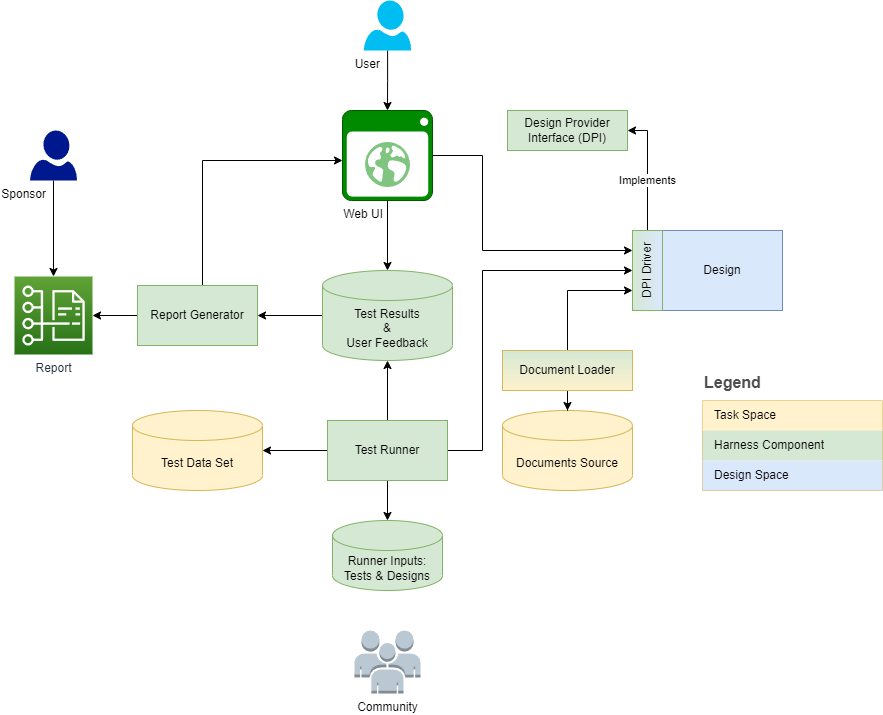
다음 섹션은 각 정의에 대한 정의 및 개요 작업/설계 차원을 제공합니다. 메타 모델은 일부 정의를 모델 요소로 캡처하여 기능, 작업 및 하위 클래스로 정교화합니다.
문서는 사고 나 정보의 기념식 표현입니다. 이 하네스 문서의 목적 상 :
"물리적"구현 :
"논리적"구현 :
pom.xml 프로젝트 객체 모델에로드 될 수 있으며, Java 파일은 구문 트리 또는 유형/필드/메소드 참조가있는 그래프에로드 될 수 있습니다.한 문서 표현을 다른 문서로 변환합니다. 예를 들어 Swift MT 700 메시지의 객체 모델에 대한 PDF 또는 OCR JSON.
특정 형식 또는 형식의 문서 저장. 예를 들어 PDF 문서가있는 파일 시스템. 문서 소스는 변환/조정 될 수 있습니다. 문서 소스의 예 중 하나는 git 커밋입니다. Nasdanika Gitlab 모델은 Gitlab에서 문서로드를 구현하는 데 사용될 수 있습니다.
저장 및 검색 기능을 제공하는 문서 모음. DPI의 기본 인터페이스 (아래 참조)는 설계에 의해 구현됩니다.
문서를 저장할 때 리포지토리는 이미지 인식과 같은 작업을 수행 할 수 있습니다.
다음과 같은 여러 가지 검색 방식이있을 수 있습니다.
저장소는 다른 리포지토리 및 데이터 로더에서 조립할 수 있습니다. 예를 들어 PDF 리포지토리는 PDF-> 객체 모델 데이터 로더 및 객체 모델 저장소에서 조립 될 수 있습니다. 또한 문서 리포지토리는 소스 문서를 저장/재현 할 필요가 없을 수 있습니다. 소스 문서를 저장/재현 할 필요는 없습니다. 문서가로드 된 원본 또는 저장소 별 문서 저장소 인 문서 저장소에서 참조하고 검색 할 수 있습니다.
다른 리포지토리 설계를 구성하는 것도 가능할 수도 있습니다. 예를 들어, 키워드 검색을 지원하는 저장소 및 시맨틱 검색을 지원하는 저장소입니다. 이 경우 키워드 검색 저장소 쿼리 결과는 필요하지만 충분하지 않으며 시맨틱 검색 저장소의 결과를 검증하는 데 사용할 수 있습니다.
사용자는 웹 UI를 통해 문서 저장소를 쿼리합니다. 작업 기능의 일부로 수행하거나 특정 설계의 쿼리 기능을 평가하고 피드백을 제공 할 수 있습니다. 이 두 가지 방식은 결합 될 수 있습니다. 사용자는 "챔피언"쿼리 엔진/디자인, 예를 들어 키워드 검색 또는 "도전자"엔진/디자인 만 사용하도록 선택할 수 있습니다.
웹 UI는 조직의 역할/위치와 같은 사용자 컨텍스트를 캡처하여 쿼리의 일부로 설계에 전달할 수 있습니다.
문서 검색 증강 생성을 활용하여 생산성과 같은 사용자 작업의 품질 향상에 관심이있는 당사자.
스폰서는 "손실 함수"를 최소화하기 위해 여러 기준의 균형을 유지해야합니다.
설계는 기술 및 구성 매개 변수의 인스턴스화/구체화입니다.
디자인 변형 포인트 - 다른 실시 예/인스턴스화 및 값 소스에서 변경할 수있는 것. 예를 들어:
설계 치수는 트리 또는보다 정확하게 지시 된 그래프를 형성 할 수 있습니다. 예를 들어 벡터 데이터베이스 버전은 특정 벡터 데이터베이스의 노드 아래 노드입니다.
DPI (Design Provider Interface)는 특정 설계 구현의 하네스를 추상화합니다. 디자인이 구현 해야하는 일련의 인터페이스 및 추상 클래스 세트입니다. 예 : DocumentRepository 인터페이스. DPI는 Java/Ecore에서 정의되며 다른 기술에 어댑터를 제공 할 수 있습니다. 특히:
작업은 문서 검색의 특정 사용입니다. 예를 들어, Organizaiton 별 기술 문서의 시맨틱 검색 "스프링 마이크로 서비스를 AKS에 어떻게 배포합니까?"
테스트 문서, 쿼리 및 응답 평가자 모음.
테스트 러너가 실행할 테스트 데이터 세트 / 디자인 조합 모음.
테스트 러너는 입력에 따라 위의 단계의 일부만 실행할 수 있습니다. 예를 들어:
테스트 실행은 여러 에이전트/기계에 배포 할 수 있습니다.
테스트 결과 및 사용자 피드백 저장. 테스트 결과 및 사용자 피드백은 테스트 데이터 세트 및 설계를 참조해야합니다. 따라서 기본적으로 설계 정의 트리/그래프, 테스트 데이터 세트 정의 및 테스트 실행 결과를 포함하는 하네스 메타 데이터 저장소입니다.
보고서를 생성합니다. 보고서는 시각화와 함께 HTML 형식 일 수 있습니다. 가능한 보고서 형식 :
보고서는 웹 UI 또는 웹 UI에 대한 링크를 포함 할 수 있습니다. 웹 UI가 단일 페이지 응용 프로그램 (SPA)으로 구현되는 경우 웹 UI가 포함될 수 있습니다.
하네스, 설계 및 테스트 데이터 세트에 기여하는 당사자. 커뮤니티 회원은 다른 구성 요소에 대해 다른 역할을 수행 할 수 있습니다.
--- 진행중인 작업 ---
이 섹션에서는 검색 증강 생성 및 일반적으로 검색을위한 몇 가지 작업 (사용 사례)을 간략하게 설명합니다.
치수:
예 - 대기업의 기술 기능 :
위의 각각에 대해 상단에 시간 차원 - 기술 스택 업데이트가 있으며 하단에 릴리스됩니다. 시각화는 TOGAF 아키텍처 환경을 참조하십시오.
이러한 환경에서 사용자는 기업에서 사용자의 위치와 역할에 특정한 문서와 그들이 할당 된 노력과 관련된 문서를 검색 할 수있는 검색 솔루션이 필요합니다. 예를 들어, Java 개발자는 현재 릴리스에 Java 17에 대한 정보가 필요할 수 있다고 말합니다. 동일한 개발자가 향후 릴리스에 대한 작업을 할당되면 Java 20에 대한 정보가 필요할 수 있습니다. Kubernetes 및 Azure AKS와 같은 기술을 사용하면 공급 업체 문서가 크게 쓸모없고 일반 정보를 포함 할 수 있지만, 구체적으로 포함되기 때문일 수 있습니다.
치수:
치수:
TODO. 산업 정보에 따르면 매우 많은 수의 문서를 대상으로합니다 - 운영 문서 사용 사례와 일치합니다.
TODO. 더 적은 수의 문서 (절차)에 더 좋을 수 있습니다. 모두 메모리에 적합 할 수 있으며 시맨틱 그래프에서 검색을 수행 할 수 있습니다. 벡터 데이터베이스 케이스에서 인덱스를 빌드하는 한 가지 방법은 그래프를 사용하는 것입니다 - 계층 적 탐색 가능한 작은 세계 (HNSW)
TODO. 기술 문서 사용 사례에 적합 할 수 있습니다.
이 프로세스는 수만 개의 문서가있는 상대적으로 작은 그래프/모델 (지식 기반)의 많은 수 (수백)가 발생합니다.
그래프 신경망을위한 설계 공간, 스탠포드 CS224W의 강의 부분 : 그래프가있는 ML, 슬라이드 ↩


