doc rag harness
1.0.0
El área de la generación aumentada de recuperación está evolucionando rápidamente. Hay muchas formas diferentes de implementar la recuperación. Algunas personas usan incrustaciones y bases de datos vectoriales, algunas otras usan gráficos semánticos. Por lo tanto, hay diferentes diseños y también hay diferentes tareas y es importante que coincida con un diseño con una tarea 1 .
El objetivo de este arnés para proporcionar definiciones de colección, abstracciones y bloques de construcción para ayudar a comprender, evaluar, comparar y seleccionar un diseño de recuperación específico que mejor coincida con una tarea en cuestión.
El arnés pretende ser algo similar a un kit de compatibilidad de tecnología + tecnología (TCK), para proporcionar:
Java fue seleccionada como una tecnología dominante en el mundo empresarial con un rico poder expresivo del lenguaje y un gran ecosistema maduro. EMF Ecore fue seleccionado porque hay capacidades:
Esta página proporciona una introducción a los conceptos centrales y describe varios casos de uso (tareas) y diseños (alternativas).
El siguiente diagrama describe la estructura y el contexto del arnés:
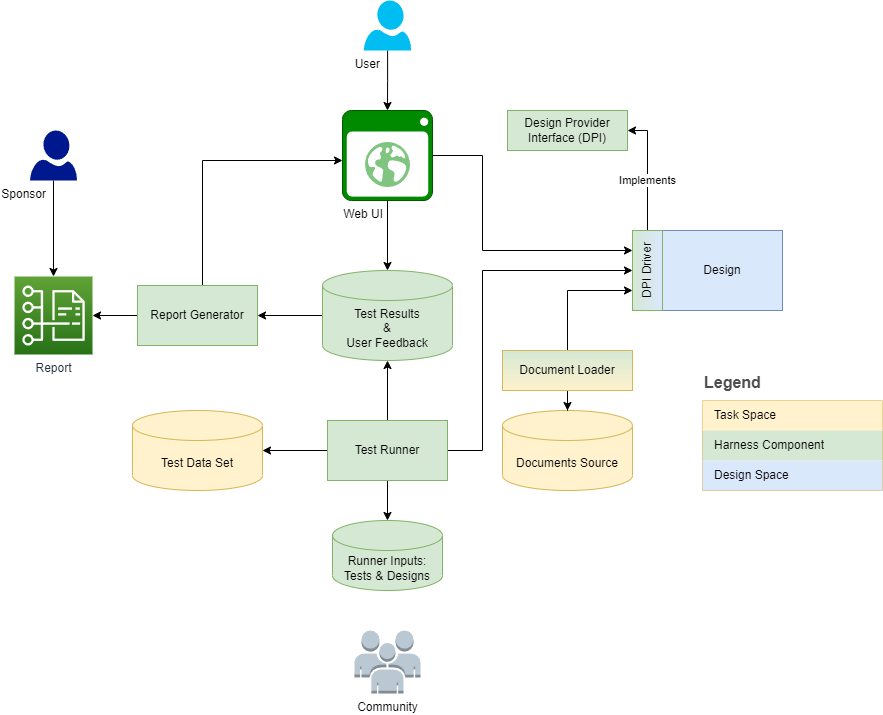
Las siguientes secciones proporcionan definiciones y dimensiones de tareas/diseño para cada definición. El metamodelo captura algunas de las definiciones como elementos modelo y los elabora en características, operaciones y subclases.
El documento es una representación conmemorada de pensamiento o información. A los fines de este arnés documentos:
Implementaciones "físicas":
Implementaciones "lógicas":
pom.xml se puede cargar en un modelo de objeto de proyecto, el archivo Java se puede cargar en un árbol de sintaxis o en un gráfico con referencias de tipo/campo/método resuelto.Convierte un documento de representación a otro. Por ejemplo, PDF u OCR JSON a un modelo de objeto de un mensaje Swift MT 700.
Almacenamiento de documentos en un formato o formatos específicos. Por ejemplo, un sistema de archivos con documentos PDF. Las fuentes de documentos pueden convertirse/adaptarse. Uno de los ejemplos de la fuente de documentos es una confirmación Git. El modelo Nasdanika GITLAB se puede usar para implementar la carga de documentos desde GITLAB.
Una colección de documentos que proporcionan funcionalidad de almacenamiento y recuperación. La interfaz principal del DPI (ver más abajo) será implementada por diseños.
Al almacenar un documento, el repositorio puede realizar tareas como el reconocimiento de imágenes.
Puede haber múltiples modalidades de recuperación como:
Los repositorios se pueden ensamblar a partir de otros repositorios y cargadores de datos. Por ejemplo, se puede ensamblar un repositorio PDF a partir de un cargador de datos PDF -> Modelo de objetos y un repositorio de modelo de objetos. También los repositorios de documentos pueden no tener que almacenar/recrear el documento de origen: pueden hacer referencia a él y recuperar de una tienda de documentos, el original desde el cual se cargó el documento o un almacén de documentos específico del repositorio.
También podría ser posible componer diferentes diseños de repositorios. Por ejemplo, un repositorio que admite la búsqueda de palabras clave y un repositorio que admite la búsqueda semántica. En este caso, los resultados de la consulta del repositorio de búsqueda de palabras clave serían necesarios, pero no suficientes y podrían usarse para validar los resultados del repositorio de búsqueda semántica.
Los usuarios consultan un repositorio de documentos a través de la interfaz de usuario web. Pueden hacerlo como parte de su función de trabajo o para evaluar la funcionalidad de consulta de un diseño específico y proporcionar comentarios. Estas dos modalidades se pueden combinar: los usuarios pueden optar por usar solo el motor/diseño de consulta "Champion", por ejemplo, la búsqueda de palabras clave o también seleccionar motores/diseños "Challenger".
La interfaz de usuario web podría capturar el contexto del usuario, como el rol/posición en la organización y pasarla al diseño como parte de una consulta.
Una parte interesada en mejorar las cualidades del trabajo de los usuarios, como la productividad, mediante la utilización de la generación aumentada de recuperación de documentos.
Los patrocinadores deben equilibrar los criterios múltiples para minimizar la "función de pérdida":
El diseño es una instanciación/encarnación de las tecnologías y sus parámetros de configuración.
Puntos de variación de diseño: lo que se puede cambiar en diferentes realizaciones/instancias y fuente de valores. Por ejemplo:
Las dimensiones de diseño pueden formar un árbol o, más precisamente, un gráfico dirigido. Por ejemplo, las versiones de la base de datos de vectores serían nodos en un nodo para una base de datos vectorial específica.
La interfaz de proveedor de diseño (DPI) abstrae el arnés de una implementación de diseño particular. Es un conjunto de interfaces y clases abstractas que el diseño tiene que implementar. Por ejemplo, la interfaz DocumentRepository . El DPI se define en Java/Ecore y puede proporcionar adaptadores a diferentes tecnologías. En particular:
La tarea es un uso específico de la recuperación de documentos. Por ejemplo, la búsqueda semántica en la documentación técnica específica de organización "¿Cómo implemento un microservicio de resorte a AKS?".
Una colección de documentos de prueba, consultas y evaluadores de respuestas.
Una colección de combinaciones de datos / combinaciones de diseño para ser ejecutadas por el corredor de prueba.
El corredor de prueba puede ejecutar solo partes de los pasos anteriores dependiendo de las entradas. Por ejemplo:
Las pruebas se pueden distribuir en múltiples agentes/máquinas.
Almacenamiento de resultados de pruebas y comentarios de los usuarios. Los resultados de las pruebas y los comentarios de los usuarios deberán referencia a conjuntos de datos de prueba y diseños. Como tal, es esencialmente un repositorio de metadatos de arnés que contiene árboles de diseño/gráficos de definición de diseño, definiciones de conjunto de datos de prueba y resultados de ejecuciones de prueba.
Genera un informe. El informe podría estar en formato HTML con visualizaciones. Un posible formato de informe:
El informe puede contener enlaces a la interfaz de usuario web o incluso "alojar" la interfaz de usuario web si se implementa como una aplicación de una sola página (SPA) con, por ejemplo, reaccionar o vue.js/bootstrapvue
Partes que contribuyen al arnés, diseños y conjuntos de datos de prueba. Los miembros de la comunidad pueden desempeñar diferentes roles en diferentes componentes.
--- Trabajo en progreso ---
Esta sección describe varias tareas (casos de uso) para la generación y búsqueda aumentada de recuperación en general.
Dimensiones:
Ejemplo: función tecnológica en una gran empresa:
Para cada uno de los anteriores hay una dimensión de tiempo: actualizaciones de pila tecnológica en la parte superior, se lanza en la parte inferior. Consulte el paisaje de arquitectura Togaf para una visualización.
En dicho entorno, los usuarios necesitan una solución de recuperación que permita recuperar documentos específicos de la posición y el papel del usuario en la empresa y el esfuerzo al que se les asigna. Por ejemplo, un desarrollador de Java en el que trabaja, por ejemplo, la versión actual puede necesitar información sobre Java 17. Si se asigna al mismo desarrollador para trabajar en la versión futura, puede necesitar información sobre, por ejemplo, Java 20. Cuando funcionan con tecnologías con tecnologías como Kubernetes y Azure AKS, la documentación del proveedor puede ser inútil y causar una confusión general.
Dimensiones:
Dimensiones:
HACER. Según la información de la industria, se dirige a una gran cantidad de documentos: coincide con el caso de uso de documentos operativos
HACER. Puede ser mejor para un número menor de documentos (procedimientos): todos pueden caber en la memoria y las búsquedas se pueden realizar en gráficos semánticos. En el caso de la base de datos Vector, una forma de construir índices es usar gráficos: el pequeño mundo jerárquico navegable (HNSW)
HACER. Podría ser una buena opción para el caso de uso de documentación técnica:
Este proceso dará como resultado un gran número (cientos) de gráficos/modelos relativamente pequeños (bases de conocimiento) con decenas de miles de documentos.
Espacio de diseño para redes neuronales gráficas, parte de Stanford CS224W: ML con gráficos, diapositivas ↩


