doc rag harness
1.0.0
พื้นที่ของการเพิ่มการเรียกคืนการพัฒนาอย่างรวดเร็ว มีหลายวิธีในการใช้การดึงข้อมูล บางคนใช้ฐานข้อมูล Embeddings และ Vector ซึ่งเป็นกราฟความหมายอื่น ๆ ดังนั้นจึงมีการออกแบบที่แตกต่างกันและยังมีงานที่แตกต่างกันและเป็นสิ่งสำคัญที่จะจับคู่การออกแบบกับงาน 1
เป้าหมายของสายรัดนี้เพื่อให้คำจำกัดความการรวบรวม, abstractions และการสร้างบล็อกเพื่อช่วยในการทำความเข้าใจการเปรียบเทียบการเปรียบเทียบและการเลือกการออกแบบการดึงข้อมูลที่เฉพาะเจาะจงซึ่งตรงกับงานที่ดีที่สุด
สายรัดมีจุดประสงค์เพื่อให้ค่อนข้างคล้ายกับเทคโนโลยีความเข้ากันได้ของเทคโนโลยี + เทคโนโลยี (TCK) - เพื่อให้:
Java ได้รับเลือกให้เป็นเทคโนโลยีที่โดดเด่นในโลกขององค์กรที่มีพลังการแสดงออกที่หลากหลายของภาษาและระบบนิเวศที่เป็นผู้ใหญ่ขนาดใหญ่ EMF ecore ได้รับเลือกเนื่องจากมีความสามารถ:
หน้านี้ให้คำแนะนำเกี่ยวกับแนวคิดหลักและสรุปการใช้งานหลายกรณี (งาน) และการออกแบบ (ทางเลือก)
แผนภาพด้านล่างแสดงโครงสร้างและบริบทของสายรัด:
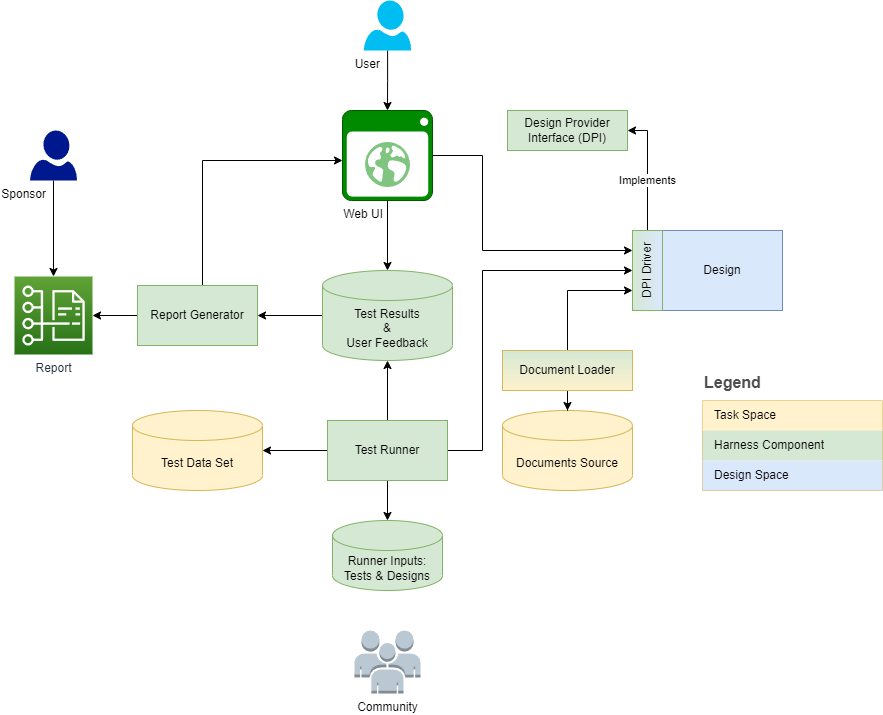
ส่วนต่อไปนี้ให้คำจำกัดความและโครงร่างงาน/มิติการออกแบบสำหรับแต่ละคำจำกัดความ Metamodel รวบรวมคำจำกัดความบางอย่างเป็นองค์ประกอบของแบบจำลองและอธิบายให้เป็นคุณสมบัติการดำเนินงานและคลาสย่อย
เอกสารเป็นตัวแทนที่ระลึกถึงความคิดหรือข้อมูล สำหรับวัตถุประสงค์ของเอกสารสายรัดนี้:
การใช้งาน "ทางกายภาพ":
การใช้งาน "ตรรกะ":
pom.xml สามารถโหลดลงในโมเดลวัตถุโครงการไฟล์ Java สามารถโหลดลงในแผนผังไวยากรณ์หรือกราฟที่มีการอ้างอิงประเภท/ฟิลด์/วิธีการแก้ไขแปลงการแสดงเอกสารหนึ่งเป็นอีกครั้ง เช่น PDF หรือ OCR JSON ไปยังโมเดลวัตถุของข้อความ Swift MT 700
การจัดเก็บเอกสารในรูปแบบหรือรูปแบบเฉพาะ เช่นระบบไฟล์พร้อมเอกสาร PDF แหล่งที่มาของเอกสารอาจถูกแปลง/ดัดแปลง หนึ่งในตัวอย่างของแหล่งเอกสารคือการกระทำ GIT โมเดล Nasdanika Gitlab สามารถใช้เพื่อใช้การโหลดเอกสารจาก Gitlab
คอลเลกชันของเอกสารที่ให้การจัดเก็บและฟังก์ชั่นการดึงข้อมูล อินเทอร์เฟซหลักของ DPI (ดูด้านล่าง) ที่จะดำเนินการโดยการออกแบบ
เมื่อจัดเก็บเอกสารที่เก็บอาจทำงานเช่นการจดจำภาพ
อาจมีหลายวิธีการดึงข้อมูลเช่น:
ที่เก็บสามารถประกอบจากที่เก็บข้อมูลอื่น ๆ และตัวโหลดข้อมูล เช่นที่เก็บ PDF อาจประกอบจาก PDF -> ตัวโหลดข้อมูลโมเดลวัตถุและที่เก็บโมเดลวัตถุ นอกจากนี้ที่เก็บเอกสารอาจไม่จำเป็นต้องจัดเก็บ/สร้างเอกสารแหล่งที่มา - พวกเขาอาจอ้างอิงและดึงข้อมูลจากร้านเอกสาร - ต้นฉบับที่มีการโหลดเอกสารหรือที่เก็บเอกสารเฉพาะที่เก็บ
อาจเป็นไปได้ที่จะเขียนการออกแบบที่แตกต่างกันของที่เก็บ ตัวอย่างเช่นที่เก็บข้อมูลที่รองรับการค้นหาคำหลักและที่เก็บซึ่งรองรับการค้นหาความหมาย ในกรณีนี้ผลลัพธ์การสืบค้นที่เก็บคำหลักจะเป็นสิ่งจำเป็น แต่ไม่เพียงพอและอาจใช้เพื่อตรวจสอบผลลัพธ์ของพื้นที่เก็บข้อมูลการค้นหาความหมาย
ผู้ใช้สอบถามที่เก็บเอกสารผ่าน Web UI พวกเขาสามารถทำได้เป็นส่วนหนึ่งของฟังก์ชั่นงานของพวกเขาหรือเพื่อประเมินฟังก์ชั่นการสืบค้นของการออกแบบที่เฉพาะเจาะจงและให้ข้อเสนอแนะ โมเดลทั้งสองนี้อาจรวมกัน - ผู้ใช้อาจเลือกที่จะใช้เฉพาะเอ็นจิ้น/การออกแบบการสืบค้น "แชมป์" เช่นการค้นหาคำหลักหรือเลือกเครื่องยนต์/การออกแบบ "Challenger"
เว็บ UI อาจจับบริบทผู้ใช้เช่นบทบาท/ตำแหน่งในองค์กรและส่งผ่านไปยังการออกแบบเป็นส่วนหนึ่งของการสืบค้น
บุคคลที่สนใจในการปรับปรุงคุณภาพของการทำงานของผู้ใช้เช่นการเพิ่มผลผลิตโดยใช้การสร้างเอกสารการเพิ่มการดึงเอกสาร
สปอนเซอร์จำเป็นต้องสร้างความสมดุลให้กับเกณฑ์หลายเกณฑ์เพื่อลด "ฟังก์ชั่นการสูญเสีย":
การออกแบบคือการสร้างอินสแตนซ์/ศูนย์รวมของเทคโนโลยีและพารามิเตอร์การกำหนดค่า
จุดแปรผันการออกแบบ - สิ่งที่สามารถเปลี่ยนแปลงได้ในศูนย์รวม/อินสแตนซ์ที่แตกต่างกันและแหล่งที่มาของค่า ตัวอย่างเช่น:
ขนาดการออกแบบสามารถสร้างต้นไม้หรือกราฟกำกับโดยตรง เช่นเวอร์ชันฐานข้อมูลเวกเตอร์จะเป็นโหนดภายใต้โหนดสำหรับฐานข้อมูลเวกเตอร์เฉพาะ
อินเทอร์เฟซผู้ให้บริการออกแบบ (DPI) บทสรุปสายรัดจากการใช้งานการออกแบบเฉพาะ มันเป็นชุดของอินเทอร์เฟซและคลาสนามธรรมที่การออกแบบต้องใช้ EG อินเทอร์เฟซ DocumentRepository DPI ถูกกำหนดไว้ใน Java/Ecore และอาจให้อะแดปเตอร์กับเทคโนโลยีที่แตกต่างกัน โดยเฉพาะอย่างยิ่ง:
ภารกิจคือการใช้การดึงเอกสารเฉพาะ ตัวอย่างเช่นการค้นหาความหมายในเอกสารทางเทคนิคเฉพาะองค์กร "ฉันจะปรับใช้ Microservice Spring กับ AKS ได้อย่างไร"
การรวบรวมเอกสารทดสอบการสืบค้นและผู้ประเมินผลการตอบสนอง
การรวบรวมชุดข้อมูลการทดสอบ / ชุดค่าผสมที่จะดำเนินการโดยนักวิ่งทดสอบ
นักวิ่งทดสอบอาจดำเนินการเฉพาะส่วนของขั้นตอนข้างต้นขึ้นอยู่กับอินพุต ตัวอย่างเช่น:
การทดสอบการทำงานสามารถแจกจ่ายผ่านตัวแทน/เครื่องหลายเครื่อง
การจัดเก็บผลการทดสอบและความคิดเห็นของผู้ใช้ ผลการทดสอบและข้อเสนอแนะของผู้ใช้จะอ้างอิงชุดข้อมูลทดสอบและการออกแบบ ด้วยเหตุนี้จึงเป็นที่เก็บข้อมูลเมตาของสายรัดที่มีต้นไม้/กราฟนิยามการออกแบบคำจำกัดความชุดข้อมูลการทดสอบและผลลัพธ์ของการทดสอบ
สร้างรายงาน รายงานอาจอยู่ในรูปแบบ HTML พร้อมการสร้างภาพข้อมูล รูปแบบรายงานที่เป็นไปได้:
รายงานอาจมีลิงก์ไปยังเว็บ UI หรือแม้กระทั่ง "โฮสต์" เว็บ UI หากมีการใช้งานเป็นแอปพลิเคชันหน้าเดียว (SPA) ด้วยพูด, ตอบสนองหรือ vue.js/bootstrapvue
ฝ่ายที่มีส่วนร่วมในการควบคุมการออกแบบและชุดข้อมูลทดสอบ สมาชิกชุมชนอาจมีบทบาทที่แตกต่างกันในส่วนประกอบที่แตกต่างกัน
--- ทำงานระหว่างดำเนินการ ---
ส่วนนี้สรุปงานหลายอย่าง (กรณีใช้) สำหรับการสร้างการเพิ่มการสร้างและการค้นหาโดยทั่วไป
ขนาด:
ตัวอย่าง - ฟังก์ชั่นเทคโนโลยีในองค์กรขนาดใหญ่:
สำหรับแต่ละข้างต้นมีมิติเวลา - การอัปเดตสแต็คเทคด้านบนจะวางจำหน่ายที่ด้านล่าง ดูภูมิทัศน์สถาปัตยกรรม Togaf สำหรับการสร้างภาพข้อมูล
ในสภาพแวดล้อมเช่นนี้ผู้ใช้ต้องการโซลูชันการดึงซึ่งช่วยให้สามารถดึงเอกสารเฉพาะไปยังตำแหน่งและบทบาทของผู้ใช้ในองค์กรและความพยายามที่พวกเขาได้รับมอบหมาย เช่นนักพัฒนา Java ที่ทำงานอยู่กล่าวว่าการเปิดตัวในปัจจุบันอาจต้องการข้อมูลเกี่ยวกับ Java 17 หากนักพัฒนาเดียวกันได้รับมอบหมายให้ทำงานในการเปิดตัวในอนาคตพวกเขาอาจต้องการข้อมูลเกี่ยวกับพูด Java 20 เมื่อพวกเขาทำงานกับเทคโนโลยีเช่น Kubernetes และ Azure Aks
ขนาด:
ขนาด:
สิ่งที่ต้องทำ จากข้อมูลอุตสาหกรรมมีเป้าหมายเป็นเอกสารจำนวนมาก - ตรงกับเอกสารการใช้งาน
สิ่งที่ต้องทำ อาจจะดีกว่าสำหรับเอกสารจำนวนน้อย (ขั้นตอน) - ทั้งหมดอาจพอดีกับหน่วยความจำและการค้นหาสามารถดำเนินการบนกราฟความหมาย ในกรณีฐานข้อมูลเวกเตอร์วิธีหนึ่งในการสร้างดัชนีคือการใช้กราฟ - โลกขนาดเล็กนำทางแบบลำดับชั้น (HNSW)
สิ่งที่ต้องทำ อาจเหมาะสมสำหรับกรณีการใช้เอกสารทางเทคนิค:
กระบวนการนี้จะส่งผลให้กราฟ/โมเดลขนาดเล็กจำนวนมาก (หลายร้อย) (ฐานความรู้) มีเอกสารนับหมื่น
พื้นที่ออกแบบสำหรับเครือข่ายประสาทกราฟการบรรยายส่วนหนึ่งของ Stanford CS224W: ML พร้อมกราฟสไลด์↩


