pyate
Initial Release for Zenodo
使用Spacy POS標記的Python實現術語提取算法,例如C值,基本,組合基本,怪異和術語提取器。
新:可以在https://kevinlu1248.github.io/pyate/上找到文檔。到目前為止,文檔仍缺少兩種算法和有關TermExtraction類的詳細信息,但我很快就會完成。
新:在https://pyate-demo.herokuapp.com/上嘗試使用算法,這是一個用於演示Pyate的網絡應用程序!
新:Spacy V3得到了支持!對於Spacy V2,使用pyate==0.4.3並查看Spacy V2 readme.md文件
如果您有建議在此軟件包中實現另一種Ate算法的建議,請隨時將其作為算法所基於的論文提交。
對於在Scala和Java中實施的ATE軟件包,分別查看ATR4和JATE。
使用PIP:
pip install pyate
spacy download en_core_web_sm首先,只需調用一種已實現的算法即可。根據Astrakhantsev 2016的數據, combo_basic是五種算法中最精確的,儘管basic和cvalues並不落後(請參閱Precision)。同一項研究表明,PU-ATR和KeyConceptrel的精度高於combo_basic ,但沒有實施,並且PU-ATR自使用機器學習以來需要花費更多的時間。
from pyate import combo_basic
# source: https://www.ncbi.nlm.nih.gov/pmc/articles/PMC1994795/
string = """Central to the development of cancer are genetic changes that endow these “cancer cells” with many of the
hallmarks of cancer, such as self-sufficient growth and resistance to anti-growth and pro-death signals. However, while the
genetic changes that occur within cancer cells themselves, such as activated oncogenes or dysfunctional tumor suppressors,
are responsible for many aspects of cancer development, they are not sufficient. Tumor promotion and progression are
dependent on ancillary processes provided by cells of the tumor environment but that are not necessarily cancerous
themselves. Inflammation has long been associated with the development of cancer. This review will discuss the reflexive
relationship between cancer and inflammation with particular focus on how considering the role of inflammation in physiologic
processes such as the maintenance of tissue homeostasis and repair may provide a logical framework for understanding the U
connection between the inflammatory response and cancer."""
print ( combo_basic ( string ). sort_values ( ascending = False ))
""" (Output)
dysfunctional tumor 1.443147
tumor suppressors 1.443147
genetic changes 1.386294
cancer cells 1.386294
dysfunctional tumor suppressors 1.298612
logical framework 0.693147
sufficient growth 0.693147
death signals 0.693147
many aspects 0.693147
inflammatory response 0.693147
tumor promotion 0.693147
ancillary processes 0.693147
tumor environment 0.693147
reflexive relationship 0.693147
particular focus 0.693147
physiologic processes 0.693147
tissue homeostasis 0.693147
cancer development 0.693147
dtype: float64
"""如果您想將其添加到Spacy管道中,只需使用添加Spacy的add_pipe方法即可。
import spacy
from pyate . term_extraction_pipeline import TermExtractionPipeline
nlp = spacy . load ( "en_core_web_sm" )
nlp . add_pipe ( "combo_basic" )
doc = nlp ( string )
print ( doc . _ . combo_basic . sort_values ( ascending = False ). head ( 5 ))
""" (Output)
dysfunctional tumor 1.443147
tumor suppressors 1.443147
genetic changes 1.386294
cancer cells 1.386294
dysfunctional tumor suppressors 1.298612
dtype: float64
"""此外, TermExtractionPipeline.__init__定義如下
__init__(
self,
func: Callable[..., pd.Series] = combo_basic,
*args,
**kwargs
)
如果func本質上是您的術語提取算法,該算法會吸收一個語料庫(字符串或迭代器),並輸出一系列術語值對及其各自的術語。默認情況下是func的combo_basic 。 args和kwargs是為您過度默認值的默認值,您可以通過運行help (可能以後進行記錄)。
每個cvalues, basic, combo_basic, weirdness和term_extractor都採用字符串或迭代器,並輸出一系列pardas序列的術語值對,其中較高的值表明是域特定項的較高的機會。此外, weirdness和term_extractor採用general_corpus關鍵詞參數,必須是字符串的迭代器,默認為下文所述的通用語料庫。
All functions only take the string of which you would like to extract terms from as the mandatory input (the technical_corpus ), as well as other tweakable settings, including general_corpus (contrasting corpus for weirdness and term_extractor ), general_corpus_size , verbose (whether to print a progress bar), weights , smoothing , have_single_word (whether to have a single word count as a phrase) and threshold 。如果您尚未閱讀論文並且不熟悉算法,我建議您僅使用默認設置。同樣,請help找到有關每種算法的詳細信息,因為它們都是不同的。
在path/to/site-packages/pyate/default_general_domain.en.zip下,有一個通用語料庫的一般CSV文件,特別是來自Wikipedia的3000個隨機句子。它的來源可以在https://www.kaggle.com/mikeortman/wikipedia-sentences上找到。安裝pyate後,使用以下內容訪問它。
import pandas as pd
from distutils . sysconfig import get_python_lib
df = pd . read_csv ( get_python_lib () + "/pyate/default_general_domain.en.zip" )[ "SECTION_TEXT" ]
print ( df . head ())
""" (Output)
0 '''Anarchism''' is a political philosophy that...
1 The term ''anarchism'' is a compound word comp...
2 ===Origins=== n Woodcut from a Diggers document...
3 Portrait of philosopher Pierre-Joseph Proudhon...
4 consistent with anarchist values is a controve...
Name: SECTION_TEXT, dtype: object
"""對於切換語言,只需運行Term_Extraction.set_language({language}, {model_name}) ,其中model_name默認為language 。例如, Term_Extraction.set_language("it", "it_core_news_sm"}) for Italian。默認情況下,該語言是英語。到目前為止,受支持的語言列表是:
要添加更多語言,請用所需語言的至少3000個段落的語料庫提交問題(最好是default_general_domain.{lang}.zip https://www.loc.gov/standards/iso639-2/php/code_list.php)。文件格式應為以下表格,以通過熊貓來解析。
,SECTION_TEXT
0,"{paragraph_0}"
1,"{paragraph_1}"
...
或者,將文件放入src/pyate中,然後提交拉動請求。
警告:該模型僅與Spacy V2一起使用。
儘管該模型最初是針對符號AI算法(非計算學習)的,但我意識到術語提取的Spacy模型可以達到更高的性能,因此決定在此處包括該模型。
有關與符號AI算法的比較,請參見精度。請注意,僅在這里為模型採用F得分,準確性和精度,但是對於AVP的算法,與指標進行比較的算法是沒有意義的。
| URL | F-評分(%) | 精確 (%) | 記起 (%) |
|---|---|---|---|
| https://github.com/kevinlu1248/pyate/releases/download/v0.4.4.2/en_acl_terms_sm-2.0.4.4.4.tar.gz | 94.71 | 95.41 | 94.03 |
該模型在ACL數據集上進行了訓練和評估,ACL數據集是一個以計算機科學為導向的數據集,可以手動選擇該術語。但是,這尚未在其他領域進行測試。
該模型不帶胸衣。要安裝,請運行
pip install https://github.com/kevinlu1248/pyate/releases/download/v0.4.2/en_acl_terms_sm-2.0.4.tar.gz提取條款,
import spacy
nlp = spacy . load ( "en_acl_terms_sm" )
doc = nlp ( "Hello world, I am a term extraction algorithm." )
print ( doc . ents )
"""
(term extraction, algorithm)
""" 這是在Astrakhantsev 2016中測試的七個不同數據庫上的平均精度(AVP)度量的平均精度(AVP)度量的平均精度。 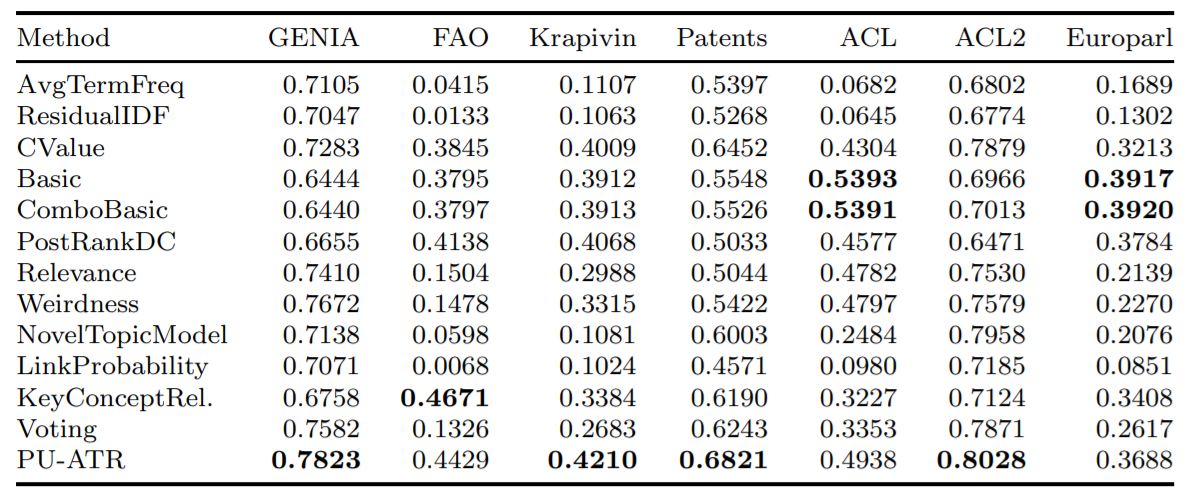
該項目計劃是連接到Google Chrome擴展程序的工具,該工具突出顯示並定義了讀者可能不知道的關鍵術語。此外,術語提取是一個與NLP其他領域相比,由於更通用的NER標記工具,因此沒有大量重點研究的領域,尤其是最近的研究。但是,現代的NER標記通常結合了記憶單詞和深度學習的某種組合,這些單詞在空間和計算上都很重。此外,為了概括算法以識別醫學和AI研究不斷增長的領域的術語,記住的單詞列表將無法做到。
在實施的五種算法中,沒有一個很昂貴,實際上,空間分配和計算費用的瓶頸來自Spacy模型和Spacy POS標籤。這是因為它們主要依靠POS模式,單詞頻率以及嵌入式術語候選者的存在。例如,候選人“乳腺癌”一詞意味著“惡性乳腺癌”可能不是一種術語,而只是一種“惡性”(在C值實施)的“乳腺癌”形式。
我似乎找不到原始的基本和組合基本論文,但我找到了引用它們的論文。 “ ATR4S:具有最先進的自動術語識別方法的工具包或多或少地總結了所有內容,並將其包含在此軟件包中。
如果您發布使用Pyate的作品,請通過[email protected]告訴我,並引用:
Lu, Kevin. (2021, June 28). kevinlu1248/pyate: Python Automated Term Extraction (Version v0.5.3). Zenodo. http://doi.org/10.5281/zenodo.5039289
或等效地與BibText:
@software{pyate,
title = {kevinlu1248/pyate: Python Automated Term Extraction},
author = {Lu, Kevin},
year = 2021,
month = {Jun},
publisher = {Zenodo},
doi = {10.5281/zenodo.5039289}
}
該軟件包在論文中使用(使用術語提取器(Dowlagar and Mamidi,2021)提取了無監督的技術域項提取。
如果我的工作對您有幫助,請考慮在https://www.buymeacoffee.com/kevinlu1248上給我買咖啡。


