pyate
Initial Release for Zenodo
Implementação do Python de algoritmos de extração de termos, como valor C, básico, combinação básica, estranheza e extrator de termo usando a marcação de POS Spacy.
NOVO: A documentação pode ser encontrada em https://kevinlu1248.github.io/pyate/. Até agora, a documentação ainda está faltando dois algoritmos e detalhes sobre a classe TermExtraction , mas o farei em breve.
NOVO: Experimente os algoritmos em https://pyate-demo.herokuapp.com/, um aplicativo da web para demonstrar pyate!
Novo: Spacy V3 é suportado! Para Spacy V2, use pyate==0.4.3 e veja o arquivo SPACY V2 README.MD
Se você tiver uma sugestão para outro algoritmo ATE que você gostaria de implementar neste pacote, fique à vontade para arquivá -lo como um problema no artigo no qual o algoritmo é baseado.
Para pacotes ATE implementados em Scala e Java, consulte ATR4s e Jate, respectivamente.
Usando PIP:
pip install pyate
spacy download en_core_web_sm Para começar, basta ligar para um dos algoritmos implementados. De acordo com o Astrakhantsev 2016, combo_basic é o mais preciso dos cinco algoritmos, embora basic e cvalues não estejam muito atrás (ver precisão). O mesmo estudo mostra que o PU-ATR e o keyConceptrel têm maior precisão que combo_basic , mas não são implementados e o PU-ATR leva significativamente mais tempo, pois usa o aprendizado de máquina.
from pyate import combo_basic
# source: https://www.ncbi.nlm.nih.gov/pmc/articles/PMC1994795/
string = """Central to the development of cancer are genetic changes that endow these “cancer cells” with many of the
hallmarks of cancer, such as self-sufficient growth and resistance to anti-growth and pro-death signals. However, while the
genetic changes that occur within cancer cells themselves, such as activated oncogenes or dysfunctional tumor suppressors,
are responsible for many aspects of cancer development, they are not sufficient. Tumor promotion and progression are
dependent on ancillary processes provided by cells of the tumor environment but that are not necessarily cancerous
themselves. Inflammation has long been associated with the development of cancer. This review will discuss the reflexive
relationship between cancer and inflammation with particular focus on how considering the role of inflammation in physiologic
processes such as the maintenance of tissue homeostasis and repair may provide a logical framework for understanding the U
connection between the inflammatory response and cancer."""
print ( combo_basic ( string ). sort_values ( ascending = False ))
""" (Output)
dysfunctional tumor 1.443147
tumor suppressors 1.443147
genetic changes 1.386294
cancer cells 1.386294
dysfunctional tumor suppressors 1.298612
logical framework 0.693147
sufficient growth 0.693147
death signals 0.693147
many aspects 0.693147
inflammatory response 0.693147
tumor promotion 0.693147
ancillary processes 0.693147
tumor environment 0.693147
reflexive relationship 0.693147
particular focus 0.693147
physiologic processes 0.693147
tissue homeostasis 0.693147
cancer development 0.693147
dtype: float64
""" Se você deseja adicionar isso a um pipeline spacy, basta usar o método Add Spacy add_pipe .
import spacy
from pyate . term_extraction_pipeline import TermExtractionPipeline
nlp = spacy . load ( "en_core_web_sm" )
nlp . add_pipe ( "combo_basic" )
doc = nlp ( string )
print ( doc . _ . combo_basic . sort_values ( ascending = False ). head ( 5 ))
""" (Output)
dysfunctional tumor 1.443147
tumor suppressors 1.443147
genetic changes 1.386294
cancer cells 1.386294
dysfunctional tumor suppressors 1.298612
dtype: float64
""" Além disso, TermExtractionPipeline.__init__ é definido da seguinte maneira
__init__(
self,
func: Callable[..., pd.Series] = combo_basic,
*args,
**kwargs
)
Onde func é essencialmente o seu termo algoritmo de extração que recebe um corpus (uma string ou iterador de strings) e produz uma série de pandas de pares de termos de termos de termos e suas respectivas terras. func é, por padrão, combo_basic . args e kwargs são para você superar os valores padrão da função, que você pode encontrar executando help (pode documentar posteriormente).
Cada um dos cvalues, basic, combo_basic, weirdness e term_extractor apreciam uma string ou um iterador de strings e produções de uma série de pares de termo-valor pandas, onde valores mais altos indicam maior chance de ser um termo específico do domínio. Além disso, weirdness e term_extractor assumem um argumento de palavra -chave general_corpus que deve ser um iterador de strings que padrão no corpus geral descrito abaixo.
All functions only take the string of which you would like to extract terms from as the mandatory input (the technical_corpus ), as well as other tweakable settings, including general_corpus (contrasting corpus for weirdness and term_extractor ), general_corpus_size , verbose (whether to print a progress bar), weights , smoothing , have_single_word (whether to have a single word count as a phrase) and threshold . Se você não leu os papéis e não está familiarizado com os algoritmos, recomendo apenas usar as configurações padrão. Novamente, use help para encontrar os detalhes sobre cada algoritmo, pois todos são diferentes.
Em path/to/site-packages/pyate/default_general_domain.en.zip , existe um arquivo CSV geral de um corpus geral, especificamente, 3000 frases aleatórias da Wikipedia. A fonte pode ser encontrada em https://www.kaggle.com/mikeortman/wikipedia-sentances. Acesse -o usando -o usando o seguinte após a instalação pyate .
import pandas as pd
from distutils . sysconfig import get_python_lib
df = pd . read_csv ( get_python_lib () + "/pyate/default_general_domain.en.zip" )[ "SECTION_TEXT" ]
print ( df . head ())
""" (Output)
0 '''Anarchism''' is a political philosophy that...
1 The term ''anarchism'' is a compound word comp...
2 ===Origins=== n Woodcut from a Diggers document...
3 Portrait of philosopher Pierre-Joseph Proudhon...
4 consistent with anarchist values is a controve...
Name: SECTION_TEXT, dtype: object
""" Para alternar linguagens, basta executar Term_Extraction.set_language({language}, {model_name}) , onde model_name padroniza para language . Por exemplo, Term_Extraction.set_language("it", "it_core_news_sm"}) para italiano. Por padrão, o idioma é inglês. Até agora, a lista de idiomas suportados é:
Para adicionar mais idiomas, arquivar um problema com um corpus de pelo menos 3000 parágrafos de um domínio geral no idioma desejado (preferencialmente Wikipedia) chamado default_general_domain.{lang}.zip substituindo Lang por ISO-639-1 do idioma, ou o ISO-639-2 se o idioma não tive o não tive um não https://www.loc.gov/standards/iso639-2/php/code_list.php). O formato do arquivo deve ser do seguinte formulário para ser parsável pelos pandas.
,SECTION_TEXT
0,"{paragraph_0}"
1,"{paragraph_1}"
...
Como alternativa, coloque o arquivo no src/pyate e registre uma solicitação de tração.
Aviso: o modelo funciona apenas com Spacy V2.
Embora esse modelo tenha sido originalmente destinado a algoritmos simbólicos de AI (aprendizado não máquinas), percebi que um modelo de spacy na extração de termos pode atingir um desempenho significativamente maior e, portanto, decidi incluir o modelo aqui.
Para uma comparação com os algoritmos simbólicos da AI, consulte Precision. Observe que apenas a escore F, a precisão e a precisão foram tomadas aqui ainda para o modelo, mas para os algoritmos, o AVP foi considerado tão diretamente comparando as métricas não faria sentido.
| Url | F-score (%) | Precisão (%) | Lembrar (%) |
|---|---|---|---|
| https://github.com/kevinlu1248/pyate/releases/download/v0.4.2/en_acl_terms_sm-2.0.4.tar.gz | 94.71 | 95.41 | 94.03 |
O modelo foi treinado e avaliado no conjunto de dados da ACL, que é um conjunto de dados orientado para ciência da computação, onde os termos são escolhidos manualmente. No entanto, isso ainda não foi testado em outros campos.
Este modelo não vem com pyate. Para instalar, execute
pip install https://github.com/kevinlu1248/pyate/releases/download/v0.4.2/en_acl_terms_sm-2.0.4.tar.gzPara extrair termos,
import spacy
nlp = spacy . load ( "en_acl_terms_sm" )
doc = nlp ( "Hello world, I am a term extraction algorithm." )
print ( doc . ents )
"""
(term extraction, algorithm)
""" Aqui está a precisão média de alguns dos algoritmos implementados usando a métrica de precisão média (AVP) em sete bancos de dados distintos, conforme testado em Astrakhantsev 2016.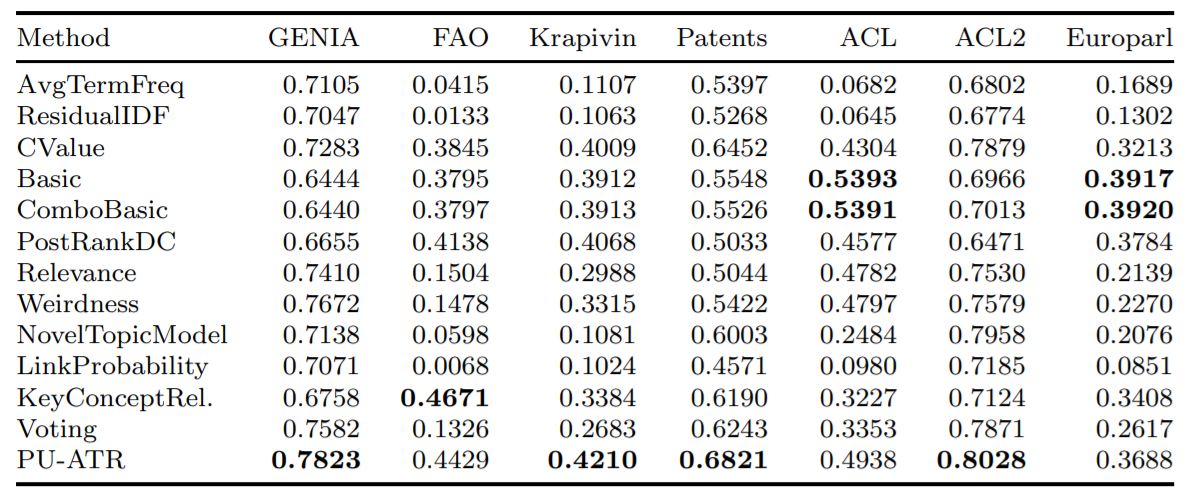
Este projeto foi planejado para ser uma ferramenta a ser conectada a uma extensão do Google Chrome que destaca e define os termos -chave que o leitor provavelmente não conhece. Além disso, a extração de termos é uma área em que não há muitas pesquisas focadas em comparação com outras áreas da PNL e, especialmente, recentemente, não é visto como muito prático devido à ferramenta mais geral da marcação de NER. No entanto, a marcação moderna do NER geralmente incorpora alguma combinação de palavras memorizadas e aprendizado profundo que são espaciais e computacionalmente pesados. Além disso, para generalizar um algoritmo para reconhecer os termos nas áreas em constante crescimento da pesquisa médica e de IA, uma lista de palavras memorizadas não o fará.
Dos cinco algoritmos implementados, nenhum é caro, de fato, o gargalo das despesas de alocação e computação de espaço é do modelo Spacy e da marcação de POS Spacy. Isso ocorre porque eles dependem principalmente de padrões de PDV, frequências de palavras e a existência de candidatos a termos incorporados. Por exemplo, o termo candidato "câncer de mama" implica que "câncer de mama maligno" provavelmente não é um termo e simplesmente uma forma de "câncer de mama" que é "maligno" (implementado em valor C).
Parece que não consigo encontrar os papéis básicos e básicos originais, mas encontrei papéis que os referenciam. "ATR4S: Kit de ferramentas com métodos de reconhecimento de termos automáticos de última geração em Scala" mais ou menos resume tudo e incorpora vários algoritmos que não estão neste pacote.
Se você publicar um trabalho que usa Pyate, informe -me em [email protected] e cite como:
Lu, Kevin. (2021, June 28). kevinlu1248/pyate: Python Automated Term Extraction (Version v0.5.3). Zenodo. http://doi.org/10.5281/zenodo.5039289
ou equivalentemente com bibtext:
@software{pyate,
title = {kevinlu1248/pyate: Python Automated Term Extraction},
author = {Lu, Kevin},
year = 2021,
month = {Jun},
publisher = {Zenodo},
doi = {10.5281/zenodo.5039289}
}
Este pacote foi usado no artigo (Extração de termos de domínio técnico não supervisionado usando o Extrator de termo (Dowlagar e Mamidi, 2021).
Se meu trabalho o ajudar, considere me comprar um café em https://www.buymeacoffee.com/kevinlu1248.


