pyate
Initial Release for Zenodo
Implementación de Python de algoritmos de extracción de término como valor C, básico, combo básico, rareza y extractor de términos utilizando etiquetas de pos.
Nuevo: La documentación se puede encontrar en https://kevinlu1248.github.io/pyate/. Hasta ahora, a la documentación todavía le faltan dos algoritmos y detalles sobre la clase TermExtraction , pero pronto lo haré.
Nuevo: Pruebe los algoritmos en https://pyate-demo.herokuapp.com/, ¡una aplicación web para demostrar Pyate!
Nuevo: ¡Spacy V3 es compatible! Para Spacy V2, use pyate==0.4.3 y vea el archivo Spacy V2 Readme.md
Si tiene una sugerencia para otro algoritmo ATE que desea implementarse en este paquete, no dude en presentarlo como un problema con el documento en el que se basa el algoritmo.
Para los paquetes Ate implementados en Scala y Java, ver ATR4 y Jate, respectivamente.
Usando PIP:
pip install pyate
spacy download en_core_web_sm Para comenzar, simplemente llame a uno de los algoritmos implementados. Según Astrakhantsev 2016, combo_basic es el más preciso de los cinco algoritmos, aunque basic y cvalues no están muy lejos (ver precisión). El mismo estudio muestra que PU-ATR y KeyConCeptrel tienen una precisión más alta que combo_basic , pero no se implementan y PU-ATR lleva significativamente más tiempo, ya que utiliza el aprendizaje automático.
from pyate import combo_basic
# source: https://www.ncbi.nlm.nih.gov/pmc/articles/PMC1994795/
string = """Central to the development of cancer are genetic changes that endow these “cancer cells” with many of the
hallmarks of cancer, such as self-sufficient growth and resistance to anti-growth and pro-death signals. However, while the
genetic changes that occur within cancer cells themselves, such as activated oncogenes or dysfunctional tumor suppressors,
are responsible for many aspects of cancer development, they are not sufficient. Tumor promotion and progression are
dependent on ancillary processes provided by cells of the tumor environment but that are not necessarily cancerous
themselves. Inflammation has long been associated with the development of cancer. This review will discuss the reflexive
relationship between cancer and inflammation with particular focus on how considering the role of inflammation in physiologic
processes such as the maintenance of tissue homeostasis and repair may provide a logical framework for understanding the U
connection between the inflammatory response and cancer."""
print ( combo_basic ( string ). sort_values ( ascending = False ))
""" (Output)
dysfunctional tumor 1.443147
tumor suppressors 1.443147
genetic changes 1.386294
cancer cells 1.386294
dysfunctional tumor suppressors 1.298612
logical framework 0.693147
sufficient growth 0.693147
death signals 0.693147
many aspects 0.693147
inflammatory response 0.693147
tumor promotion 0.693147
ancillary processes 0.693147
tumor environment 0.693147
reflexive relationship 0.693147
particular focus 0.693147
physiologic processes 0.693147
tissue homeostasis 0.693147
cancer development 0.693147
dtype: float64
""" Si desea agregar esto a una tubería de Spacy, simplemente use el método add_pipe de Agregar Spacy.
import spacy
from pyate . term_extraction_pipeline import TermExtractionPipeline
nlp = spacy . load ( "en_core_web_sm" )
nlp . add_pipe ( "combo_basic" )
doc = nlp ( string )
print ( doc . _ . combo_basic . sort_values ( ascending = False ). head ( 5 ))
""" (Output)
dysfunctional tumor 1.443147
tumor suppressors 1.443147
genetic changes 1.386294
cancer cells 1.386294
dysfunctional tumor suppressors 1.298612
dtype: float64
""" Además, TermExtractionPipeline.__init__ se define de la siguiente manera
__init__(
self,
func: Callable[..., pd.Series] = combo_basic,
*args,
**kwargs
)
Donde func es esencialmente su algoritmo de extracción de término que toma un corpus (ya sea una cadena o iterador de cadenas) y genera una serie de PANDAS de pares de términos de valores de términos y sus respectivas términos. func es por defecto combo_basic . args y kwargs son para que usted supere los valores predeterminados para la función, que puede encontrar ejecutando help (podría documentar más adelante).
Cada uno de cvalues, basic, combo_basic, weirdness y term_extractor toma una cadena o un iterador de cadenas y emite una serie PANDAS de pares de valor de término, donde los valores más altos indican una mayor probabilidad de ser un término específico de dominio. Además, weirdness y term_extractor toman un argumento de palabra clave general_corpus que debe ser un iterador de cadenas que predeterminan al corpus general que se describe a continuación.
All functions only take the string of which you would like to extract terms from as the mandatory input (the technical_corpus ), as well as other tweakable settings, including general_corpus (contrasting corpus for weirdness and term_extractor ), general_corpus_size , verbose (whether to print a progress bar), weights , smoothing , have_single_word (whether to have a single word count as a phrase) and threshold . Si no ha leído los documentos y no está familiarizado con los algoritmos, le recomiendo usar la configuración predeterminada. Nuevamente, use help para encontrar los detalles sobre cada algoritmo, ya que todos son diferentes.
En path/to/site-packages/pyate/default_general_domain.en.zip , hay un archivo CSV general de un corpus general, específicamente, 3000 oraciones aleatorias de Wikipedia. La fuente se puede encontrar en https://www.kaggle.com/mikeortman/wikipedia-sentences. Acceda a usarlo usando lo siguiente después de instalar pyate .
import pandas as pd
from distutils . sysconfig import get_python_lib
df = pd . read_csv ( get_python_lib () + "/pyate/default_general_domain.en.zip" )[ "SECTION_TEXT" ]
print ( df . head ())
""" (Output)
0 '''Anarchism''' is a political philosophy that...
1 The term ''anarchism'' is a compound word comp...
2 ===Origins=== n Woodcut from a Diggers document...
3 Portrait of philosopher Pierre-Joseph Proudhon...
4 consistent with anarchist values is a controve...
Name: SECTION_TEXT, dtype: object
""" Para cambiar los idiomas, simplemente ejecute Term_Extraction.set_language({language}, {model_name}) , donde model_name predeterminado al language . Por ejemplo, Term_Extraction.set_language("it", "it_core_news_sm"}) para italiano. Por defecto, el idioma es el inglés. Hasta ahora, la lista de idiomas compatibles es:
Para agregar más idiomas, presente un problema con un corpus de al menos 3000 párrafos de un dominio general en el idioma deseado (preferiblemente wikipedia) llamado default_general_domain.{lang}.zip https://www.loc.gov/standards/ISO639-2/php/code_list.php). El formato de archivo debe ser del siguiente formulario para ser parsable por PANDAS.
,SECTION_TEXT
0,"{paragraph_0}"
1,"{paragraph_1}"
...
Alternativamente, coloque el archivo en src/pyate y presente una solicitud de extracción.
Advertencia: el modelo solo funciona con Spacy V2.
Aunque este modelo estaba originalmente destinado a algoritmos simbólicos de IA (no de aprendizaje de máquinas), me di cuenta de que un modelo espacial en la extracción a término puede alcanzar un rendimiento significativamente mayor y, por lo tanto, decidí incluir el modelo aquí.
Para una comparación con los algoritmos simbólicos de IA, ver Precision. Tenga en cuenta que solo el puntaje F, la precisión y la precisión se tomaron aquí para el modelo, pero para los algoritmos se tomó el AVP, por lo que comparar directamente las métricas no tendría sentido.
| Url | Puntaje F (%) | Precisión (%) | Recordar (%) |
|---|---|---|---|
| https://github.com/kevinlu1248/pyate/releases/download/v0.4.2/en_acl_terms_sm-2.0.4.tar.gz | 94.71 | 95.41 | 94.03 |
El modelo fue capacitado y evaluado en el conjunto de datos de ACL, que es un conjunto de datos orientado a la informática donde los términos se eligen manualmente. Sin embargo, esto aún no se ha probado en otros campos.
Este modelo no viene con Pyate. Para instalar, ejecutar
pip install https://github.com/kevinlu1248/pyate/releases/download/v0.4.2/en_acl_terms_sm-2.0.4.tar.gzPara extraer términos,
import spacy
nlp = spacy . load ( "en_acl_terms_sm" )
doc = nlp ( "Hello world, I am a term extraction algorithm." )
print ( doc . ents )
"""
(term extraction, algorithm)
""" Aquí está la precisión promedio de algunos de los algoritmos implementados utilizando la métrica de precisión promedio (AVP) en siete bases de datos distintas, según lo probado en Astrakhantsev 2016.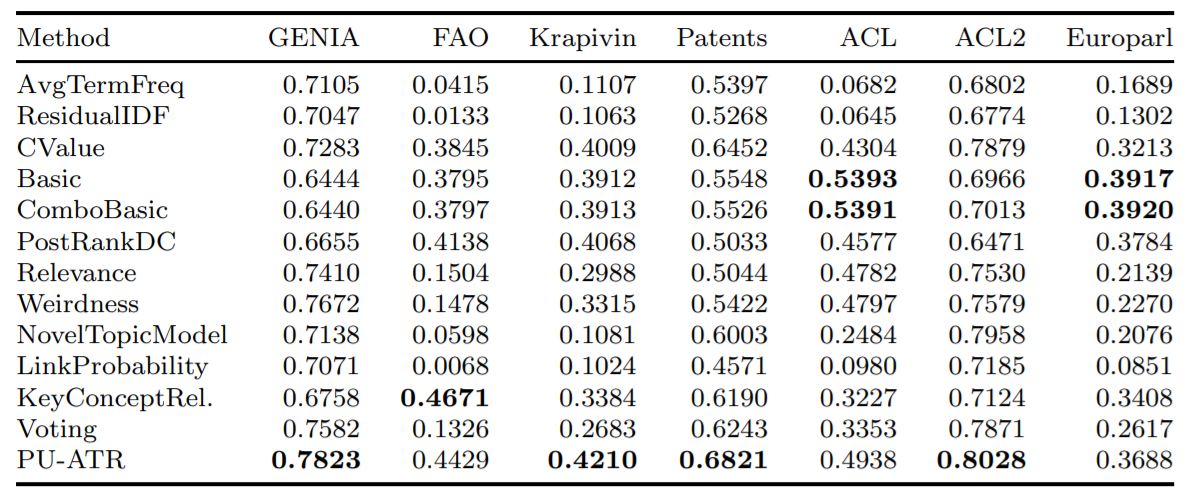
Se planeó que este proyecto fuera una herramienta para conectarse a una extensión de Google Chrome que resalte y define términos clave que el lector probablemente no conoce. Además, el término extracción es un área en la que no hay mucha investigación enfocada en comparación con otras áreas de PNL y, especialmente, recientemente no se considera muy práctica debido a la herramienta más general del etiquetado NER. Sin embargo, el etiquetado NER moderno generalmente incorpora alguna combinación de palabras memorizadas y aprendizaje profundo que son espacial y computacionalmente pesados. Además, para generalizar un algoritmo para reconocer los términos en las áreas cada vez mayores de la investigación médica y de IA, no funcionará una lista de palabras memorizadas.
De los cinco algoritmos implementados, ninguno es costoso, de hecho, el cuello de botella del gasto de asignación de espacio y cálculo es del modelo de Spacy y el etiquetado de Spacy POS. Esto se debe a que principalmente confían simplemente en patrones de POS, frecuencias de palabras y la existencia de candidatos a término incrustados. Por ejemplo, el término candidato "cáncer de mama" implica que el "cáncer de mama maligno" probablemente no sea un término y simplemente una forma de "cáncer de mama" que es "maligno" (implementado en el valor C).
Parece que no puedo encontrar los documentos básicos y básicos originales, pero encontré documentos que los hicieron referencia. "ATR4S: Toolkit con métodos de reconocimiento de términos automáticos de última generación en Scala" resume más o menos todo e incorpora varios algoritmos que no están en este paquete.
Si publica un trabajo que usa Pyate, hágamelo saber en [email protected] y cite como:
Lu, Kevin. (2021, June 28). kevinlu1248/pyate: Python Automated Term Extraction (Version v0.5.3). Zenodo. http://doi.org/10.5281/zenodo.5039289
o de manera equivalente con bibtext:
@software{pyate,
title = {kevinlu1248/pyate: Python Automated Term Extraction},
author = {Lu, Kevin},
year = 2021,
month = {Jun},
publisher = {Zenodo},
doi = {10.5281/zenodo.5039289}
}
Este paquete se usó en el documento (extracción de términos de dominio técnico no supervisado utilizando extractor de término (Dowlagar y Mamidi, 2021).
Si mi trabajo lo ayudó, considere comprarme un café en https://www.buymeacoffee.com/kevinlu1248.


