pyate
Initial Release for Zenodo
Implementasi Python dari Algoritma Ekstraksi Term seperti C-Value, Basic, Combo Basic, Keanehan dan Ekstraktor Term Menggunakan Spacy POS Tagging.
Baru: Dokumentasi dapat ditemukan di https://kevinlu1248.github.io/pyate/. Dokumentasi sejauh ini masih kehilangan dua algoritma dan detail tentang kelas TermExtraction tetapi saya akan segera melakukannya.
Baru: Coba algoritma di https://pyate-demo.herokuapp.com/, aplikasi web untuk mendemonstrasikan pyate!
Baru: Spacy V3 didukung! Untuk Spacy V2, gunakan pyate==0.4.3 dan lihat file spacy v2 readme.md
Jika Anda memiliki saran untuk algoritma ATE lain yang ingin Anda terapkan dalam paket ini, jangan ragu untuk mengajukannya sebagai masalah dengan kertas yang menjadi dasar algoritma.
Untuk paket ATE yang diimplementasikan di Scala dan Java, lihat ATR4S dan Jate, masing -masing.
Menggunakan Pip:
pip install pyate
spacy download en_core_web_sm Untuk memulai, cukup panggil salah satu algoritma yang diimplementasikan. Menurut Astrakhantsev 2016, combo_basic adalah yang paling tepat dari lima algoritma, meskipun basic dan cvalues tidak terlalu jauh di belakang (lihat presisi). Studi yang sama menunjukkan bahwa PU-ATR dan KeyConCeptrel memiliki ketepatan yang lebih tinggi daripada combo_basic tetapi tidak diimplementasikan dan PU-ATR membutuhkan waktu lebih banyak karena menggunakan pembelajaran mesin.
from pyate import combo_basic
# source: https://www.ncbi.nlm.nih.gov/pmc/articles/PMC1994795/
string = """Central to the development of cancer are genetic changes that endow these “cancer cells” with many of the
hallmarks of cancer, such as self-sufficient growth and resistance to anti-growth and pro-death signals. However, while the
genetic changes that occur within cancer cells themselves, such as activated oncogenes or dysfunctional tumor suppressors,
are responsible for many aspects of cancer development, they are not sufficient. Tumor promotion and progression are
dependent on ancillary processes provided by cells of the tumor environment but that are not necessarily cancerous
themselves. Inflammation has long been associated with the development of cancer. This review will discuss the reflexive
relationship between cancer and inflammation with particular focus on how considering the role of inflammation in physiologic
processes such as the maintenance of tissue homeostasis and repair may provide a logical framework for understanding the U
connection between the inflammatory response and cancer."""
print ( combo_basic ( string ). sort_values ( ascending = False ))
""" (Output)
dysfunctional tumor 1.443147
tumor suppressors 1.443147
genetic changes 1.386294
cancer cells 1.386294
dysfunctional tumor suppressors 1.298612
logical framework 0.693147
sufficient growth 0.693147
death signals 0.693147
many aspects 0.693147
inflammatory response 0.693147
tumor promotion 0.693147
ancillary processes 0.693147
tumor environment 0.693147
reflexive relationship 0.693147
particular focus 0.693147
physiologic processes 0.693147
tissue homeostasis 0.693147
cancer development 0.693147
dtype: float64
""" Jika Anda ingin menambahkan ini ke pipa spacy, cukup gunakan metode add_pipe Add Spacy.
import spacy
from pyate . term_extraction_pipeline import TermExtractionPipeline
nlp = spacy . load ( "en_core_web_sm" )
nlp . add_pipe ( "combo_basic" )
doc = nlp ( string )
print ( doc . _ . combo_basic . sort_values ( ascending = False ). head ( 5 ))
""" (Output)
dysfunctional tumor 1.443147
tumor suppressors 1.443147
genetic changes 1.386294
cancer cells 1.386294
dysfunctional tumor suppressors 1.298612
dtype: float64
""" Juga, TermExtractionPipeline.__init__ didefinisikan sebagai berikut
__init__(
self,
func: Callable[..., pd.Series] = combo_basic,
*args,
**kwargs
)
Di mana func pada dasarnya adalah istilah Anda mengekstraksi algoritma yang mengambil corpus (baik string atau iterator string) dan menghasilkan serangkaian panda dari pasangan istilah istilah dan istilah masing-masing. func adalah secara default combo_basic . args dan kwargs adalah untuk Anda untuk melampaui nilai default untuk fungsi, yang dapat Anda temukan dengan menjalankan help (mungkin mendokumentasikan nanti).
Masing-masing cvalues, basic, combo_basic, weirdness dan term_extractor mengambil string atau iterator string dan output serangkaian panda dari pasangan nilai istilah, di mana nilai yang lebih tinggi menunjukkan peluang lebih tinggi untuk menjadi istilah spesifik domain. Selain itu, weirdness dan term_extractor mengambil argumen kata kunci general_corpus yang harus menjadi iterator string yang default ke corpus umum yang dijelaskan di bawah ini.
All functions only take the string of which you would like to extract terms from as the mandatory input (the technical_corpus ), as well as other tweakable settings, including general_corpus (contrasting corpus for weirdness and term_extractor ), general_corpus_size , verbose (whether to print a progress bar), weights , smoothing , have_single_word (whether to have a single word count as a phrase) and threshold . Jika Anda belum membaca makalah dan tidak terbiasa dengan algoritma, saya sarankan hanya menggunakan pengaturan default. Sekali lagi, gunakan help untuk menemukan detail mengenai setiap algoritma karena semuanya berbeda.
Di bawah path/to/site-packages/pyate/default_general_domain.en.zip , ada file CSV umum dari korpus umum, khususnya, 3000 kalimat acak dari Wikipedia. Sumbernya dapat ditemukan di https://www.kaggle.com/mikeortman/wikipedia-sentences. Akses menggunakannya menggunakan yang berikut setelah menginstal pyate .
import pandas as pd
from distutils . sysconfig import get_python_lib
df = pd . read_csv ( get_python_lib () + "/pyate/default_general_domain.en.zip" )[ "SECTION_TEXT" ]
print ( df . head ())
""" (Output)
0 '''Anarchism''' is a political philosophy that...
1 The term ''anarchism'' is a compound word comp...
2 ===Origins=== n Woodcut from a Diggers document...
3 Portrait of philosopher Pierre-Joseph Proudhon...
4 consistent with anarchist values is a controve...
Name: SECTION_TEXT, dtype: object
""" Untuk beralih bahasa, cukup jalankan Term_Extraction.set_language({language}, {model_name}) , di mana model_name default ke language . Misalnya, Term_Extraction.set_language("it", "it_core_news_sm"}) untuk Italia. Secara default, bahasanya adalah bahasa Inggris. Sejauh ini, daftar bahasa yang didukung adalah:
Untuk menambahkan lebih banyak bahasa, ajukan masalah dengan korpus setidaknya 3000 paragraf dari domain umum dalam bahasa yang diinginkan (lebih disukai wikipedia) bernama default_general_domain.{lang}.zip menggantikan bahasa dengan kode iso-639-1 (atau ISO-639. https://www.loc.gov/standards/iso639-2/php/code_list.php). Format file harus dari bentuk berikut untuk dielakkan oleh panda.
,SECTION_TEXT
0,"{paragraph_0}"
1,"{paragraph_1}"
...
Atau, tempatkan file di src/pyate dan mengajukan permintaan tarik.
Peringatan: Model ini hanya berfungsi dengan Spacy V2.
Meskipun model ini awalnya dimaksudkan untuk algoritma AI simbolik (pembelajaran non-mesin), saya menyadari model spacy pada ekstraksi istilah dapat mencapai kinerja yang jauh lebih tinggi, dan dengan demikian memutuskan untuk memasukkan model di sini.
Untuk perbandingan dengan algoritma AI simbolik, lihat presisi. Perhatikan bahwa hanya f-score, akurasi, dan presisi yang diambil di sini untuk model, tetapi untuk algoritma AVP diambil sehingga secara langsung membandingkan metrik tidak akan masuk akal.
| Url | F-score (%) | Presisi (%) | Mengingat (%) |
|---|---|---|---|
| https://github.com/kevinlu1248/pyate/releases/download/v0.4.2/en_acl_terms_sm-2.0.4.tar.gz | 94.71 | 95.41 | 94.03 |
Model ini dilatih dan dievaluasi pada dataset ACL, yang merupakan dataset berorientasi ilmu komputer di mana persyaratan dipilih secara manual. Namun, ini belum diuji di bidang lain.
Model ini tidak datang dengan Pyate. Untuk menginstal, jalankan
pip install https://github.com/kevinlu1248/pyate/releases/download/v0.4.2/en_acl_terms_sm-2.0.4.tar.gzUntuk mengekstrak istilah,
import spacy
nlp = spacy . load ( "en_acl_terms_sm" )
doc = nlp ( "Hello world, I am a term extraction algorithm." )
print ( doc . ents )
"""
(term extraction, algorithm)
""" Berikut adalah ketepatan rata -rata dari beberapa algoritma yang diimplementasikan menggunakan metrik presisi rata -rata (AVP) pada tujuh database yang berbeda, seperti yang diuji dalam Astrakhantsev 2016. 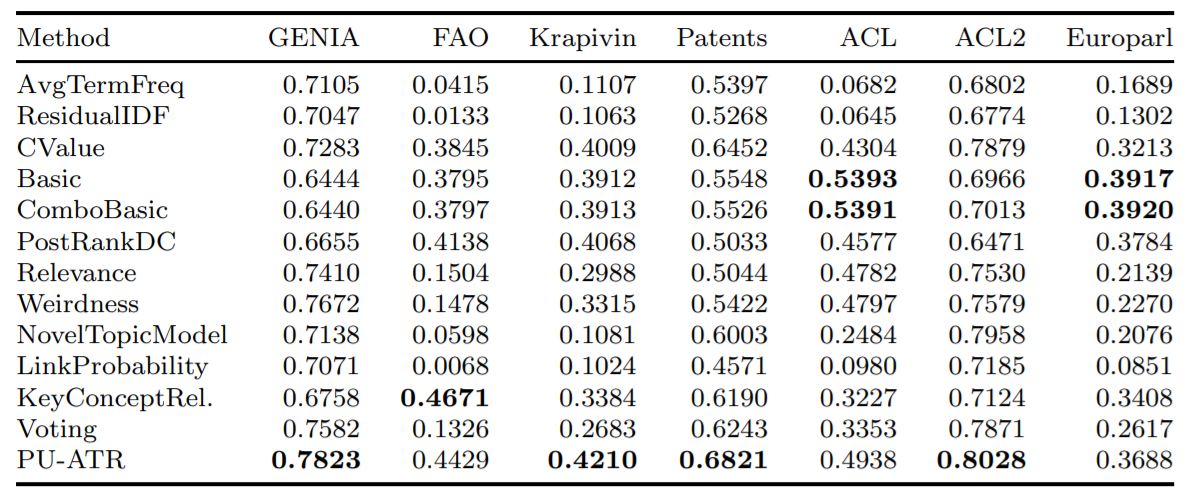
Proyek ini direncanakan untuk menjadi alat untuk dihubungkan ke ekstensi Google Chrome yang menyoroti dan mendefinisikan istilah -istilah kunci yang mungkin tidak diketahui oleh pembaca. Selain itu, ekstraksi istilah adalah area di mana tidak ada banyak penelitian terfokus pada dibandingkan dengan bidang NLP lainnya dan terutama baru -baru ini tidak dipandang sangat praktis karena alat penandaan NER yang lebih umum. Namun, penandaan NER modern biasanya menggabungkan beberapa kombinasi kata -kata yang dihafal dan pembelajaran mendalam yang secara spasial dan komputasi berat. Selain itu, untuk menggeneralisasi suatu algoritma untuk mengenali istilah -istilah ke bidang penelitian medis dan AI yang terus berkembang, daftar kata -kata yang dihafal tidak akan melakukannya.
Dari lima algoritma yang diimplementasikan, tidak ada yang mahal, pada kenyataannya, hambatan alokasi ruang dan biaya perhitungan berasal dari model spacy dan penandaan spacy POS. Ini karena mereka sebagian besar hanya mengandalkan pola POS, frekuensi kata, dan keberadaan kandidat istilah tertanam. Sebagai contoh, istilah kandidat "kanker payudara" menyiratkan bahwa "kanker payudara ganas" mungkin bukan istilah dan hanya bentuk "kanker payudara" yang "ganas" (diimplementasikan dalam nilai-C).
Sepertinya saya tidak dapat menemukan makalah dasar dasar dan kombo yang asli tetapi saya menemukan makalah yang merujuk mereka. "ATR4S: Toolkit dengan metode pengenalan istilah otomatis canggih di Scala" lebih atau kurang merangkum semuanya dan menggabungkan beberapa algoritma yang tidak ada dalam paket ini.
Jika Anda mempublikasikan karya yang menggunakan Pyate, beri tahu saya di [email protected] dan mengutip sebagai:
Lu, Kevin. (2021, June 28). kevinlu1248/pyate: Python Automated Term Extraction (Version v0.5.3). Zenodo. http://doi.org/10.5281/zenodo.5039289
atau setara dengan Bibtext:
@software{pyate,
title = {kevinlu1248/pyate: Python Automated Term Extraction},
author = {Lu, Kevin},
year = 2021,
month = {Jun},
publisher = {Zenodo},
doi = {10.5281/zenodo.5039289}
}
Paket ini digunakan dalam makalah (ekstraksi istilah domain teknis tanpa pengawasan menggunakan istilah ekstraktor (Dowlagar dan Mamidi, 2021).
Jika pekerjaan saya membantu Anda, harap pertimbangkan untuk membelikan saya kopi di https://www.buyaceacoffee.com/kevinlu1248.


