pyate
Initial Release for Zenodo
Spacy POSタグ付けを使用したC値、基本、コンボベーシック、奇妙さ、用語抽出器などのターム抽出アルゴリズムのPython実装。
新しい:ドキュメントはhttps://kevinlu1248.github.io/pyate/にあります。これまでのところ、ドキュメントにはまだ2つのアルゴリズムとTermExtractionクラスに関する詳細がありませんが、すぐに完了します。
新しい:PyateをデモンストレーションするためのWebアプリであるhttps://pyate-demo.herokuapp.com/でアルゴリズムを試してみてください!
新規:Spacy V3がサポートされています! Spacy V2の場合、 pyate==0.4.3を使用し、Spacy V2 readme.mdファイルを表示します
別のATEアルゴリズムの提案がある場合は、このパッケージに実装したい場合は、アルゴリズムが基づいているペーパーの問題としてお気軽に提出してください。
ScalaとJavaに実装されたATEパッケージについては、それぞれATR4SとJATEを参照してください。
PIPの使用:
pip install pyate
spacy download en_core_web_sm開始するには、実装されたアルゴリズムの1つを呼び出すだけです。 Astrakhantsev 2016によると、 combo_basic 5つのアルゴリズムの中で最も正確ですが、 basicとcvaluesそれほど遅れていません(精度を参照)。同じ研究では、PU-ATRとKeyConceptrelがcombo_basicよりも高い精度を持っているが、実装されておらず、PU-ATRは機械学習を使用してからかなり時間がかかることを示しています。
from pyate import combo_basic
# source: https://www.ncbi.nlm.nih.gov/pmc/articles/PMC1994795/
string = """Central to the development of cancer are genetic changes that endow these “cancer cells” with many of the
hallmarks of cancer, such as self-sufficient growth and resistance to anti-growth and pro-death signals. However, while the
genetic changes that occur within cancer cells themselves, such as activated oncogenes or dysfunctional tumor suppressors,
are responsible for many aspects of cancer development, they are not sufficient. Tumor promotion and progression are
dependent on ancillary processes provided by cells of the tumor environment but that are not necessarily cancerous
themselves. Inflammation has long been associated with the development of cancer. This review will discuss the reflexive
relationship between cancer and inflammation with particular focus on how considering the role of inflammation in physiologic
processes such as the maintenance of tissue homeostasis and repair may provide a logical framework for understanding the U
connection between the inflammatory response and cancer."""
print ( combo_basic ( string ). sort_values ( ascending = False ))
""" (Output)
dysfunctional tumor 1.443147
tumor suppressors 1.443147
genetic changes 1.386294
cancer cells 1.386294
dysfunctional tumor suppressors 1.298612
logical framework 0.693147
sufficient growth 0.693147
death signals 0.693147
many aspects 0.693147
inflammatory response 0.693147
tumor promotion 0.693147
ancillary processes 0.693147
tumor environment 0.693147
reflexive relationship 0.693147
particular focus 0.693147
physiologic processes 0.693147
tissue homeostasis 0.693147
cancer development 0.693147
dtype: float64
"""これをスペイシーパイプラインに追加する場合は、Spacyのadd_pipeメソッドを追加するだけです。
import spacy
from pyate . term_extraction_pipeline import TermExtractionPipeline
nlp = spacy . load ( "en_core_web_sm" )
nlp . add_pipe ( "combo_basic" )
doc = nlp ( string )
print ( doc . _ . combo_basic . sort_values ( ascending = False ). head ( 5 ))
""" (Output)
dysfunctional tumor 1.443147
tumor suppressors 1.443147
genetic changes 1.386294
cancer cells 1.386294
dysfunctional tumor suppressors 1.298612
dtype: float64
"""また、 TermExtractionPipeline.__init__次のように定義されています
__init__(
self,
func: Callable[..., pd.Series] = combo_basic,
*args,
**kwargs
)
ここで、 funcは基本的に、コーパス(文字列または文字列の反復剤のいずれか)を取り入れ、用語とそれぞれの用語の一連の用語値ペアのパンダシリーズを出力するアルゴリズムを抽出する用語です。 funcはデフォルトでcombo_basicです。 argsとkwargs 、関数のデフォルト値をオーバー化するためのものですhelp
それぞれのcvalues, basic, combo_basic, weirdnessおよびterm_extractorは、文字列または文字列の反復因子を取り入れ、ターム値のペアのパンダシリーズを出力します。さらに、 weirdnessとterm_extractor 、以下に説明する一般的なコーパスのデフォルトでデフォルトである文字列の繰り返しでなければならないgeneral_corpusキーワード引数を取ります。
すべての関数は、必須入力( technical_corpus )として用語を抽出したい文字列のみを取り、 general_corpus ( weirdnessとterm_extractorの対照的なコーパス)、 general_corpus_size 、 verbose (print barを印刷するかどうか)、 smoothing (asingle as asingine ows as have_single_word )を含む他の微weights可能な設定を取得します。 threshold 。論文を読んでおらず、アルゴリズムに不慣れな場合は、デフォルト設定を使用することをお勧めします。繰り返しますが、 helpを使用して、各アルゴリズムがすべて異なるため、詳細を見つけます。
path/to/site-packages/pyate/default_general_domain.en.zipの下に、一般的なコーパスの一般的なCSVファイル、特にウィキペディアからの3000のランダムな文があります。そのソースは、https://www.kaggle.com/mikeortman/wikipedia-sentencesにあります。 pyateをインストールした後、以下を使用して使用してアクセスします。
import pandas as pd
from distutils . sysconfig import get_python_lib
df = pd . read_csv ( get_python_lib () + "/pyate/default_general_domain.en.zip" )[ "SECTION_TEXT" ]
print ( df . head ())
""" (Output)
0 '''Anarchism''' is a political philosophy that...
1 The term ''anarchism'' is a compound word comp...
2 ===Origins=== n Woodcut from a Diggers document...
3 Portrait of philosopher Pierre-Joseph Proudhon...
4 consistent with anarchist values is a controve...
Name: SECTION_TEXT, dtype: object
"""言語を切り替えるには、 Term_Extraction.set_language({language}, {model_name})を実行するだけで、 model_name languageにデフォルトです。たとえば、 Term_Extraction.set_language("it", "it_core_news_sm"})のイタリア語。デフォルトでは、言語は英語です。これまでのところ、サポートされている言語のリストは次のとおりです。
さらに多くの言語を追加するには、目的の言語の一般的なドメインの少なくとも3000段落のコーパスに問題を提出します( default_general_domain.{lang}.zipという名前のdefault_general_domainという名前のdefault_generalドメインの一般的なドメイン(できればwikipedia)。 https://www.loc.gov/standards/iso639-2/php/code_list.php)。ファイル形式は、パンダが解析できるように次の形式である必要があります。
,SECTION_TEXT
0,"{paragraph_0}"
1,"{paragraph_1}"
...
または、ファイルをsrc/pyateに配置して、プルリクエストをファイルします。
警告:モデルはSpacy V2でのみ動作します。
このモデルはもともとシンボリックAIアルゴリズム(非マシン学習)を目的としていましたが、ターム抽出に関するスペイシーモデルがかなり高いパフォーマンスに達する可能性があることに気付き、ここにモデルを含めることにしました。
シンボリックAIアルゴリズムとの比較については、精度を参照してください。モデルのFスコア、精度、精度のみがここでまだ取られていますが、アルゴリズムの場合、AVPはメトリックを直接比較することで実際には意味がありません。
| URL | fスコア(%) | 精度(%) | 想起 (%) |
|---|---|---|---|
| https://github.com/kevinlu1248/pyate/releases/download/v0.4.2/en_acl_terms_sm-2.0.4.tar.gz | 94.71 | 95.41 | 94.03 |
このモデルは、用語が手動で選択されるコンピューターサイエンス指向のデータセットであるACLデータセットでトレーニングおよび評価されました。ただし、これはまだ他のフィールドでテストされていません。
このモデルにはPyateが付属していません。インストールするには、実行します
pip install https://github.com/kevinlu1248/pyate/releases/download/v0.4.2/en_acl_terms_sm-2.0.4.tar.gz用語を抽出するには、
import spacy
nlp = spacy . load ( "en_acl_terms_sm" )
doc = nlp ( "Hello world, I am a term extraction algorithm." )
print ( doc . ents )
"""
(term extraction, algorithm)
""" Astrakhantsev 2016でテストされているように、7つの異なるデータベースの平均精度(AVP)メトリックを使用して、実装されたアルゴリズムの一部の平均精度を次に示します。 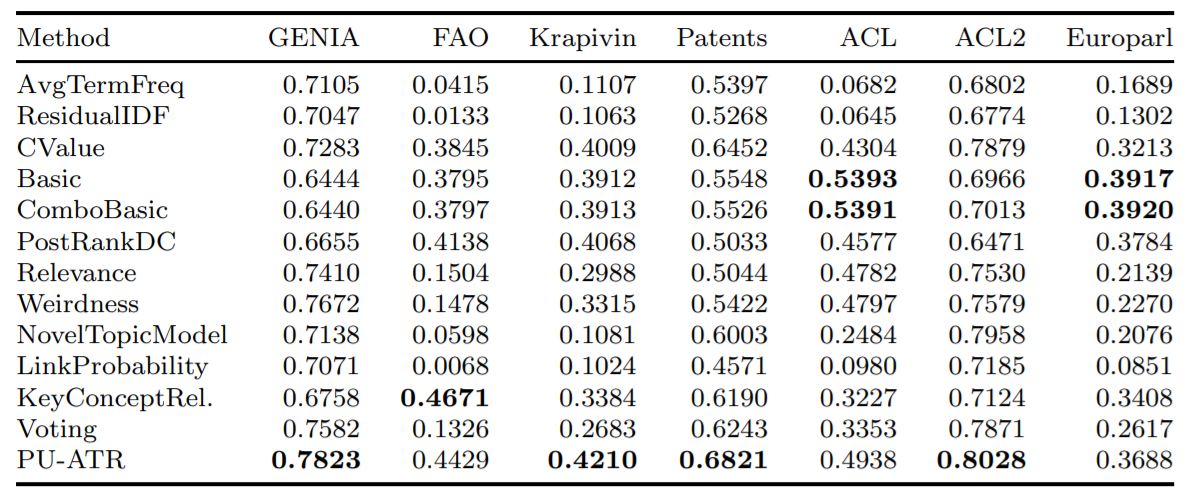
このプロジェクトは、読者がおそらく知らない重要な用語を強調および定義するGoogle Chrome拡張機能に接続するためのツールであることが計画されていました。さらに、用語抽出は、NLPの他の領域と比較して多くの集中的な研究がない領域であり、特に最近、NERタグ付けのより一般的なツールのために非常に実用的であるとは見なされていません。ただし、最新のNERタグ付けには、通常、覚えた単語と、空間的および計算的に重い深い学習の組み合わせが組み込まれています。さらに、アルゴリズムを一般化して、医療およびAIの研究の成長し続ける分野の用語を認識するために、記憶された言葉のリストはそうではありません。
実装された5つのアルゴリズムのうち、高価なものはありません。実際、スペースの割り当てと計算費用のボトルネックは、スペイシーモデルとSPACY POSタグ付けからのものです。これは、主にPOSパターン、単語頻度、埋め込まれた用語候補の存在だけに依存しているためです。たとえば、候補者「乳がん」という用語は、「悪性乳がん」がおそらく用語ではなく、単に「乳がん」の形であることを意味します。
オリジナルの基本的およびコンボの基本論文を見つけることができないようですが、それらを参照する論文を見つけました。 「ATR4S:SCALAで最先端の自動条件認識方法を備えたツールキット」は、多かれ少なかれすべてを要約し、このパッケージにないいくつかのアルゴリズムを組み込んでいます。
Pyateを使用する作品を公開する場合は、[email protected]でお知らせください。
Lu, Kevin. (2021, June 28). kevinlu1248/pyate: Python Automated Term Extraction (Version v0.5.3). Zenodo. http://doi.org/10.5281/zenodo.5039289
またはbibtextと同等に:
@software{pyate,
title = {kevinlu1248/pyate: Python Automated Term Extraction},
author = {Lu, Kevin},
year = 2021,
month = {Jun},
publisher = {Zenodo},
doi = {10.5281/zenodo.5039289}
}
このパッケージは、用紙で使用されました(項抽出器を使用した監視されていない技術ドメイン用語抽出(Dowlagar and Mamidi、2021)。
私の仕事があなたを助けたなら、https://www.buymeacoffee.com/kevinlu1248で私にコーヒーを買うことを検討してください。


