pyate
Initial Release for Zenodo
تنفيذ Python لخوارزميات استخراج المصطلح مثل القيمة C ، والسرد ، والسرد الأساسي ، والغرابة والمستخرج المصطلح باستخدام علامات POS Spacy.
جديد: يمكن العثور على الوثائق على https://kevinlu1248.github.io/pyate/. لا تزال الوثائق حتى الآن تفتقد خوارزميتين وتفاصيل حول فئة TermExtraction لكنني سأقوم بذلك قريبًا.
جديد: جرب الخوارزميات في https://pyate-demo.herokuapp.com/ ، تطبيق ويب لإظهار Pyate!
جديد: SPACY V3 مدعوم! ل spacy v2 ، استخدم pyate==0.4.3 وعرض ملف spacy v2 readme.md
إذا كان لديك اقتراح لخوارزمية ATE أخرى ، فأنت ترغب في تنفيذها في هذه الحزمة ، فلا تتردد في تقديمها كمشكلة مع الورقة التي تعتمد عليها الخوارزمية.
للحصول على حزم Ate التي تم تنفيذها في Scala و Java ، انظر ATR4s و Jate ، على التوالي.
باستخدام PIP:
pip install pyate
spacy download en_core_web_sm للبدء ، ما عليك سوى الاتصال بأحد الخوارزميات التي تم تنفيذها. وفقًا لـ Astrakhantsev 2016 ، يعد combo_basic هو الأكثر دقة من الخوارزميات الخمسة ، على الرغم من أن basic cvalues ليست بعيدة جدًا (انظر الدقة). تُظهر الدراسة نفسها أن PU-ATR و KeyConceptrel لديهم دقة أعلى من combo_basic ولكن لا يتم تنفيذها وأن PU-ATT يستغرق وقتًا أطول بكثير لأنه يستخدم التعلم الآلي.
from pyate import combo_basic
# source: https://www.ncbi.nlm.nih.gov/pmc/articles/PMC1994795/
string = """Central to the development of cancer are genetic changes that endow these “cancer cells” with many of the
hallmarks of cancer, such as self-sufficient growth and resistance to anti-growth and pro-death signals. However, while the
genetic changes that occur within cancer cells themselves, such as activated oncogenes or dysfunctional tumor suppressors,
are responsible for many aspects of cancer development, they are not sufficient. Tumor promotion and progression are
dependent on ancillary processes provided by cells of the tumor environment but that are not necessarily cancerous
themselves. Inflammation has long been associated with the development of cancer. This review will discuss the reflexive
relationship between cancer and inflammation with particular focus on how considering the role of inflammation in physiologic
processes such as the maintenance of tissue homeostasis and repair may provide a logical framework for understanding the U
connection between the inflammatory response and cancer."""
print ( combo_basic ( string ). sort_values ( ascending = False ))
""" (Output)
dysfunctional tumor 1.443147
tumor suppressors 1.443147
genetic changes 1.386294
cancer cells 1.386294
dysfunctional tumor suppressors 1.298612
logical framework 0.693147
sufficient growth 0.693147
death signals 0.693147
many aspects 0.693147
inflammatory response 0.693147
tumor promotion 0.693147
ancillary processes 0.693147
tumor environment 0.693147
reflexive relationship 0.693147
particular focus 0.693147
physiologic processes 0.693147
tissue homeostasis 0.693147
cancer development 0.693147
dtype: float64
""" إذا كنت ترغب في إضافة هذا إلى خط أنابيب Spacy ، فما عليك سوى استخدام طريقة add_pipe ADD SPACY.
import spacy
from pyate . term_extraction_pipeline import TermExtractionPipeline
nlp = spacy . load ( "en_core_web_sm" )
nlp . add_pipe ( "combo_basic" )
doc = nlp ( string )
print ( doc . _ . combo_basic . sort_values ( ascending = False ). head ( 5 ))
""" (Output)
dysfunctional tumor 1.443147
tumor suppressors 1.443147
genetic changes 1.386294
cancer cells 1.386294
dysfunctional tumor suppressors 1.298612
dtype: float64
""" أيضًا ، يتم تعريف TermExtractionPipeline.__init__ على النحو التالي
__init__(
self,
func: Callable[..., pd.Series] = combo_basic,
*args,
**kwargs
)
عندما يكون func أساسًا خوارزمية استخراج المصطلح الذي يأخذ في مجموعة (إما سلسلة أو مكرر للسلاسل) وتنتشر سلسلة من الأزواج ذات القيمة المدى من المصطلحات والمصطلحات الخاصة بها. func هو بشكل افتراضي combo_basic . args و kwargs هي بالنسبة لك للإفراط في القيم الافتراضية للوظيفة ، والتي يمكنك العثور عليها من خلال تشغيل help (قد توثق لاحقًا).
يأخذ كل من cvalues, basic, combo_basic, weirdness و term_extractor سلسلة أو مؤلف من الأوتار ويخرج سلسلة من الأزواج ذات القيمة المدى ، حيث تشير القيم العليا إلى فرصة أعلى لتصبح مصطلحًا محددًا للمجال. علاوة على ذلك ، تأخذ weirdness و term_extractor وسيطة general_corpus الرئيسية التي يجب أن تكون متكررة للسلاسل التي تتخلف عن السحمة العامة الموضحة أدناه.
جميع الوظائف تأخذ فقط السلسلة التي ترغب في استخراج المصطلحات من الإدخال الإلزامي ( technical_corpus ) ، وكذلك الإعدادات الأخرى القابلة للضبط ، بما في ذلك general_corpus (مجموعة متناقضة weirdness و term_extractor ) ، general_corpus_size ، verbose (سواء لطباعة شريط التقدم) ، weights ، smoothing have_single_word لها threshold إذا لم تكن قد قرأت الأوراق ولم تكن على دراية بالخوارزميات ، فإنني أوصي فقط باستخدام الإعدادات الافتراضية. مرة أخرى ، استخدم help للعثور على التفاصيل المتعلقة بكل خوارزمية لأنها مختلفة.
تحت path/to/site-packages/pyate/default_general_domain.en.zip ، هناك ملف CSV عام لجسم عام ، على وجه التحديد ، 3000 جملة عشوائية من ويكيبيديا. يمكن العثور على مصدر ذلك على https://www.kaggle.com/mikeortman/wikipedia-sentences. الوصول إليه باستخدامه باستخدام ما يلي بعد تثبيت pyate .
import pandas as pd
from distutils . sysconfig import get_python_lib
df = pd . read_csv ( get_python_lib () + "/pyate/default_general_domain.en.zip" )[ "SECTION_TEXT" ]
print ( df . head ())
""" (Output)
0 '''Anarchism''' is a political philosophy that...
1 The term ''anarchism'' is a compound word comp...
2 ===Origins=== n Woodcut from a Diggers document...
3 Portrait of philosopher Pierre-Joseph Proudhon...
4 consistent with anarchist values is a controve...
Name: SECTION_TEXT, dtype: object
""" للتبديل لغات ، ما عليك سوى تشغيل Term_Extraction.set_language({language}, {model_name}) ، حيث يتخلف model_name إلى language . على سبيل المثال ، Term_Extraction.set_language("it", "it_core_news_sm"}) للإيطالية. بشكل افتراضي ، اللغة الإنجليزية. حتى الآن ، قائمة اللغات المدعومة هي:
لإضافة المزيد من اللغات ، قم بتقديم مشكلة مع مجموعة لا يقل عن 3000 فقرات من المجال العام باللغة المطلوبة (ويفضل ويكيبيديا) المسماة default_general_domain.{lang}.zip https://www.loc.gov/standards/iso639-2/php/code_list.php). يجب أن يكون تنسيق الملف من النموذج التالي ليكون قابلاً للتطبيق بواسطة Pandas.
,SECTION_TEXT
0,"{paragraph_0}"
1,"{paragraph_1}"
...
بدلاً من ذلك ، ضع الملف في src/pyate وملف طلب سحب.
تحذير: النموذج يعمل فقط مع Spacy V2.
على الرغم من أن هذا النموذج كان مخصصًا في الأصل لخوارزميات AI الرمزية (التعلم غير الآلي) ، إلا أنني أدركت أن نموذج Spacy على استخراج المصطلحات يمكن أن يصل إلى أداء أعلى بشكل كبير ، وبالتالي قررت تضمين النموذج هنا.
لمقارنة خوارزميات AI الرمزية ، انظر الدقة. لاحظ أنه تم أخذ درجة F ودقة ودقة فقط هنا حتى الآن للنموذج ، ولكن بالنسبة للخوارزميات ، تم أخذ AVP ، وبالتالي فإن مقارنة المقاييس لن يكون لها معنى.
| عنوان URL | F-Score (٪) | دقة (٪) | يتذكر (٪) |
|---|---|---|---|
| https://github.com/kevinlu1248/pyate/release/download/v0.4.2/en_acl_terms_sm-2.0.4tar.gz | 94.71 | 95.41 | 94.03 |
تم تدريب النموذج وتقييمه على مجموعة بيانات ACL ، وهي مجموعة بيانات موجهة نحو علوم الكمبيوتر حيث يتم اختيار المصطلحات يدويًا. هذا لم يتم اختباره بعد في حقول أخرى حتى الآن.
هذا النموذج لا يأتي مع Pyate. للتثبيت ، تشغيل
pip install https://github.com/kevinlu1248/pyate/releases/download/v0.4.2/en_acl_terms_sm-2.0.4.tar.gzلاستخراج المصطلحات ،
import spacy
nlp = spacy . load ( "en_acl_terms_sm" )
doc = nlp ( "Hello world, I am a term extraction algorithm." )
print ( doc . ents )
"""
(term extraction, algorithm)
""" فيما يلي متوسط الدقة لبعض الخوارزميات التي تم تنفيذها باستخدام متوسط متوسط الدقة (AVP) على سبع قواعد بيانات متميزة ، كما تم اختبارها في Astrakhantsev 2016. 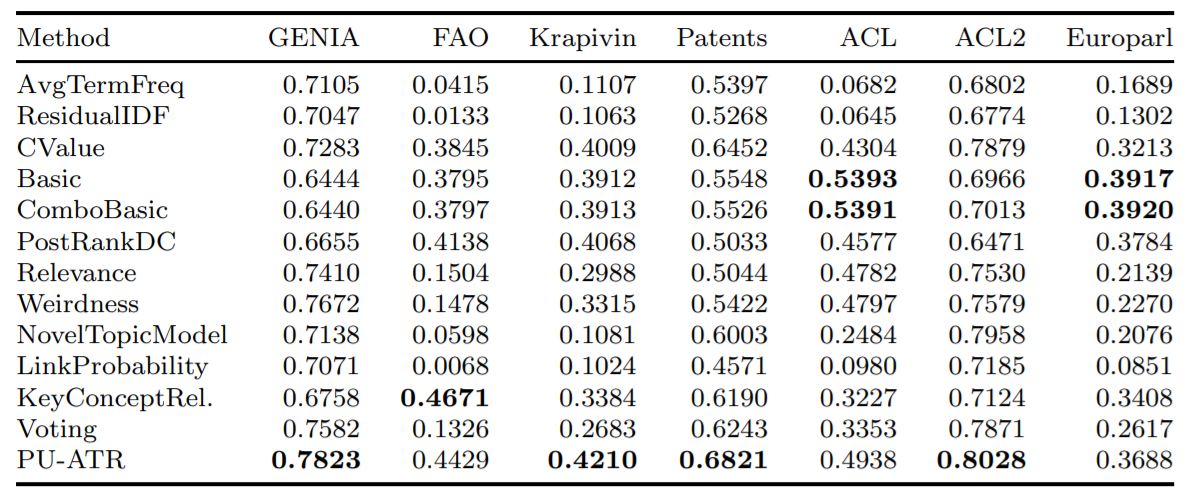
تم التخطيط لهذا المشروع ليكون أداة ليتم توصيلها بامتداد Google Chrome الذي يسلط الضوء ويحدد المصطلحات الرئيسية التي ربما لا يعرفها القارئ. علاوة على ذلك ، فإن استخراج المصطلحات هو مجال لا يوجد فيه الكثير من الأبحاث المركزة مقارنةً بالمجالات الأخرى من NLP وخاصةً لا يُنظر إليها مؤخرًا على أنها عملية للغاية بسبب الأداة الأكثر عمومية لعلامة NER. ومع ذلك ، فإن وضع علامات NER الحديثة عادة ما تتضمن مزيجًا من الكلمات المحفوظة والتعلم العميق والتي تكون ثقيلة من الناحية المكانية والرقصية. علاوة على ذلك ، لتعميم خوارزمية للتعرف على المصطلحات إلى المجالات المتنامية باستمرار من الأبحاث الطبية والبحوث الذكاء الاصطناعى ، لن تفعل قائمة الكلمات المحفوظة.
من بين الخوارزميات الخمسة التي تم تنفيذها ، لا شيء باهظ الثمن ، في الواقع ، عنق الزجاجة لتخصيص المساحة وحساب نفقات الحساب من نموذج Spacy و SPACY POS. وذلك لأنهم يعتمدون في الغالب ببساطة على أنماط نقاط البيع ، وترددات الكلمات ، ووجود المرشحين على المدى المدمج. على سبيل المثال ، يشير مصطلح "سرطان الثدي" المرشح إلى أن "سرطان الثدي الخبيث" ربما لا يكون مصطلحًا وببساطة شكل من أشكال "سرطان الثدي" الذي "خبيث" (يتم تنفيذه في القيمة C).
لا يمكنني العثور على الأوراق الأساسية الأساسية والسرد الأصلية ، لكنني وجدت أوراقًا أشار إليها. "ATR4S: مجموعة أدوات مع أحدث طرق التعرف على المصطلحات التلقائية في Scala" تلخص كل شيء أو أقل ودمج العديد من الخوارزميات وليس في هذه الحزمة.
إذا قمت بنشر عمل يستخدم Pyate ، فيرجى إبلاغي على [email protected] واستشهد بالـ:
Lu, Kevin. (2021, June 28). kevinlu1248/pyate: Python Automated Term Extraction (Version v0.5.3). Zenodo. http://doi.org/10.5281/zenodo.5039289
أو ما يعادل مع bibtext:
@software{pyate,
title = {kevinlu1248/pyate: Python Automated Term Extraction},
author = {Lu, Kevin},
year = 2021,
month = {Jun},
publisher = {Zenodo},
doi = {10.5281/zenodo.5039289}
}
تم استخدام هذه الحزمة في الورقة (استخراج شروط المجال الفني غير الخاضعة للإشراف باستخدام مستخرج المصطلح (Dowlagar و Mamidi ، 2021).
إذا ساعدك عملي ، فيرجى التفكير في شراء قهوة على https://www.buymeacoffee.com/kevinlu1248.


