pyate
Initial Release for Zenodo
Python-Implementierung von Term-Extraktionsalgorithmen wie C-Wert, Basic, Combo-Basic, Seltsamkeit und Begriffextraktor unter Verwendung von Spacy POS-Tagging.
Neu: Dokumentation finden Sie unter https://kevinlu1248.github.io/pyate/. In der bisherigen Dokumentation fehlt noch zwei Algorithmen und Details zur TermExtraction -Klasse, aber ich werde es bald erledigen lassen.
NEU: Probieren Sie die Algorithmen unter https://pyate-demo.herokuapp.com/, einer Web-App zum Demonstration von Pyate!
NEU: SPACY V3 wird unterstützt! Verwenden Sie für Spacy V2 pyate==0.4.3 und sehen Sie sich die Datei Spacy v2 Readme.md an
Wenn Sie einen Vorschlag für einen anderen ATE -Algorithmus haben, den Sie in diesem Paket implementieren möchten, können Sie es gerne als Problem mit dem Papier einreichen, auf dem der Algorithmus basiert.
Für ATE -Pakete in Scala und Java siehe ATR4S bzw. Jate.
Verwenden von PIP:
pip install pyate
spacy download en_core_web_sm Rufen Sie einfach einen der implementierten Algorithmen an. Laut Astrakhantsev 2016 ist combo_basic die genaueste der fünf Algorithmen, obwohl basic und cvalues nicht zu weit dahinter sind (siehe Präzision). Dieselbe Studie zeigt, dass PU-ATR und KeyConcePtrel eine höhere Genauigkeit haben als combo_basic , aber nicht implementiert sind und PU-ATR signifikant mehr Zeit in Anspruch nehmen, da es maschinelles Lernen verwendet.
from pyate import combo_basic
# source: https://www.ncbi.nlm.nih.gov/pmc/articles/PMC1994795/
string = """Central to the development of cancer are genetic changes that endow these “cancer cells” with many of the
hallmarks of cancer, such as self-sufficient growth and resistance to anti-growth and pro-death signals. However, while the
genetic changes that occur within cancer cells themselves, such as activated oncogenes or dysfunctional tumor suppressors,
are responsible for many aspects of cancer development, they are not sufficient. Tumor promotion and progression are
dependent on ancillary processes provided by cells of the tumor environment but that are not necessarily cancerous
themselves. Inflammation has long been associated with the development of cancer. This review will discuss the reflexive
relationship between cancer and inflammation with particular focus on how considering the role of inflammation in physiologic
processes such as the maintenance of tissue homeostasis and repair may provide a logical framework for understanding the U
connection between the inflammatory response and cancer."""
print ( combo_basic ( string ). sort_values ( ascending = False ))
""" (Output)
dysfunctional tumor 1.443147
tumor suppressors 1.443147
genetic changes 1.386294
cancer cells 1.386294
dysfunctional tumor suppressors 1.298612
logical framework 0.693147
sufficient growth 0.693147
death signals 0.693147
many aspects 0.693147
inflammatory response 0.693147
tumor promotion 0.693147
ancillary processes 0.693147
tumor environment 0.693147
reflexive relationship 0.693147
particular focus 0.693147
physiologic processes 0.693147
tissue homeostasis 0.693147
cancer development 0.693147
dtype: float64
""" Wenn Sie dies einer Spacy -Pipeline hinzufügen möchten, verwenden Sie einfach die add_pipe -Methode von Spact.
import spacy
from pyate . term_extraction_pipeline import TermExtractionPipeline
nlp = spacy . load ( "en_core_web_sm" )
nlp . add_pipe ( "combo_basic" )
doc = nlp ( string )
print ( doc . _ . combo_basic . sort_values ( ascending = False ). head ( 5 ))
""" (Output)
dysfunctional tumor 1.443147
tumor suppressors 1.443147
genetic changes 1.386294
cancer cells 1.386294
dysfunctional tumor suppressors 1.298612
dtype: float64
""" Auch TermExtractionPipeline.__init__ ist wie folgt definiert
__init__(
self,
func: Callable[..., pd.Series] = combo_basic,
*args,
**kwargs
)
Wenn func im Wesentlichen Ihr Begriff ist, der Algorithmus extrahiert, der einen Korpus (entweder einen String oder Iterator von Saiten) aufnimmt und eine PANDAS-Reihe von Termwertpaaren von Begriffen und deren jeweilige Termschaft ausgibt. func ist standardmäßig combo_basic . args und kwargs sind damit, dass Sie Standardwerte für die Funktion übergeben, die Sie durch Ausführen help finden können (möglicherweise später dokumentieren).
Jeder von cvalues, basic, combo_basic, weirdness und term_extractor nehmen eine Zeichenfolge oder einen Iterator von Zeichenfolgen auf und geben eine PANDAS-Reihe von Term-Wert-Paaren aus, bei denen höhere Werte eine höhere Wahrscheinlichkeit eines domänenspezifischen Terms anzeigen. Darüber hinaus nehmen weirdness und term_extractor ein general_corpus Argument für Schlüsselwort ein, das ein Iterator von Strings sein muss, das sich an den nachstehend beschriebenen allgemeinen Korpus standhält.
Alle Funktionen erfordern nur die Zeichenfolge, der Sie Begriffe als obligatorische Eingabe ( general_corpus_size technical_corpus ) sowie andere optimierbare Einstellungen, einschließlich general_corpus (kontrastierender Korpus für weights für weirdness smoothing term_extractor ), have_single_word verbose . threshold . Wenn Sie die Papiere nicht gelesen haben und mit den Algorithmen nicht vertraut sind, empfehle ich, nur die Standardeinstellungen zu verwenden. Verwenden Sie erneut help , um die Details zu jedem Algorithmus zu finden, da sie alle unterschiedlich sind.
Unter path/to/site-packages/pyate/default_general_domain.en.zip gibt es eine allgemeine CSV-Datei eines allgemeinen Korpus, insbesondere von 3000 zufälligen Sätzen aus Wikipedia. Die Quelle davon findet sich unter https://www.kaggle.com/mikeortman/wikipedia-sentences. Greifen Sie mit dem folgenden nach der Installation pyate darauf zu.
import pandas as pd
from distutils . sysconfig import get_python_lib
df = pd . read_csv ( get_python_lib () + "/pyate/default_general_domain.en.zip" )[ "SECTION_TEXT" ]
print ( df . head ())
""" (Output)
0 '''Anarchism''' is a political philosophy that...
1 The term ''anarchism'' is a compound word comp...
2 ===Origins=== n Woodcut from a Diggers document...
3 Portrait of philosopher Pierre-Joseph Proudhon...
4 consistent with anarchist values is a controve...
Name: SECTION_TEXT, dtype: object
""" Für das Wechseln von Sprachen führen Sie einfach Term_Extraction.set_language({language}, {model_name}) aus, wobei model_name standardmäßig die language stammt. Zum Beispiel für das Italiener Term_Extraction.set_language("it", "it_core_news_sm"}) . Standardmäßig ist die Sprache Englisch. Bisher lautet die Liste der unterstützten Sprachen:
Um weitere Sprachen hinzuzufügen, stellen Sie ein Problem mit einem Korpus von mindestens 3000 Absätzen einer allgemeinen Domäne in der gewünschten Sprache (vorzugsweise Wikipedia) mit dem Namen default_general_domain.{lang}.zip https://www.loc.gov/standards/iso639-2/php/code_list.php). Das Dateiformat sollte aus dem folgenden Formular ausgestattet sein, das von Pandas analysiert werden kann.
,SECTION_TEXT
0,"{paragraph_0}"
1,"{paragraph_1}"
...
Platzieren Sie die Datei alternativ in src/pyate und stellen Sie eine Pull -Anforderung ein.
WARNUNG: Das Modell funktioniert nur mit Spacy V2.
Obwohl dieses Modell ursprünglich für symbolische AI-Algorithmen (Nicht-Maschinen-Lernen) bestimmt war, habe ich festgestellt, dass ein Spacy-Modell zur Begriffextraktion eine signifikant höhere Leistung erreichen kann, und beschloss daher, das Modell hier einzubeziehen.
Für einen Vergleich mit den symbolischen AI -Algorithmen siehe Präzision. Beachten Sie, dass nur der F-Score, Genauigkeit und Präzision für das Modell noch für das Modell eingenommen wurden, aber für die Algorithmen wurde der AVP genommen, so
| URL | F-Score (%) | Präzision (%) | Abrufen (%) |
|---|---|---|---|
| https://github.com/kevinlu1248/pyate/releases/download/v0.4.2/en_acl_terms_sm-2.0.4tar.gz | 94.71 | 95.41 | 94.03 |
Das Modell wurde im ACL -Datensatz geschult und bewertet, einem Datensatz, in dem die Begriffe manuell ausgewählt werden. Dies wurde jedoch noch nicht auf anderen Bereichen getestet.
Dieses Modell kommt nicht mit Pyate. Zu installieren, ausführen
pip install https://github.com/kevinlu1248/pyate/releases/download/v0.4.2/en_acl_terms_sm-2.0.4.tar.gzBegriffe extrahieren,
import spacy
nlp = spacy . load ( "en_acl_terms_sm" )
doc = nlp ( "Hello world, I am a term extraction algorithm." )
print ( doc . ents )
"""
(term extraction, algorithm)
""" Hier finden Sie die durchschnittliche Genauigkeit einiger der implementierten Algorithmen, die die durchschnittliche Präzisionsmetrik (AVP) für sieben verschiedene Datenbanken unter Verwendung der in Astrakhantsev 2016 getesteten Datenbanken getestet haben. 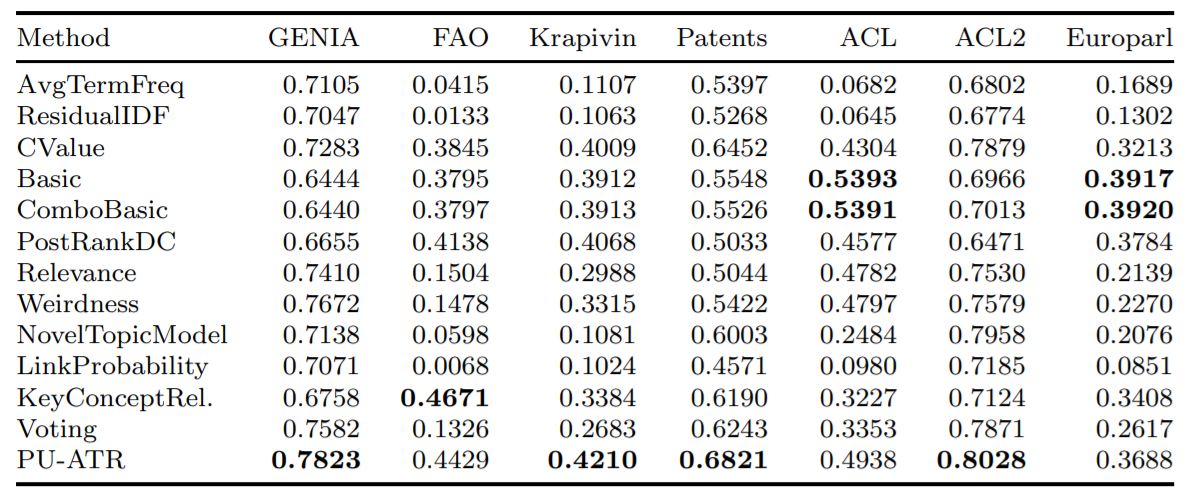
Dieses Projekt sollte ein Tool sein, das mit einer Google Chrome -Erweiterung verbunden werden soll, die wichtige Begriffe hervorhebt und definiert, von denen der Leser wahrscheinlich nicht kennt. Darüber hinaus ist die Term -Extraktion ein Bereich, in dem es nicht viele fokussierte Untersuchungen zu anderen Bereichen von NLP gibt und vor kurzem aufgrund des allgemeineren Instruments des NER -Tagging nicht als sehr praktisch angesehen wird. Das moderne Ner -Tagging enthält jedoch normalerweise eine Kombination aus gemerkten Wörtern und tiefem Lernen, die räumlich und rechnerisch schwer sind. Um einen Algorithmus zu verallgemeinern, um Begriffe auf die ständig wachsenden Bereiche der medizinischen und kI -Forschung zu erkennen, wird eine Liste von auswendig gemehrten Wörtern nicht der Fall sein.
Von den fünf implementierten Algorithmen ist keiner teuer. Der Engpass der Space Allocation and Rechenaufwand stammt aus dem Spacy -Modell und dem Spacy POS -Tagging. Dies liegt daran, dass sie sich hauptsächlich nur auf POS -Muster, Wortfrequenzen und die Existenz von eingebetteten Kandidaten verlassen. Zum Beispiel impliziert der Begriff Kandidat "Brustkrebs", dass "maligner Brustkrebs" wahrscheinlich kein Begriff und einfach eine Form von "Brustkrebs" ist, die "bösartig" ist (im C-Wert umgesetzt).
Ich kann die ursprünglichen Basis- und Combo -Basispapiere anscheinend nicht finden, aber ich habe Papiere gefunden, die sie bezog. "ATR4S: Toolkit mit hochmodernen automatischen Begriffen-Erkennungsmethoden in Scala" fasst mehr oder weniger alles zusammen und enthält mehrere Algorithmen, die nicht in dieses Paket sind.
Wenn Sie Arbeiten veröffentlichen, die Pyate verwenden, lassen Sie es mich bitte unter [email protected] wissen und zitieren Sie als:
Lu, Kevin. (2021, June 28). kevinlu1248/pyate: Python Automated Term Extraction (Version v0.5.3). Zenodo. http://doi.org/10.5281/zenodo.5039289
oder äquivalent mit Bibtext:
@software{pyate,
title = {kevinlu1248/pyate: Python Automated Term Extraction},
author = {Lu, Kevin},
year = 2021,
month = {Jun},
publisher = {Zenodo},
doi = {10.5281/zenodo.5039289}
}
Dieses Paket wurde im Papier verwendet (nicht überwachte technische Domänen -Begriffe Extraktion unter Verwendung des Term Extractors (Dowlagar und Mamidi, 2021).
Wenn meine Arbeit Ihnen geholfen hat, kaufen Sie mir bitte einen Kaffee unter https://www.buymaacoffee.com/kevinlu1248.


