pyate
Initial Release for Zenodo
Реализация Python Алгоритмов извлечения терминов, таких как C-значение, базовое, комбинированное базовое, странность и термин-экстрактор с использованием тега Spacy POS.
Новое: документация можно найти по адресу https://kevinlu1248.github.io/pyate/. До сих пор в документации все еще не хватает двух алгоритмов и подробностей о классе TermExtraction , но я скоро сделаю это.
Новое: попробуйте алгоритмы на https://pyate-demo.herokuapp.com/, веб-приложение для демонстрации Pyate!
Новое: Spacy V3 поддерживается! Для Spacy v2 используйте pyate==0.4.3 и просмотрите файл Spacy v2 redectme.md
Если у вас есть предложение для другого алгоритма ATE, который вы хотели бы внедрить в этом пакете, не стесняйтесь подать его в качестве проблемы с статьей, на которой основан алгоритм.
Для ATE Packages, реализованных в Scala и Java, см. ATR4S и Jate, соответственно.
Использование PIP:
pip install pyate
spacy download en_core_web_sm Чтобы начать, просто позвоните в один из реализованных алгоритмов. Согласно Astrakhantsev 2016, combo_basic является наиболее точным из пяти алгоритмов, хотя basic и cvalues не слишком далеко (см. Точность). То же самое исследование показывает, что PU-ATR и KeyConceptrel имеют более высокую точность, чем combo_basic но не реализованы, и PU-ATR занимает значительно больше времени, поскольку оно использует машинное обучение.
from pyate import combo_basic
# source: https://www.ncbi.nlm.nih.gov/pmc/articles/PMC1994795/
string = """Central to the development of cancer are genetic changes that endow these “cancer cells” with many of the
hallmarks of cancer, such as self-sufficient growth and resistance to anti-growth and pro-death signals. However, while the
genetic changes that occur within cancer cells themselves, such as activated oncogenes or dysfunctional tumor suppressors,
are responsible for many aspects of cancer development, they are not sufficient. Tumor promotion and progression are
dependent on ancillary processes provided by cells of the tumor environment but that are not necessarily cancerous
themselves. Inflammation has long been associated with the development of cancer. This review will discuss the reflexive
relationship between cancer and inflammation with particular focus on how considering the role of inflammation in physiologic
processes such as the maintenance of tissue homeostasis and repair may provide a logical framework for understanding the U
connection between the inflammatory response and cancer."""
print ( combo_basic ( string ). sort_values ( ascending = False ))
""" (Output)
dysfunctional tumor 1.443147
tumor suppressors 1.443147
genetic changes 1.386294
cancer cells 1.386294
dysfunctional tumor suppressors 1.298612
logical framework 0.693147
sufficient growth 0.693147
death signals 0.693147
many aspects 0.693147
inflammatory response 0.693147
tumor promotion 0.693147
ancillary processes 0.693147
tumor environment 0.693147
reflexive relationship 0.693147
particular focus 0.693147
physiologic processes 0.693147
tissue homeostasis 0.693147
cancer development 0.693147
dtype: float64
""" Если вы хотите добавить это в трубопровод Spacy, просто используйте метод добавления Spacy's add_pipe .
import spacy
from pyate . term_extraction_pipeline import TermExtractionPipeline
nlp = spacy . load ( "en_core_web_sm" )
nlp . add_pipe ( "combo_basic" )
doc = nlp ( string )
print ( doc . _ . combo_basic . sort_values ( ascending = False ). head ( 5 ))
""" (Output)
dysfunctional tumor 1.443147
tumor suppressors 1.443147
genetic changes 1.386294
cancer cells 1.386294
dysfunctional tumor suppressors 1.298612
dtype: float64
""" Кроме того, TermExtractionPipeline.__init__ определяется следующим образом
__init__(
self,
func: Callable[..., pd.Series] = combo_basic,
*args,
**kwargs
)
где func , по сути, является вашим термином извлечения алгоритма, который принимает корпус (либо строка, либо итератор строк) и выводит серию паров терминов-значений Pandas и их соответствующих терминов. func по умолчанию combo_basic . args и kwargs для вас, чтобы перепродавать значения по умолчанию для функции, которую вы можете найти, запустив help (может документировать позже).
Каждый из cvalues, basic, combo_basic, weirdness и term_extractor получает строку или итератор строк и выводит серию пар термин-значений панд, где более высокие значения указывают на более высокую вероятность того, чтобы стать доменным термином. Кроме того, weirdness и term_extractor принимают аргумент ключевого слова general_corpus , который должен быть итератором строк, который по умолчанию в общий корпус, описанный ниже.
Все функции принимают только строку, из которой вы хотели бы извлечь термины из как обязательный ввод ( technical_corpus ), а также другие настройки, включая general_corpus (контрастный корпус для weirdness и term_extractor ), general_corpus_size , verbose (будь то напечатанный батер прогресса), weights , сглаживание, smoothing , have_single_word threshold Если вы не читали документы и не знакомы с алгоритмами, я рекомендую просто использовать настройки по умолчанию. Опять же, используйте help , чтобы найти детали, касающиеся каждого алгоритма, так как все они разные.
В path/to/site-packages/pyate/default_general_domain.en.zip существует общий файл CSV общего корпуса, в частности, 3000 случайных предложений из Википедии. Источник его можно найти по адресу https://www.kaggle.com/mikeortman/wikipedia-sentences. Получите доступ к нему, используя следующее после установки pyate .
import pandas as pd
from distutils . sysconfig import get_python_lib
df = pd . read_csv ( get_python_lib () + "/pyate/default_general_domain.en.zip" )[ "SECTION_TEXT" ]
print ( df . head ())
""" (Output)
0 '''Anarchism''' is a political philosophy that...
1 The term ''anarchism'' is a compound word comp...
2 ===Origins=== n Woodcut from a Diggers document...
3 Portrait of philosopher Pierre-Joseph Proudhon...
4 consistent with anarchist values is a controve...
Name: SECTION_TEXT, dtype: object
""" Для переключения языков просто запустите Term_Extraction.set_language({language}, {model_name}) , где model_name по умолчанию на language . Например, Term_Extraction.set_language("it", "it_core_news_sm"}) для итальянского. По умолчанию язык английский. Пока что список поддерживаемых языков:
Чтобы добавить больше языков, подайте проблему с корпусом не менее 3000 абзацев общего домена на желаемом языке (предпочтительно Википедия) с именем default_general_domain.{lang}.zip заменяющий Lang на ISO-639-1 кода языка, или iso-639-2, если язык не имеет ISO-639-1-1-1-1 (может быть, можно найти на языке. https://www.loc.gov/standards/iso639-2/php/code_list.php). Формат файла должен быть следующей формы, которая должна быть проведена с помощью Pandas.
,SECTION_TEXT
0,"{paragraph_0}"
1,"{paragraph_1}"
...
В качестве альтернативы поместите файл в src/pyate и подайте запрос на вытяжение.
ПРЕДУПРЕЖДЕНИЕ: Модель работает только со Spacy V2.
Несмотря на то, что эта модель была первоначально предназначена для символических алгоритмов искусственного интеллекта (немашиновое обучение), я понял, что модель SPACY на термин-экстракции может достичь значительно более высокой производительности и, таким образом, решил включить модель здесь.
Для сравнения с символическими алгоритмами ИИ см. Точность. Обратите внимание, что только F-оценка, точность и точность были взяты здесь для модели, но для алгоритмов AVP был взят, так что непосредственно сравнивать метрики на самом деле не имели бы смысла.
| URL | F-Score (%) | Точность (%) | Отзывать (%) |
|---|---|---|---|
| https://github.com/kevinlu1248/pyate/releases/download/v0.4.2/en_acl_terms_sm-2.0.4.tar.gz | 94,71 | 95,41 | 94.03 |
Модель была обучена и оценена на наборе данных ACL, который представляет собой набор данных, ориентированный на информатику, где термины выбираются вручную. Однако это еще не было проверено на других областях.
Эта модель не поставляется с Pyate. Чтобы установить, запустить
pip install https://github.com/kevinlu1248/pyate/releases/download/v0.4.2/en_acl_terms_sm-2.0.4.tar.gzДля извлечения терминов,
import spacy
nlp = spacy . load ( "en_acl_terms_sm" )
doc = nlp ( "Hello world, I am a term extraction algorithm." )
print ( doc . ents )
"""
(term extraction, algorithm)
""" Вот средняя точность некоторых реализованных алгоритмов с использованием показателя средней точности (AVP) в семи различных базах данных, как протестировано в Astrakhantsev 2016. 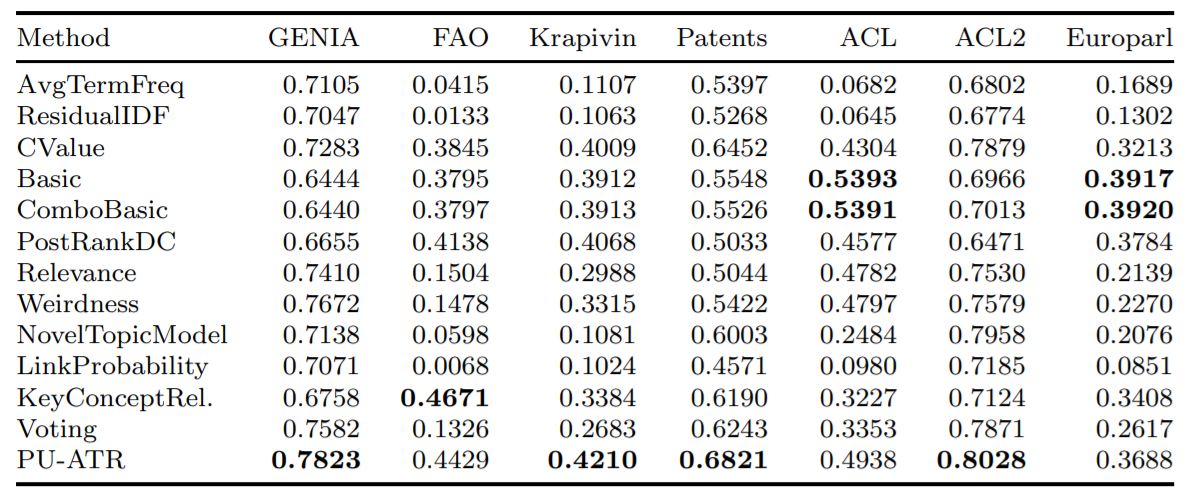
Этот проект планировал стать инструментом, который будет подключен к расширению Google Chrome, который подчеркивает и определяет ключевые термины, о которых читатель, вероятно, не знает. Кроме того, термин -извлечение - это область, где не так много целенаправленных исследований по сравнению с другими областями НЛП, и особенно в последнее время не считается очень практичным из -за более общего инструмента мечения NER. Тем не менее, современная метка NER обычно включает в себя некоторую комбинацию запоминающихся слов и глубокого обучения, которые являются пространственно и вычислительно тяжелыми. Кроме того, чтобы обобщить алгоритм, чтобы распознавать термины для постоянно растущих областей медицинских и исследований искусственного интеллекта, список запоминающихся слов не будет.
Из пяти реализованных алгоритмов ни один из них не является дорогостоящим, на самом деле, узкое место распределения пространства и вычислений из -за модели Spacy и тегов Spacy POS. Это связано с тем, что они в основном полагаются просто на закономерности POS, частоты слов и существование кандидатов в встроенные термины. Например, термин «рак молочной железы» подразумевает, что «злокачественный рак молочной железы», вероятно, не является термином и просто формой «рака молочной железы», которая является «злокачественным» (внедрено в C-значении).
Я не могу найти оригинальные базовые и комбинированные базовые бумаги, но я нашел документы, которые ссылались на них. «ATR4S: Toolkit с современными методами распознавания автоматических терминов в Scala» более или менее суммирует все и включает в себя несколько алгоритмов, не в этом пакете.
Если вы публикуете работу, в которой используется Pyate, пожалуйста, дайте мне знать по адресу [email protected] и цитируйте как:
Lu, Kevin. (2021, June 28). kevinlu1248/pyate: Python Automated Term Extraction (Version v0.5.3). Zenodo. http://doi.org/10.5281/zenodo.5039289
или эквивалентно с BibText:
@software{pyate,
title = {kevinlu1248/pyate: Python Automated Term Extraction},
author = {Lu, Kevin},
year = 2021,
month = {Jun},
publisher = {Zenodo},
doi = {10.5281/zenodo.5039289}
}
Этот пакет использовался в статье (неконтролируемая техническая домена извлечения с использованием термина -экстрактора (Dowlagar and Mamidi, 2021).
Если моя работа помогла вам, пожалуйста, подумайте о покупке кофе по адресу https://www.buymeacoffee.com/kevinlu1248.


