pyate
Initial Release for Zenodo
การใช้ Python ของอัลกอริทึมการสกัดคำเช่น C-value, Basic, Combo Basic, Weirdness และ Term Extractor โดยใช้การติดแท็ก POS
ใหม่: เอกสารสามารถพบได้ที่ https://kevinlu1248.github.io/pyate/ เอกสารจนถึงตอนนี้ยังคงหายไปสองอัลกอริทึมและรายละเอียดเกี่ยวกับคลาส TermExtraction แต่ฉันจะทำเสร็จเร็ว ๆ นี้
ใหม่: ลองอัลกอริทึมที่ https://pyate-demo.herokuapp.com/, เว็บแอพสำหรับแสดง pyate!
ใหม่: รองรับ Spacy V3! สำหรับ Spacy V2 ให้ใช้ pyate==0.4.3 และดูไฟล์ spacy v2 readme.md
หากคุณมีข้อเสนอแนะสำหรับอัลกอริทึม ATE อื่นที่คุณต้องการนำไปใช้ในแพ็คเกจนี้อย่าลังเลที่จะยื่นเป็นปัญหากับกระดาษอัลกอริทึมจะขึ้นอยู่กับ
สำหรับแพ็คเกจ ATE ที่ใช้ใน Scala และ Java ดู ATR4S และ Jate ตามลำดับ
ใช้ PIP:
pip install pyate
spacy download en_core_web_sm ในการเริ่มต้นใช้งานเพียงหนึ่งในอัลกอริทึมที่นำไปใช้ ตาม Astrakhantsev 2016, combo_basic เป็นอัลกอริทึมที่แม่นยำที่สุดของห้าอัลกอริทึมแม้ว่า basic และ cvalues จะไม่ไกลเกินกว่า (ดูความแม่นยำ) การศึกษาเดียวกันแสดงให้เห็นว่า PU-ATR และ KeyconcePtrel มีความแม่นยำสูงกว่า combo_basic แต่ไม่ได้ใช้งานและ PU-ATR ใช้เวลามากขึ้นอย่างมีนัยสำคัญเนื่องจากใช้การเรียนรู้ของเครื่อง
from pyate import combo_basic
# source: https://www.ncbi.nlm.nih.gov/pmc/articles/PMC1994795/
string = """Central to the development of cancer are genetic changes that endow these “cancer cells” with many of the
hallmarks of cancer, such as self-sufficient growth and resistance to anti-growth and pro-death signals. However, while the
genetic changes that occur within cancer cells themselves, such as activated oncogenes or dysfunctional tumor suppressors,
are responsible for many aspects of cancer development, they are not sufficient. Tumor promotion and progression are
dependent on ancillary processes provided by cells of the tumor environment but that are not necessarily cancerous
themselves. Inflammation has long been associated with the development of cancer. This review will discuss the reflexive
relationship between cancer and inflammation with particular focus on how considering the role of inflammation in physiologic
processes such as the maintenance of tissue homeostasis and repair may provide a logical framework for understanding the U
connection between the inflammatory response and cancer."""
print ( combo_basic ( string ). sort_values ( ascending = False ))
""" (Output)
dysfunctional tumor 1.443147
tumor suppressors 1.443147
genetic changes 1.386294
cancer cells 1.386294
dysfunctional tumor suppressors 1.298612
logical framework 0.693147
sufficient growth 0.693147
death signals 0.693147
many aspects 0.693147
inflammatory response 0.693147
tumor promotion 0.693147
ancillary processes 0.693147
tumor environment 0.693147
reflexive relationship 0.693147
particular focus 0.693147
physiologic processes 0.693147
tissue homeostasis 0.693147
cancer development 0.693147
dtype: float64
""" หากคุณต้องการเพิ่มสิ่งนี้ลงในไปป์ไลน์ Spacy เพียงใช้วิธีเพิ่ม add_pipe ของ Spacy
import spacy
from pyate . term_extraction_pipeline import TermExtractionPipeline
nlp = spacy . load ( "en_core_web_sm" )
nlp . add_pipe ( "combo_basic" )
doc = nlp ( string )
print ( doc . _ . combo_basic . sort_values ( ascending = False ). head ( 5 ))
""" (Output)
dysfunctional tumor 1.443147
tumor suppressors 1.443147
genetic changes 1.386294
cancer cells 1.386294
dysfunctional tumor suppressors 1.298612
dtype: float64
""" นอกจากนี้ TermExtractionPipeline.__init__ ถูกกำหนดดังนี้
__init__(
self,
func: Callable[..., pd.Series] = combo_basic,
*args,
**kwargs
)
โดยที่ func เป็นคำศัพท์ของคุณในการแยกอัลกอริทึมที่ใช้ในคลังข้อมูล (ไม่ว่าจะเป็นสตริงหรือตัววนซ้ำของสตริง) และส่งออกชุดแพนด้าของคำศัพท์คำศัพท์และคำศัพท์ที่เกี่ยวข้อง func เป็นค่าเริ่มต้น combo_basic args และ kwargs ช่วยให้คุณสามารถเอาชนะค่าเริ่มต้นสำหรับฟังก์ชั่นซึ่งคุณสามารถค้นหาได้โดยการเรียกใช้ help ใช้ (อาจจัดทำเอกสารในภายหลัง)
cvalues, basic, combo_basic, weirdness และ term_extractor ใช้เวลาในสตริงหรือตัววนซ้ำของสตริงและเอาต์พุตชุดแพนด้าของคู่ค่าคำศัพท์ที่ค่าที่สูงกว่าบ่งบอกถึงโอกาสที่สูงขึ้นของการเป็นคำเฉพาะของโดเมน นอกจากนี้ weirdness และ term_extractor ใช้อาร์กิวเมนต์คำสำคัญ general_corpus ซึ่งจะต้องเป็นตัววนซ้ำของสตริงซึ่งเริ่มต้นไปยังคลังข้อมูลทั่วไปที่อธิบายไว้ด้านล่าง
ฟังก์ชั่นทั้งหมดใช้เฉพาะสตริงที่คุณต้องการแยกคำศัพท์ออกจากการป้อนข้อมูลที่จำเป็น threshold technical_corpus ) รวมถึงการตั้งค่าอื่น ๆ ที่สามารถปรับแต่งได้รวมถึง general_corpus ( weights ที่ตัดกันสำหรับ weirdness และ term_extractor ), general_corpus_size , verbose have_single_word smoothing - หากคุณยังไม่ได้อ่านเอกสารและไม่คุ้นเคยกับอัลกอริทึมฉันขอแนะนำให้ใช้การตั้งค่าเริ่มต้น ใช้ help อีกครั้งเพื่อค้นหารายละเอียดเกี่ยวกับอัลกอริทึมแต่ละตัวเนื่องจากพวกเขาต่างกันทั้งหมด
ภายใต้ path/to/site-packages/pyate/default_general_domain.en.zip มีไฟล์ CSV ทั่วไปของคลังข้อมูลทั่วไปโดยเฉพาะประโยคสุ่ม 3000 ประโยคจาก Wikipedia แหล่งที่มาของมันสามารถพบได้ที่ https://www.kaggle.com/mikeortman/wikipedia-sentences เข้าถึงโดยใช้มันโดยใช้สิ่งต่อไปนี้หลังจากติดตั้ง pyate
import pandas as pd
from distutils . sysconfig import get_python_lib
df = pd . read_csv ( get_python_lib () + "/pyate/default_general_domain.en.zip" )[ "SECTION_TEXT" ]
print ( df . head ())
""" (Output)
0 '''Anarchism''' is a political philosophy that...
1 The term ''anarchism'' is a compound word comp...
2 ===Origins=== n Woodcut from a Diggers document...
3 Portrait of philosopher Pierre-Joseph Proudhon...
4 consistent with anarchist values is a controve...
Name: SECTION_TEXT, dtype: object
""" สำหรับการสลับภาษาเพียงเรียกใช้ Term_Extraction.set_language({language}, {model_name}) โดยที่ model_name เริ่มต้นเป็น language ตัวอย่างเช่น Term_Extraction.set_language("it", "it_core_news_sm"}) สำหรับอิตาลี โดยค่าเริ่มต้นภาษาเป็นภาษาอังกฤษ จนถึงตอนนี้รายการภาษาที่รองรับคือ:
หากต้องการเพิ่มภาษาเพิ่มเติมให้ยื่นปัญหาด้วยคลังข้อมูลอย่างน้อย 3,000 วรรคของโดเมนทั่วไปในภาษาที่ต้องการ (ควรวิกิพีเดีย) ชื่อ default_general_domain.{lang}.zip แทนที่ lang ด้วยรหัส ISO-639-1 https://www.loc.gov/standards/iso639-2/php/code_list.php) รูปแบบไฟล์ควรเป็นแบบฟอร์มต่อไปนี้ที่สามารถแยกได้โดยแพนด้า
,SECTION_TEXT
0,"{paragraph_0}"
1,"{paragraph_1}"
...
อีกวิธีหนึ่งคือวางไฟล์ใน src/pyate และยื่นคำขอดึง
คำเตือน: โมเดลใช้งานได้กับ Spacy v2 เท่านั้น
แม้ว่าแบบจำลองนี้มีไว้สำหรับอัลกอริทึม AI สัญลักษณ์ (ไม่ใช่การเรียนรู้ที่ไม่ใช่เครื่องจักร) แต่ฉันก็ตระหนักถึงรูปแบบการขับขี่ในการสกัดคำสามารถเข้าถึงประสิทธิภาพที่สูงขึ้นอย่างมีนัยสำคัญและตัดสินใจที่จะรวมโมเดลที่นี่
สำหรับการเปรียบเทียบกับอัลกอริทึม AI สัญลักษณ์ดูความแม่นยำ โปรดทราบว่ามีเพียงคะแนน F ความแม่นยำและความแม่นยำเท่านั้นที่ใช้ที่นี่สำหรับแบบจำลอง แต่สำหรับอัลกอริทึม AVP จึงถูกนำมาเปรียบเทียบโดยตรงดังนั้นการวัดตัวชี้วัดจะไม่สมเหตุสมผล
| url | คะแนน F (%) | ความแม่นยำ (%) | เรียกคืน (%) |
|---|---|---|---|
| https://github.com/kevinlu1248/pyate/releases/download/v0.4.2/en_acl_terms_sm-2.0.4.tar.gz | 94.71 | 95.41 | 94.03 |
แบบจำลองได้รับการฝึกอบรมและประเมินผลในชุดข้อมูล ACL ซึ่งเป็นชุดข้อมูลเชิงวิทยาศาสตร์คอมพิวเตอร์ที่มีการเลือกคำศัพท์ด้วยตนเอง อย่างไรก็ตามสิ่งนี้ยังไม่ได้รับการทดสอบในสาขาอื่น ๆ
รุ่นนี้ไม่ได้มาพร้อมกับ Pyate ในการติดตั้ง Run
pip install https://github.com/kevinlu1248/pyate/releases/download/v0.4.2/en_acl_terms_sm-2.0.4.tar.gzเพื่อแยกคำศัพท์
import spacy
nlp = spacy . load ( "en_acl_terms_sm" )
doc = nlp ( "Hello world, I am a term extraction algorithm." )
print ( doc . ents )
"""
(term extraction, algorithm)
""" นี่คือความแม่นยำเฉลี่ยของอัลกอริทึมที่นำไปใช้บางส่วนโดยใช้ตัวชี้วัดความแม่นยำเฉลี่ย (AVP) ในฐานข้อมูลเจ็ดฐานที่แตกต่างกันซึ่งทดสอบใน Astrakhantsev 2016 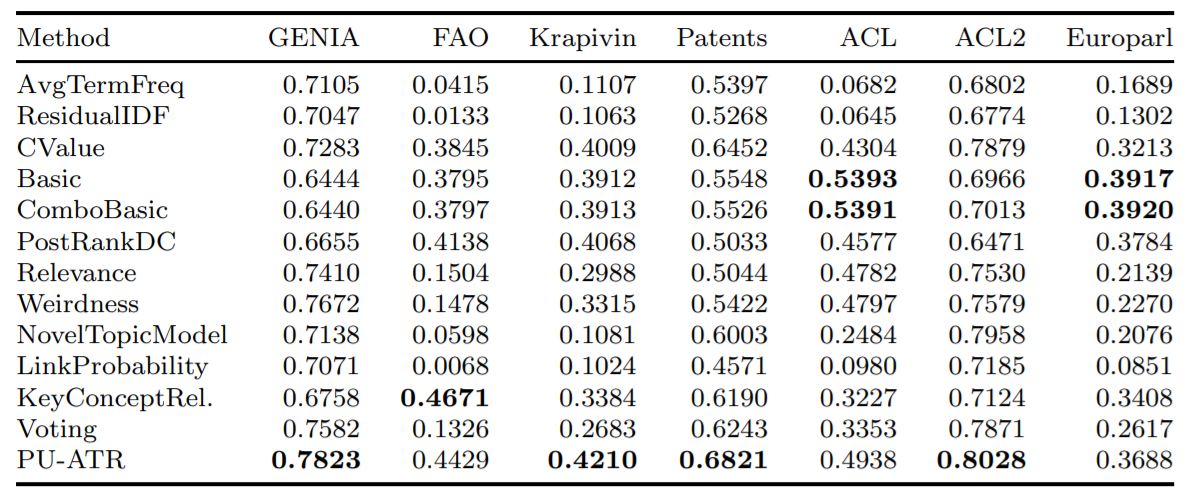
โครงการนี้ได้รับการวางแผนว่าจะเป็นเครื่องมือที่จะเชื่อมต่อกับส่วนขยายของ Google Chrome ที่เน้นและกำหนดคำสำคัญที่ผู้อ่านอาจไม่ทราบ นอกจากนี้การสกัดระยะเป็นพื้นที่ที่มีการวิจัยที่มุ่งเน้นไม่มากเมื่อเทียบกับพื้นที่อื่น ๆ ของ NLP และโดยเฉพาะอย่างยิ่งเมื่อเร็ว ๆ นี้ไม่ได้ถูกมองว่าเป็นประโยชน์มากเนื่องจากเครื่องมือทั่วไปของการติดแท็ก NER มากขึ้น อย่างไรก็ตามการติดแท็ก NER ที่ทันสมัยมักจะรวมการผสมผสานของคำที่จดจำและการเรียนรู้อย่างลึกซึ้งซึ่งหนักและคำนวณได้อย่างหนัก นอกจากนี้เพื่อสรุปอัลกอริทึมเพื่อรับรู้คำศัพท์เกี่ยวกับการวิจัยด้านการแพทย์และ AI ที่เพิ่มขึ้นเรื่อย ๆ รายการคำที่จดจำจะไม่ทำ
จากอัลกอริทึมที่ใช้งานห้าตัวไม่มีราคาแพงในความเป็นจริงคอขวดของการจัดสรรพื้นที่และค่าใช้จ่ายในการคำนวณมาจากโมเดล Spacy และการติดแท็ก POS Spacy นี่เป็นเพราะพวกเขาส่วนใหญ่พึ่งพารูปแบบ POS ความถี่คำและการมีอยู่ของผู้สมัครภาคฝังตัว ตัวอย่างเช่นคำว่า "มะเร็งเต้านม" หมายถึง "มะเร็งเต้านมมะเร็ง" อาจไม่ใช่คำและเป็นเพียงรูปแบบของ "มะเร็งเต้านม" ที่เป็น "มะเร็ง" (นำไปใช้ในค่า C)
ฉันไม่สามารถหาเอกสารพื้นฐานพื้นฐานและคอมโบดั้งเดิมได้ แต่ฉันพบเอกสารที่อ้างอิงพวกเขา "ATR4S: ชุดเครื่องมือที่มีวิธีการจดจำคำศัพท์อัตโนมัติที่ล้ำสมัยใน Scala" สรุปทุกอย่างมากหรือน้อยและรวมอัลกอริทึมหลายอย่างที่ไม่ได้อยู่ในแพ็คเกจนี้
หากคุณเผยแพร่งานที่ใช้ Pyate โปรดแจ้งให้เราทราบที่ [email protected] และอ้างอิงเป็น:
Lu, Kevin. (2021, June 28). kevinlu1248/pyate: Python Automated Term Extraction (Version v0.5.3). Zenodo. http://doi.org/10.5281/zenodo.5039289
หรือเทียบเท่ากับ bibtext:
@software{pyate,
title = {kevinlu1248/pyate: Python Automated Term Extraction},
author = {Lu, Kevin},
year = 2021,
month = {Jun},
publisher = {Zenodo},
doi = {10.5281/zenodo.5039289}
}
แพ็คเกจนี้ใช้ในกระดาษ (การสกัดคำศัพท์โดเมนทางเทคนิคที่ไม่ได้รับการดูแลโดยใช้คำสกัด (Dowlagar และ Mamidi, 2021)
หากงานของฉันช่วยคุณโปรดลองซื้อกาแฟให้ฉันที่ https://www.buymeacoffee.com/kevinlu1248


