pyate
Initial Release for Zenodo
Python Implémentation d'algorithmes d'extraction à terme tels que la valeur C, la base, le combo Basic, l'étrangeté et l'extracteur de terme à l'aide du balisage SPACY POS.
Nouveau: la documentation peut être trouvée sur https://kevinlu1248.github.io/pyate/. Jusqu'à présent, la documentation manque encore deux algorithmes et des détails sur la classe TermExtraction , mais je le ferai bientôt.
NOUVEAU: Essayez les algorithmes sur https://pyate-demo.herokuapp.com/, une application Web pour la démonstration de Pyate!
Nouveau: Spacy V3 est pris en charge! Pour Spacy V2, utilisez pyate==0.4.3 et affichez le fichier Spacy V2 Readme.md
Si vous avez une suggestion pour un autre algorithme ATE que vous souhaitez implémenter dans ce package, n'hésitez pas à le déposer comme un problème avec le document sur lequel l'algorithme est basé.
Pour les packages ATE mis en œuvre dans Scala et Java, voir ATR4S et Jate, respectivement.
Utilisation de PIP:
pip install pyate
spacy download en_core_web_sm Pour commencer, appelez simplement l'un des algorithmes implémentés. Selon Astrakhantsev 2016, combo_basic est le plus précis des cinq algorithmes, bien que basic et cvalues ne soient pas trop loin derrière (voir précision). La même étude montre que PU-ATR et KeyConceptrel ont une précision plus élevée que combo_basic mais ne sont pas mis en œuvre et PU-ATr prennent beaucoup plus de temps car il utilise l'apprentissage automatique.
from pyate import combo_basic
# source: https://www.ncbi.nlm.nih.gov/pmc/articles/PMC1994795/
string = """Central to the development of cancer are genetic changes that endow these “cancer cells” with many of the
hallmarks of cancer, such as self-sufficient growth and resistance to anti-growth and pro-death signals. However, while the
genetic changes that occur within cancer cells themselves, such as activated oncogenes or dysfunctional tumor suppressors,
are responsible for many aspects of cancer development, they are not sufficient. Tumor promotion and progression are
dependent on ancillary processes provided by cells of the tumor environment but that are not necessarily cancerous
themselves. Inflammation has long been associated with the development of cancer. This review will discuss the reflexive
relationship between cancer and inflammation with particular focus on how considering the role of inflammation in physiologic
processes such as the maintenance of tissue homeostasis and repair may provide a logical framework for understanding the U
connection between the inflammatory response and cancer."""
print ( combo_basic ( string ). sort_values ( ascending = False ))
""" (Output)
dysfunctional tumor 1.443147
tumor suppressors 1.443147
genetic changes 1.386294
cancer cells 1.386294
dysfunctional tumor suppressors 1.298612
logical framework 0.693147
sufficient growth 0.693147
death signals 0.693147
many aspects 0.693147
inflammatory response 0.693147
tumor promotion 0.693147
ancillary processes 0.693147
tumor environment 0.693147
reflexive relationship 0.693147
particular focus 0.693147
physiologic processes 0.693147
tissue homeostasis 0.693147
cancer development 0.693147
dtype: float64
""" Si vous souhaitez l'ajouter à un pipeline Spacy, utilisez simplement la méthode add_pipe ajout.
import spacy
from pyate . term_extraction_pipeline import TermExtractionPipeline
nlp = spacy . load ( "en_core_web_sm" )
nlp . add_pipe ( "combo_basic" )
doc = nlp ( string )
print ( doc . _ . combo_basic . sort_values ( ascending = False ). head ( 5 ))
""" (Output)
dysfunctional tumor 1.443147
tumor suppressors 1.443147
genetic changes 1.386294
cancer cells 1.386294
dysfunctional tumor suppressors 1.298612
dtype: float64
""" Aussi, TermExtractionPipeline.__init__ est défini comme suit
__init__(
self,
func: Callable[..., pd.Series] = combo_basic,
*args,
**kwargs
)
où func est essentiellement votre algorithme d'extraction à terme qui prend un corpus (soit une chaîne ou un itérateur de cordes) et émet une série Pandas de paires de termes de valeur à terme et leurs termes respectifs. func est par défaut combo_basic . args et kwargs sont pour vous de suredente les valeurs par défaut pour la fonction, que vous pouvez trouver en exécutant help (pourrait documenter plus tard).
Chacun des cvalues, basic, combo_basic, weirdness et term_extractor adopte une chaîne ou un itérateur de chaînes et publie une série pandas de paires de valeurs de terme, où des valeurs plus élevées indiquent un risque plus élevé d'être un terme spécifique au domaine. De plus, weirdness et term_extractor prennent un argument de mot clé general_corpus qui doit être un itérateur de chaînes qui par fait par défaut le corpus général décrit ci-dessous.
Toutes les fonctions ne prennent que la chaîne dont vous souhaitez extraire les termes comme l'entrée obligatoire (le technical_corpus ), ainsi que d'autres paramètres de réglage, y compris general_corpus , verbose (que ce soit pour imprimer un billet weirdness term_extractor ), weights general_corpus_size have_single_word smoothing , un threshold . Si vous n'avez pas lu les articles et que vous ne connaissez pas les algorithmes, je recommande simplement d'utiliser les paramètres par défaut. Encore une fois, utilisez help pour trouver les détails concernant chaque algorithme car ils sont tous différents.
Sous path/to/site-packages/pyate/default_general_domain.en.zip , il existe un fichier CSV général d'un corpus général, en particulier, 3000 phrases aléatoires de Wikipedia. La source de celui-ci peut être trouvée sur https://www.kaggle.com/mikeortman/wikipedia-sentences. Accédez à lui en utilisant les éléments suivants après l'installation pyate .
import pandas as pd
from distutils . sysconfig import get_python_lib
df = pd . read_csv ( get_python_lib () + "/pyate/default_general_domain.en.zip" )[ "SECTION_TEXT" ]
print ( df . head ())
""" (Output)
0 '''Anarchism''' is a political philosophy that...
1 The term ''anarchism'' is a compound word comp...
2 ===Origins=== n Woodcut from a Diggers document...
3 Portrait of philosopher Pierre-Joseph Proudhon...
4 consistent with anarchist values is a controve...
Name: SECTION_TEXT, dtype: object
""" Pour changer de langage, exécutez simplement Term_Extraction.set_language({language}, {model_name}) , où model_name est par défaut en language . Par exemple, Term_Extraction.set_language("it", "it_core_news_sm"}) pour l'italien. Par défaut, la langue est l'anglais. Jusqu'à présent, la liste des langues prises en charge est:
Pour ajouter plus de langues, déposez un problème avec un corpus d'au moins 3000 paragraphes d'un domaine général dans la langue souhaitée (de préférence wikipedia) nommé default_general_domain.{lang}.zip Remplaçant Lang par le code ISO-639-1 de la langue, ou l'iso-639-2 https://www.loc.gov/standards/iso639-2/php/code_list.php). Le format de fichier doit être du formulaire suivant pour être analysé par Pandas.
,SECTION_TEXT
0,"{paragraph_0}"
1,"{paragraph_1}"
...
Alternativement, placez le fichier dans src/pyate et fichier une demande de traction.
AVERTISSEMENT: Le modèle ne fonctionne qu'avec Spacy V2.
Bien que ce modèle ait été initialement destiné aux algorithmes d'IA symboliques (apprentissage non-machine), j'ai réalisé qu'un modèle spacy sur l'extraction des termes peut atteindre des performances beaucoup plus élevées, et j'ai donc décidé d'inclure le modèle ici.
Pour une comparaison avec les algorithmes d'IA symboliques, voir la précision. Notez que seuls le score F, la précision et la précision ont été pris ici pour le modèle, mais pour les algorithmes, l'AVP a été pris si directement en comparant les mesures n'aurait pas vraiment de sens.
| URL | F-Score (%) | Précision (%) | Rappel (%) |
|---|---|---|---|
| https://github.com/kevinlu1248/pyate/releases/download/v0.4.2/en_acl_terms_sm-2.0.4.tar.gz | 94.71 | 95.41 | 94.03 |
Le modèle a été formé et évalué sur l'ensemble de données ACL, qui est un ensemble de données axé sur l'informatique où les termes sont choisis manuellement. Cependant, cela n'a pas encore été testé sur d'autres domaines.
Ce modèle ne vient pas avec le pyate. Pour installer, exécuter
pip install https://github.com/kevinlu1248/pyate/releases/download/v0.4.2/en_acl_terms_sm-2.0.4.tar.gzPour extraire les termes,
import spacy
nlp = spacy . load ( "en_acl_terms_sm" )
doc = nlp ( "Hello world, I am a term extraction algorithm." )
print ( doc . ents )
"""
(term extraction, algorithm)
""" Voici la précision moyenne de certains des algorithmes mis en œuvre en utilisant la métrique de précision moyenne (AVP) sur sept bases de données distinctes, tels que testés dans Astrakhantsev 2016.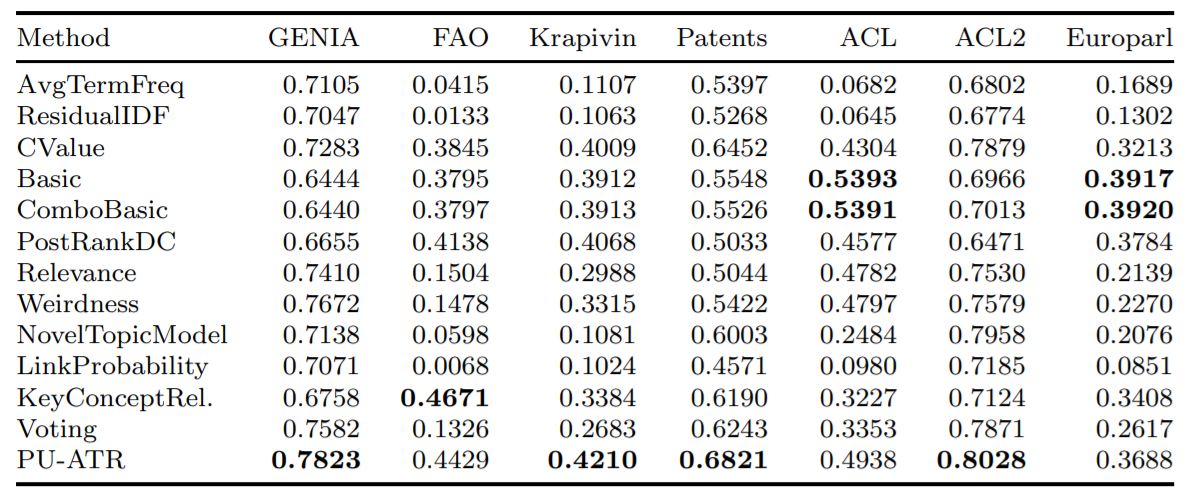
Ce projet devait être un outil pour être connecté à une extension Google Chrome qui met en évidence et définit les termes clés que le lecteur ne connaît probablement pas. De plus, l'extraction à terme est un domaine où il n'y a pas beaucoup de recherches ciblées par rapport à d'autres domaines de la PNL et surtout récemment ne sont pas considérés comme très pratiques en raison de l'outil plus général du marquage NER. Cependant, le marquage NER moderne intègre généralement une combinaison de mots mémorisés et d'apprentissage en profondeur qui sont spatialement et de calcul. En outre, pour généraliser un algorithme pour reconnaître les termes dans les domaines en constante croissance de la recherche médicale et de l'IA, une liste de mots mémorisés ne fera pas l'affaire.
Sur les cinq algorithmes mis en œuvre, aucun n'est coûteux, en fait, le goulot d'étranglement de la répartition des espaces et des dépenses de calcul provient du modèle Spacy et du marquage de POS Spacy. En effet, ils reposent principalement simplement sur les modèles POS, les fréquences de mots et l'existence de candidats à terme intégrés. Par exemple, le terme candidat "cancer du sein" implique que le "cancer du sein malin" n'est probablement pas un terme et simplement une forme de "cancer du sein" qui est "malin" (mis en œuvre en valeur C).
Je n'arrive pas à trouver les articles de base de base et combo originaux, mais j'ai trouvé des articles qui les faisaient référence. "ATR4S: Toolkit avec des méthodes de reconnaissance de termes automatiques de pointe à Scala" résume plus ou moins tout et incorpore plusieurs algorithmes qui ne sont pas dans ce package.
Si vous publiez un travail qui utilise Pyate, veuillez me le faire savoir à [email protected] et citer comme:
Lu, Kevin. (2021, June 28). kevinlu1248/pyate: Python Automated Term Extraction (Version v0.5.3). Zenodo. http://doi.org/10.5281/zenodo.5039289
ou de manière équivalente avec BibText:
@software{pyate,
title = {kevinlu1248/pyate: Python Automated Term Extraction},
author = {Lu, Kevin},
year = 2021,
month = {Jun},
publisher = {Zenodo},
doi = {10.5281/zenodo.5039289}
}
Cet ensemble a été utilisé dans l'article (extraction des termes de domaine technique non supervisé à l'aide de l'extracteur à terme (Dowlagar et Mamidi, 2021).
Si mon travail vous a aidé, veuillez envisager de m'acheter un café sur https://www.buymeacoffee.com/kevinlu1248.


