TinyLLaVA_Factory
1.0.0
我們的最佳型號Tinyllava-Phi-2-Siglip-3.1b在現有的7B型號(例如Llava-1.5和Qwen-vl)中取得了更好的總體性能。
Tinyllava Factory是用於小型大型多模型(LMM)的開源模塊化代碼庫,該模型(LMMS)以Pytorch和HuggingFace實現,重點是簡單的代碼實現,新功能的可擴展性以及可重複性的訓練結果。
借助Tinyllava工廠,您可以自定義自己的大型多模式,並以更少的編碼工作和更少的編碼錯誤來定制。
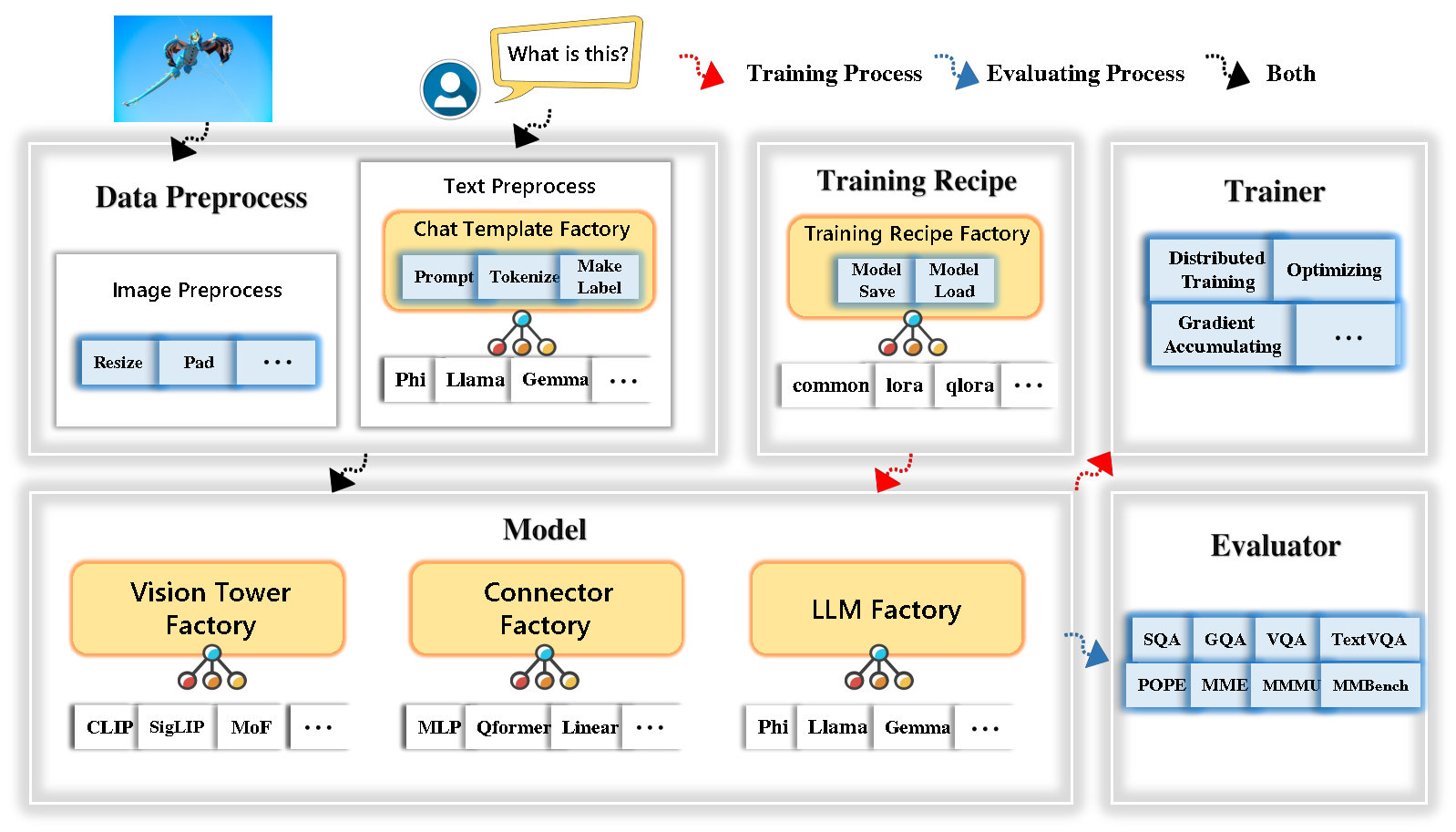
Tinyllava工廠集成了一套尖端的模型和方法。
LLM目前支持Openelm , Tinyllama , Stablelm , Qwen , Gemma和Phi 。
目前,視覺塔支持夾子, siglip , dino和夾子和恐龍的組合。
連接器當前支持MLP , QFormer和Res採樣器。
培訓食譜目前支持冷凍/完全/部分調整和Lora/Qlora調整。
請注意,我們的環境要求與LLAVA的環境要求不同。我們強烈建議您從頭開始創建環境。
git clone https://github.com/TinyLLaVA/TinyLLaVA_Factory.git
cd TinyLLaVA_Factoryconda create -n tinyllava_factory python=3.10 -y
conda activate tinyllava_factory
pip install --upgrade pip # enable PEP 660 support
pip install -e .pip install flash-attn --no-build-isolationgit pull
pip install -e . 請參閱我們的文檔中的數據準備部分。
這是使用PHI-2訓練LMM的示例。
scripts/train/train_phi.sh替換數據路徑scripts/train/pretrain.sh中替換您的output_dirscripts/train/finetune.sh中替換pretrained_model_path和output_dirper_device_train_batch_size in scripts/train/pretrain.sh和scripts/train/finetune.sh bash scripts/train/train_phi.sh下面提供了用於預訓練和填充的重要超參數。
| 訓練階段 | 全局批處理大小 | 學習率 | conv_version |
|---|---|---|---|
| 預處理 | 256 | 1E-3 | 預認證 |
| 微調 | 128 | 2E-5 | 皮 |
尖端:
全局批處理大小= gpus * per_device_train_batch_size * gradient_accumulation_steps ,我們建議您始終保持全局批次大小和學習率,除了lora調整模型外。
conv_version是用於選擇不同LLM的不同聊天模板的超參數。在預訓練階段,使用pretrain的所有LLM都conv_version 。在填補階段,我們使用
PHI-2,StableLM,QWEN-1.5的phi
Tinyllama的llama ,Openelm
Gemma的gemma
請參閱我們的文檔評估部分。
使用Tinyllava工廠訓練。
| VT(HF路徑) | LLM(HF路徑) | 食譜 | VQA-V2 | GQA | SQA圖像 | textvqa | MM-VET | 教皇 | 媽媽 | mmmu-val |
|---|---|---|---|---|---|---|---|---|---|---|
| Openai/clip-vit-large-patch14-336 | Apple/OpenElm-450m-Instruct | 根據 | 69.5 | 52.1 | 50.6 | 40.4 | 20.0 | 83.6 | 1052.9 | 23.9 |
| Google/siglip-SO400M-Patch14-384 | Apple/OpenElm-450m-Instruct | 根據 | 71.7 | 53.9 | 54.1 | 44.0 | 20.0 | 85.4 | 1118.8 | 24.0 |
| Google/siglip-SO400M-Patch14-384 | QWEN/QWEN2-0.5B | 根據 | 72.3 | 55.8 | 60.1 | 45.2 | 19.5 | 86.6 | 1153.0 | 29.7 |
| Google/siglip-SO400M-Patch14-384 | qwen/qwen2.5-0.5b | 根據 | 75.3 | 59.5 | 60.3 | 48.3 | 23.9 | 86.1 | 1253.0 | 33.3 |
| Google/siglip-SO400M-Patch14-384 | QWEN/QWEN2.5-3B | 根據 | 79.4 | 62.5 | 74.1 | 58.3 | 34.8 | 87.4 | 1438.7 | 39.9 |
| Openai/clip-vit-large-patch14-336 | tinyllama/tinyllama-1.1b-chat-v1.0 | 根據 | 73.7 | 58.0 | 59.9 | 46.3 | 23.2 | 85.5 | 1284.6 | 27.9 |
| Google/siglip-SO400M-Patch14-384 | tinyllama/tinyllama-1.1b-chat-v1.0 | 根據 | 75.5 | 58.6 | 64.0 | 49.6 | 23.5 | 86.3 | 1256.5 | 28.3 |
| Openai/clip-vit-large-patch14-336 | StematieAi/stablelm-2-Zephyr-1_6b | 根據 | 75.9 | 59.5 | 64.6 | 50.5 | 27.3 | 86.1 | 1368.1 | 31.8 |
| Google/siglip-SO400M-Patch14-384 | StematieAi/stablelm-2-Zephyr-1_6b | 根據 | 78.2 | 60.7 | 66.7 | 56.0 | 29.4 | 86.3 | 1319.3 | 32.6 |
| Google/siglip-SO400M-Patch14-384 | Google/gemma-2b-it | 根據 | 78.4 | 61.6 | 64.4 | 53.6 | 26.9 | 86.4 | 1339.0 | 31.7 |
| Openai/clip-vit-large-patch14-336 | Microsoft/phi-2 | 根據 | 76.8 | 59.4 | 71.2 | 53.4 | 31.7 | 86.8 | 1448.6 | 36.3 |
| Google/siglip-SO400M-Patch14-384 | Microsoft/phi-2 | 根據 | 79.2 | 61.6 | 71.9 | 57.4 | 35.0 | 87.2 | 1462.4 | 38.2 |
| Google/siglip-SO400M-Patch14-384 | Microsoft/phi-2 | 基地和洛拉 | 77.6 | 59.7 | 71.6 | 53.8 | 33.3 | 87.9 | 1413.2 | 35.6 |
| Google/siglip-SO400M-Patch14-384 | Microsoft/phi-2 | 分享 | 80.1 | 62.1 | 73.0 | 60.3 | 37.5 | 87.2 | 1466.4 | 38.4 |
使用舊代碼庫Tinyllavabench進行了訓練。
如果您的模型由我們的舊代碼庫Tinyllavabench培訓,並且仍然想使用它們,我們將提供有關如何使用舊模型的Tinyllava-3.1b的示例。
from tinyllava . eval . run_tiny_llava import eval_model
from tinyllava . model . convert_legecy_weights_to_tinyllavafactory import *
model = convert_legecy_weights_to_tinyllavafactory ( 'bczhou/TinyLLaVA-3.1B' )
prompt = "What are the things I should be cautious about when I visit here?"
image_file = "https://llava-vl.github.io/static/images/view.jpg"
args = type ( 'Args' , (), {
"model_path" : None ,
"model" : model ,
"query" : prompt ,
"conv_mode" : "phi" , # the same as conv_version in the training stage. Different LLMs have different conv_mode/conv_version, please replace it
"image_file" : image_file ,
"sep" : "," ,
"temperature" : 0 ,
"top_p" : None ,
"num_beams" : 1 ,
"max_new_tokens" : 512
})()
eval_model ( args )
"""
Output:
When visiting this serene lakeside location with a wooden dock, there are a few things to be cautious about. First, ensure that the dock is stable and secure before stepping onto it, as it might be slippery or wet, especially if it's a wooden structure. Second, be mindful of the surrounding water, as it can be deep or have hidden obstacles, such as rocks or debris, that could pose a risk. Additionally, be aware of the weather conditions, as sudden changes in weather can make the area more dangerous. Lastly, respect the natural environment and wildlife, and avoid littering or disturbing the ecosystem.
""" 通過運行啟動本地Web演示:
python tinyllava/serve/app.py --model-path tinyllava/TinyLLaVA-Phi-2-SigLIP-3.1B我們還支持使用CLI運行推斷。要使用我們的模型,請運行:
python -m tinyllava.serve.cli
--model-path tinyllava/TinyLLaVA-Phi-2-SigLIP-3.1B
--image-file " ./tinyllava/serve/examples/extreme_ironing.jpg " 如果您想在本地啟動由您自己或我們培訓的模型,則是一個例子。
from tinyllava . eval . run_tiny_llava import eval_model
model_path = "/absolute/path/to/your/model/"
prompt = "What are the things I should be cautious about when I visit here?"
image_file = "https://llava-vl.github.io/static/images/view.jpg"
conv_mode = "phi" # or llama, gemma, etc
args = type ( 'Args' , (), {
"model_path" : model_path ,
"model" : None ,
"query" : prompt ,
"conv_mode" : conv_mode ,
"image_file" : image_file ,
"sep" : "," ,
"temperature" : 0 ,
"top_p" : None ,
"num_beams" : 1 ,
"max_new_tokens" : 512
})()
eval_model ( args )
"""
Output:
XXXXXXXXXXXXXXXXX
""" from transformers import AutoTokenizer , AutoModelForCausalLM
hf_path = 'tinyllava/TinyLLaVA-Phi-2-SigLIP-3.1B'
model = AutoModelForCausalLM . from_pretrained ( hf_path , trust_remote_code = True )
model . cuda ()
config = model . config
tokenizer = AutoTokenizer . from_pretrained ( hf_path , use_fast = False , model_max_length = config . tokenizer_model_max_length , padding_side = config . tokenizer_padding_side )
prompt = "What are these?"
image_url = "http://images.cocodataset.org/val2017/000000039769.jpg"
output_text , genertaion_time = model . chat ( prompt = prompt , image = image_url , tokenizer = tokenizer )
print ( 'model output:' , output_text )
print ( 'runing time:' , genertaion_time )如果您想使用自定義數據集使用Finetune Tinyllava,請參考此處。
如果您想自己添加新的LLM,則需要創建兩個文件:一個用於聊天模板,另一個用於語言模型,在文件夾tinyllava/data/template/和tinyllava/model/llm/下。
這是添加Gemma模型的示例。
首先,創建tinyllava/data/template/gemma_template.py ,將用於填充階段。
from dataclasses import dataclass
from typing import TYPE_CHECKING , Dict , List , Optional , Sequence , Tuple , Union
from packaging import version
from . formatter import EmptyFormatter , StringFormatter
from . base import Template
from . formatter import Formatter
from . import register_template
from ... utils . constants import *
from transformers import PreTrainedTokenizer
import torch
import tokenizers
system = "A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user's questions."
@ register_template ( 'gemma' ) # Enable the TemplateFactory to obtain the added template by this string ('gemma').
@ dataclass
class GemmaTemplate ( Template ):
format_image_token : "Formatter" = StringFormatter ( slot = "<image> n {{content}}" )
format_user : "Formatter" = StringFormatter ( slot = "USER" + ": " + "{{content}}" + " " )
format_assistant : "Formatter" = StringFormatter ( slot = "ASSISTANT" + ": " + "{{content}}" + "<eos>" ) # to be modified according to the tokenizer you choose
system : "Formatter" = EmptyFormatter ( slot = system + " " )
separator : "Formatter" = EmptyFormatter ( slot = [ ' ASSISTANT: ' , '<eos>' ]) # to be modified according to the tokenizer you choose
def _make_masks ( self , labels , tokenizer , sep , eos_token_length , rounds ):
# your code here
return labels , cur_len尖端:
請確保labels (由_make_masks函數返回)遵循此格式:答案和EOS令牌ID不會掩蓋,而其他令牌則被-100掩蓋。
其次,創建tinyllava/model/llm/gemma.py 。
from transformers import GemmaForCausalLM , AutoTokenizer
# The LLM you want to add along with its corresponding tokenizer.
from . import register_llm
# Add GemmaForCausalLM along with its corresponding tokenizer and handle special tokens.
@ register_llm ( 'gemma' ) # Enable the LLMFactory to obtain the added LLM by this string ('gemma').
def return_gemmaclass ():
def tokenizer_and_post_load ( tokenizer ):
tokenizer . pad_token = tokenizer . unk_token
return tokenizer
return ( GemmaForCausalLM , ( AutoTokenizer , tokenizer_and_post_load ))最後,使用相應的LLM_VERSION和CONV_VERSION創建scripts/train/train_gemma.sh 。
如果您想添加一個新的視覺塔,則需要實現應從基類VisionTower繼承的New Vision Tower類。這是MOF Vision Tower的一個例子。
首先,創建tinyllava/model/vision_tower/mof.py
@ register_vision_tower ( 'mof' )
class MoFVisionTower ( VisionTower ):
def __init__ ( self , cfg ):
super (). __init__ ( cfg )
self . _vision_tower = MoF ( cfg )
self . _image_processor = # your image processor
def _load_model ( self , vision_tower_name , ** kwargs ):
# your code here, make sure your model can be correctly loaded from pretrained parameters either by huggingface or pytorch loading
def forward ( self , x , ** kwargs ):
# your code here然後,使用相應的VT_VERSION修改培訓腳本。
如果要添加新連接器,則需要實現應從基類Connector繼承的新連接器類。這是線性連接器的示例。
首先,創建tinyllava/model/connector/linear.py
import torch . nn as nn
from . import register_connector
from . base import Connector
@ register_connector ( 'linear' ) #Enable the ConnectorMFactory to obtain the added connector by this string ('linear').
class LinearConnector ( Connector ):
def __init__ ( self , config ):
super (). __init__ ()
self . _connector = nn . Linear ( config . vision_hidden_size , config . hidden_size ) # define your connector model然後,使用相應的CN_VERSION修改培訓腳本。
我們特別感謝Lei Zhao,Luche Wang,Kaijun Luo和Junchen Wang建造演示。
如果您有任何疑問,請隨時發起問題或與我們聯繫(Wechatid: Tinyllava )。
如果您發現我們的論文和代碼對您的研究有用,請考慮給出明星和引用。
@misc { zhou2024tinyllava ,
title = { TinyLLaVA: A Framework of Small-scale Large Multimodal Models } ,
author = { Baichuan Zhou and Ying Hu and Xi Weng and Junlong Jia and Jie Luo and Xien Liu and Ji Wu and Lei Huang } ,
year = { 2024 } ,
eprint = { 2402.14289 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.LG }
} @article { jia2024tinyllava ,
title = { TinyLLaVA Factory: A Modularized Codebase for Small-scale Large Multimodal Models } ,
author = { Jia, Junlong and Hu, Ying and Weng, Xi and Shi, Yiming and Li, Miao and Zhang, Xingjian and Zhou, Baichuan and Liu, Ziyu and Luo, Jie and Huang, Lei and Wu, Ji } ,
journal = { arXiv preprint arXiv:2405.11788 } ,
year = { 2024 }
}

