TinyLLaVA_Factory
1.0.0
โมเดลที่ดีที่สุดของเรา Tinyllava-Phi-2-Siglip-3.1b บรรลุประสิทธิภาพโดยรวมที่ดีขึ้นกับรุ่น 7B ที่มีอยู่เช่น LLAVA-1.5 และ Qwen-VL
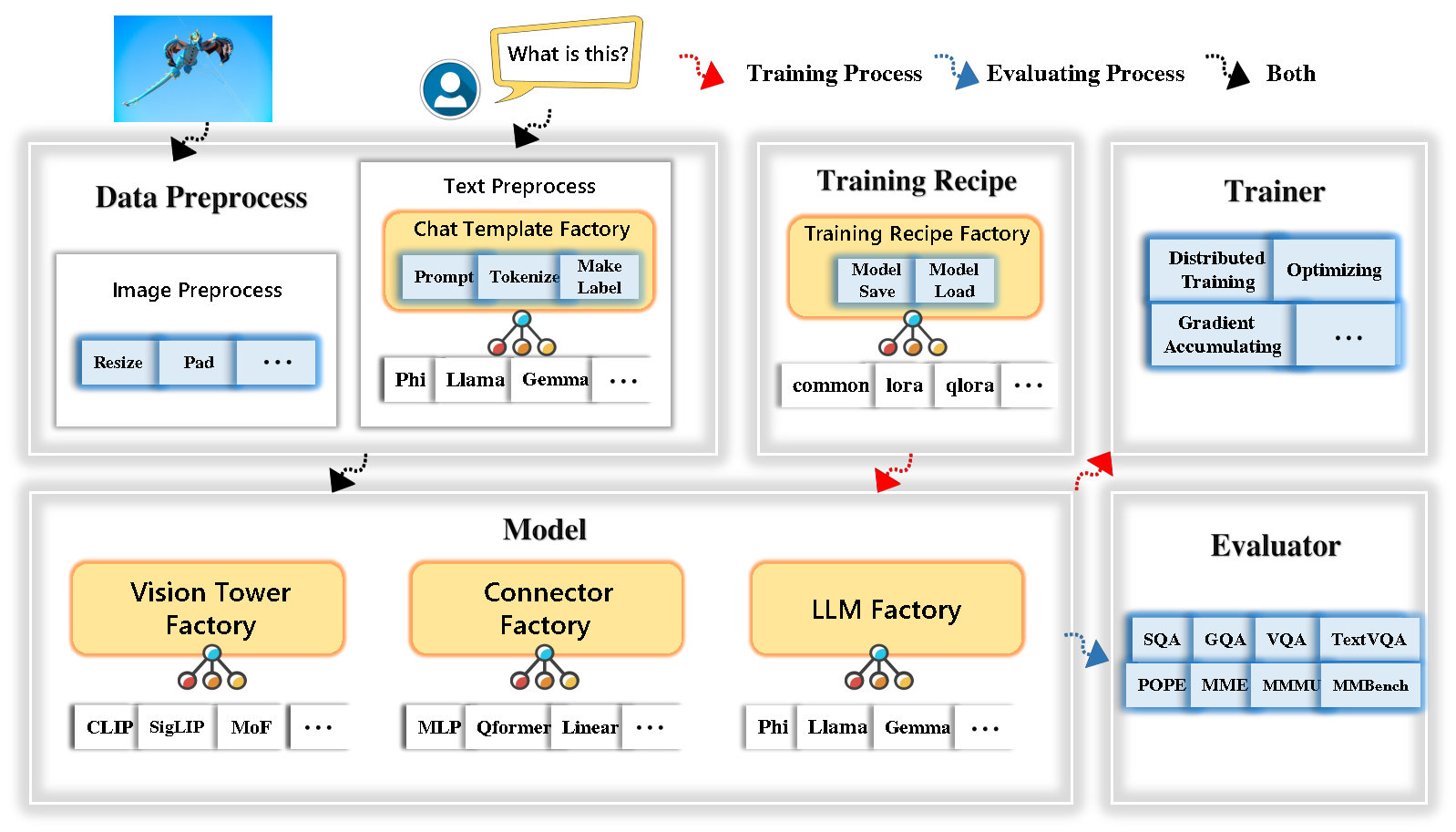
Tinyllava Factory เป็นรหัสโมดูลาร์โอเพนซอร์ซสำหรับโมเดลขนาดใหญ่หลายรูปแบบ (LMMs) ขนาดเล็ก (LMMs) ซึ่งนำมาใช้ใน Pytorch และ HuggingFace โดยมุ่งเน้นไปที่ความเรียบง่ายของการใช้งานรหัสการขยายคุณสมบัติใหม่และการทำซ้ำของผลการฝึกอบรม
ด้วยโรงงาน Tinyllava คุณสามารถปรับแต่งโมเดลหลายรูปแบบขนาดใหญ่ของคุณเองด้วยความพยายามในการเข้ารหัสน้อยลงและความผิดพลาดในการเข้ารหัสน้อยลง
โรงงาน Tinyllava รวมชุดของแบบจำลองและวิธีการที่ทันสมัย
ปัจจุบัน LLM รองรับ OpenElm , Tinyllama , Stablelm , Qwen , Gemma และ PHI
ปัจจุบัน Vision Tower รองรับ คลิป, Siglip , Dino และ การรวมกันของคลิปและ Dino
ปัจจุบันตัวเชื่อมต่อรองรับ MLP , QFormer และ Resampler
ปัจจุบันสูตรการฝึกอบรมรองรับ การปรับแต่งแช่แข็ง/เต็ม/บางส่วน และ การปรับแต่ง LORA/QLORA
โปรดทราบว่าข้อกำหนดด้านสภาพแวดล้อมของเรานั้นแตกต่างจากข้อกำหนดด้านสภาพแวดล้อมของ LLAVA เราขอแนะนำให้คุณสร้างสภาพแวดล้อมตั้งแต่เริ่มต้นดังนี้
git clone https://github.com/TinyLLaVA/TinyLLaVA_Factory.git
cd TinyLLaVA_Factoryconda create -n tinyllava_factory python=3.10 -y
conda activate tinyllava_factory
pip install --upgrade pip # enable PEP 660 support
pip install -e .pip install flash-attn --no-build-isolationgit pull
pip install -e . โปรดดูส่วนการเตรียมข้อมูลในเอกสารของเรา
นี่คือตัวอย่างสำหรับการฝึก LMM โดยใช้ Phi-2
scripts/train/train_phi.shoutput_dir ด้วยของคุณใน scripts/train/pretrain.shpretrained_model_path และ output_dir ด้วยของคุณใน scripts/train/finetune.shper_device_train_batch_size ใน scripts/train/pretrain.sh และ scripts/train/finetune.sh bash scripts/train/train_phi.shพารามิเตอร์ที่สำคัญที่ใช้ในการปรับสภาพและการปรับแต่งมีให้ด้านล่าง
| ขั้นตอนการฝึกอบรม | ขนาดแบทช์ทั่วโลก | อัตราการเรียนรู้ | conv_version |
|---|---|---|---|
| การผ่าตัดก่อน | 256 | 1E-3 | ก่อน |
| การทำให้หมดแรง | 128 | 2e-5 | พี |
เคล็ดลับ:
Global Batch Size = NUM ของ GPU * per_device_train_batch_size * gradient_accumulation_steps เราขอแนะนำให้คุณรักษาขนาดแบทช์ทั่วโลกและอัตราการเรียนรู้ไว้ข้างต้นยกเว้น LORA จูนโมเดลของคุณ
conv_version เป็นไฮเปอร์พารามิเตอร์ที่ใช้สำหรับการเลือกเทมเพลตแชทที่แตกต่างกันสำหรับ LLM ที่แตกต่างกัน ในขั้นตอนการเตรียมการ conv_version จะเหมือนกันสำหรับ LLM ทั้งหมดโดยใช้ pretrain ในขั้นตอน finetuning เราใช้
phi สำหรับ phi-2, stablelm, qwen-1.5
llama สำหรับ Tinyllama, OpenElm
gemma สำหรับ Gemma
โปรดดูส่วนการประเมินผลในเอกสารของเรา
ซึ่งได้รับการฝึกฝนโดยใช้โรงงาน Tinyllava
| VT (เส้นทาง HF) | LLM (เส้นทาง HF) | สูตรอาหาร | VQA-V2 | GQA | sqa-image | textvqa | MM-VET | สมเด็จพระสันตะปาปา | mme | mmmu-val |
|---|---|---|---|---|---|---|---|---|---|---|
| openai/clip-vit-large-patch14-336 | Apple/OpenElm-450M-Instruct | ฐาน | 69.5 | 52.1 | 50.6 | 40.4 | 20.0 | 83.6 | 1052.9 | 23.9 |
| Google/siglip-SO400m-patch14-384 | Apple/OpenElm-450M-Instruct | ฐาน | 71.7 | 53.9 | 54.1 | 44.0 | 20.0 | 85.4 | 1118.8 | 24.0 |
| Google/siglip-SO400m-patch14-384 | QWEN/QWEN2-0.5B | ฐาน | 72.3 | 55.8 | 60.1 | 45.2 | 19.5 | 86.6 | 1153.0 | 29.7 |
| Google/siglip-SO400m-patch14-384 | qwen/qwen2.5-0.5b | ฐาน | 75.3 | 59.5 | 60.3 | 48.3 | 23.9 | 86.1 | 1253.0 | 33.3 |
| Google/siglip-SO400m-patch14-384 | qwen/qwen2.5-3b | ฐาน | 79.4 | 62.5 | 74.1 | 58.3 | 34.8 | 87.4 | 1438.7 | 39.9 |
| openai/clip-vit-large-patch14-336 | Tinyllama/Tinyllama-1.1b-chat-v1.0 | ฐาน | 73.7 | 58.0 | 59.9 | 46.3 | 23.2 | 85.5 | 1284.6 | 27.9 |
| Google/siglip-SO400m-patch14-384 | Tinyllama/Tinyllama-1.1b-chat-v1.0 | ฐาน | 75.5 | 58.6 | 64.0 | 49.6 | 23.5 | 86.3 | 1256.5 | 28.3 |
| openai/clip-vit-large-patch14-336 | ความเสถียร/stablelm-2-zephyr-1_6b | ฐาน | 75.9 | 59.5 | 64.6 | 50.5 | 27.3 | 86.1 | 1368.1 | 31.8 |
| Google/siglip-SO400m-patch14-384 | ความเสถียร/stablelm-2-zephyr-1_6b | ฐาน | 78.2 | 60.7 | 66.7 | 56.0 | 29.4 | 86.3 | 1319.3 | 32.6 |
| Google/siglip-SO400m-patch14-384 | Google/gemma-2b-it | ฐาน | 78.4 | 61.6 | 64.4 | 53.6 | 26.9 | 86.4 | 1339.0 | 31.7 |
| openai/clip-vit-large-patch14-336 | Microsoft/Phi-2 | ฐาน | 76.8 | 59.4 | 71.2 | 53.4 | 31.7 | 86.8 | 1448.6 | 36.3 |
| Google/siglip-SO400m-patch14-384 | Microsoft/Phi-2 | ฐาน | 79.2 | 61.6 | 71.9 | 57.4 | 35.0 | 87.2 | 1462.4 | 38.2 |
| Google/siglip-SO400m-patch14-384 | Microsoft/Phi-2 | ฐาน & lora | 77.6 | 59.7 | 71.6 | 53.8 | 33.3 | 87.9 | 1413.2 | 35.6 |
| Google/siglip-SO400m-patch14-384 | Microsoft/Phi-2 | แบ่งปัน | 80.1 | 62.1 | 73.0 | 60.3 | 37.5 | 87.2 | 1466.4 | 38.4 |
ซึ่งได้รับการฝึกฝนโดยใช้ codebase เก่า tinyllavabench
หากคุณมีโมเดลที่ได้รับการฝึกฝนโดย Codebase Tinyllavabench เก่าของเราและคุณยังต้องการใช้งานอยู่เราให้ตัวอย่างของ Tinyllava-3.1b สำหรับวิธีการใช้แบบจำลองมรดก
from tinyllava . eval . run_tiny_llava import eval_model
from tinyllava . model . convert_legecy_weights_to_tinyllavafactory import *
model = convert_legecy_weights_to_tinyllavafactory ( 'bczhou/TinyLLaVA-3.1B' )
prompt = "What are the things I should be cautious about when I visit here?"
image_file = "https://llava-vl.github.io/static/images/view.jpg"
args = type ( 'Args' , (), {
"model_path" : None ,
"model" : model ,
"query" : prompt ,
"conv_mode" : "phi" , # the same as conv_version in the training stage. Different LLMs have different conv_mode/conv_version, please replace it
"image_file" : image_file ,
"sep" : "," ,
"temperature" : 0 ,
"top_p" : None ,
"num_beams" : 1 ,
"max_new_tokens" : 512
})()
eval_model ( args )
"""
Output:
When visiting this serene lakeside location with a wooden dock, there are a few things to be cautious about. First, ensure that the dock is stable and secure before stepping onto it, as it might be slippery or wet, especially if it's a wooden structure. Second, be mindful of the surrounding water, as it can be deep or have hidden obstacles, such as rocks or debris, that could pose a risk. Additionally, be aware of the weather conditions, as sudden changes in weather can make the area more dangerous. Lastly, respect the natural environment and wildlife, and avoid littering or disturbing the ecosystem.
""" เปิดการสาธิตเว็บในพื้นที่โดยรัน:
python tinyllava/serve/app.py --model-path tinyllava/TinyLLaVA-Phi-2-SigLIP-3.1Bนอกจากนี้เรายังสนับสนุนการอนุมานกับ CLI เพื่อใช้โมเดลของเรา Run:
python -m tinyllava.serve.cli
--model-path tinyllava/TinyLLaVA-Phi-2-SigLIP-3.1B
--image-file " ./tinyllava/serve/examples/extreme_ironing.jpg " หากคุณต้องการเปิดตัวโมเดลที่ได้รับการฝึกฝนด้วยตัวเองหรือเราในพื้นที่นี่เป็นตัวอย่าง
from tinyllava . eval . run_tiny_llava import eval_model
model_path = "/absolute/path/to/your/model/"
prompt = "What are the things I should be cautious about when I visit here?"
image_file = "https://llava-vl.github.io/static/images/view.jpg"
conv_mode = "phi" # or llama, gemma, etc
args = type ( 'Args' , (), {
"model_path" : model_path ,
"model" : None ,
"query" : prompt ,
"conv_mode" : conv_mode ,
"image_file" : image_file ,
"sep" : "," ,
"temperature" : 0 ,
"top_p" : None ,
"num_beams" : 1 ,
"max_new_tokens" : 512
})()
eval_model ( args )
"""
Output:
XXXXXXXXXXXXXXXXX
""" from transformers import AutoTokenizer , AutoModelForCausalLM
hf_path = 'tinyllava/TinyLLaVA-Phi-2-SigLIP-3.1B'
model = AutoModelForCausalLM . from_pretrained ( hf_path , trust_remote_code = True )
model . cuda ()
config = model . config
tokenizer = AutoTokenizer . from_pretrained ( hf_path , use_fast = False , model_max_length = config . tokenizer_model_max_length , padding_side = config . tokenizer_padding_side )
prompt = "What are these?"
image_url = "http://images.cocodataset.org/val2017/000000039769.jpg"
output_text , genertaion_time = model . chat ( prompt = prompt , image = image_url , tokenizer = tokenizer )
print ( 'model output:' , output_text )
print ( 'runing time:' , genertaion_time )หากคุณต้องการ finetune tinyllava ด้วยชุดข้อมูลที่กำหนดเองของคุณโปรดดูที่นี่
หากคุณต้องการเพิ่ม LLM ใหม่ด้วยตัวเองคุณต้องสร้างสองไฟล์: หนึ่งไฟล์สำหรับเทมเพลตแชทและอื่น ๆ สำหรับโมเดลภาษาภายใต้โฟลเดอร์ tinyllava/data/template/ และ tinyllava/model/llm/
นี่คือตัวอย่างของการเพิ่มโมเดล Gemma
ประการแรกสร้าง tinyllava/data/template/gemma_template.py ซึ่งจะใช้สำหรับขั้นตอน finetuning
from dataclasses import dataclass
from typing import TYPE_CHECKING , Dict , List , Optional , Sequence , Tuple , Union
from packaging import version
from . formatter import EmptyFormatter , StringFormatter
from . base import Template
from . formatter import Formatter
from . import register_template
from ... utils . constants import *
from transformers import PreTrainedTokenizer
import torch
import tokenizers
system = "A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user's questions."
@ register_template ( 'gemma' ) # Enable the TemplateFactory to obtain the added template by this string ('gemma').
@ dataclass
class GemmaTemplate ( Template ):
format_image_token : "Formatter" = StringFormatter ( slot = "<image> n {{content}}" )
format_user : "Formatter" = StringFormatter ( slot = "USER" + ": " + "{{content}}" + " " )
format_assistant : "Formatter" = StringFormatter ( slot = "ASSISTANT" + ": " + "{{content}}" + "<eos>" ) # to be modified according to the tokenizer you choose
system : "Formatter" = EmptyFormatter ( slot = system + " " )
separator : "Formatter" = EmptyFormatter ( slot = [ ' ASSISTANT: ' , '<eos>' ]) # to be modified according to the tokenizer you choose
def _make_masks ( self , labels , tokenizer , sep , eos_token_length , rounds ):
# your code here
return labels , cur_lenเคล็ดลับ:
โปรดตรวจสอบให้แน่ใจว่า labels (ส่งคืนโดยฟังก์ชัน _make_masks ) ตามรูปแบบนี้: คำตอบและรหัสโทเค็น EOS ไม่ได้ถูกปกปิดและโทเค็นอื่น ๆ จะถูกสวมหน้ากากด้วย -100
ประการที่สองสร้าง tinyllava/model/llm/gemma.py
from transformers import GemmaForCausalLM , AutoTokenizer
# The LLM you want to add along with its corresponding tokenizer.
from . import register_llm
# Add GemmaForCausalLM along with its corresponding tokenizer and handle special tokens.
@ register_llm ( 'gemma' ) # Enable the LLMFactory to obtain the added LLM by this string ('gemma').
def return_gemmaclass ():
def tokenizer_and_post_load ( tokenizer ):
tokenizer . pad_token = tokenizer . unk_token
return tokenizer
return ( GemmaForCausalLM , ( AutoTokenizer , tokenizer_and_post_load )) ในที่สุดสร้าง scripts/train/train_gemma.sh ด้วย LLM_VERSION ที่สอดคล้องกันและ CONV_VERSION
หากคุณต้องการเพิ่มหอวิสัยทัศน์ใหม่คุณต้องใช้คลาส Vision Tower ใหม่ที่ควรได้รับการสืบทอดจาก VisionTower ชั้นเรียน นี่คือตัวอย่างของหอวิสัยทัศน์ MOF
ก่อนอื่นให้สร้าง tinyllava/model/vision_tower/mof.py
@ register_vision_tower ( 'mof' )
class MoFVisionTower ( VisionTower ):
def __init__ ( self , cfg ):
super (). __init__ ( cfg )
self . _vision_tower = MoF ( cfg )
self . _image_processor = # your image processor
def _load_model ( self , vision_tower_name , ** kwargs ):
# your code here, make sure your model can be correctly loaded from pretrained parameters either by huggingface or pytorch loading
def forward ( self , x , ** kwargs ):
# your code here จากนั้นแก้ไขสคริปต์การฝึกอบรมของคุณด้วย VT_VERSION ที่สอดคล้องกัน
หากคุณต้องการเพิ่มตัวเชื่อมต่อใหม่คุณจะต้องใช้คลาสคอนเนตเตอร์ใหม่ที่ควรได้รับการสืบทอดจาก Connector คลาสพื้นฐาน นี่คือตัวอย่างของขั้วต่อเชิงเส้น
ก่อนอื่นให้สร้าง tinyllava/model/connector/linear.py
import torch . nn as nn
from . import register_connector
from . base import Connector
@ register_connector ( 'linear' ) #Enable the ConnectorMFactory to obtain the added connector by this string ('linear').
class LinearConnector ( Connector ):
def __init__ ( self , config ):
super (). __init__ ()
self . _connector = nn . Linear ( config . vision_hidden_size , config . hidden_size ) # define your connector model จากนั้นแก้ไขสคริปต์การฝึกอบรมของคุณด้วย CN_VERSION ที่สอดคล้องกัน
เราขอขอบคุณเป็นพิเศษกับ Lei Zhao, Luche Wang, Kaijun Luo และ Junchen Wang สำหรับการสร้างตัวอย่าง
หากคุณมีคำถามใด ๆ อย่าลังเลที่จะเริ่มต้น ปัญหา หรือติดต่อเราโดย WeChat (WeChatid: Tinyllava )
หากคุณพบว่ากระดาษและรหัสของเรามีประโยชน์ในการวิจัยของคุณโปรดพิจารณาให้ดาวและการอ้างอิง
@misc { zhou2024tinyllava ,
title = { TinyLLaVA: A Framework of Small-scale Large Multimodal Models } ,
author = { Baichuan Zhou and Ying Hu and Xi Weng and Junlong Jia and Jie Luo and Xien Liu and Ji Wu and Lei Huang } ,
year = { 2024 } ,
eprint = { 2402.14289 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.LG }
} @article { jia2024tinyllava ,
title = { TinyLLaVA Factory: A Modularized Codebase for Small-scale Large Multimodal Models } ,
author = { Jia, Junlong and Hu, Ying and Weng, Xi and Shi, Yiming and Li, Miao and Zhang, Xingjian and Zhou, Baichuan and Liu, Ziyu and Luo, Jie and Huang, Lei and Wu, Ji } ,
journal = { arXiv preprint arXiv:2405.11788 } ,
year = { 2024 }
}

