TinyLLaVA_Factory
1.0.0
Nosso melhor modelo, Tinyllava-Phi-2-Siglip-3.1b, alcança um melhor desempenho geral contra modelos 7B existentes, como LLAVA-1.5 e QWEN-VL.
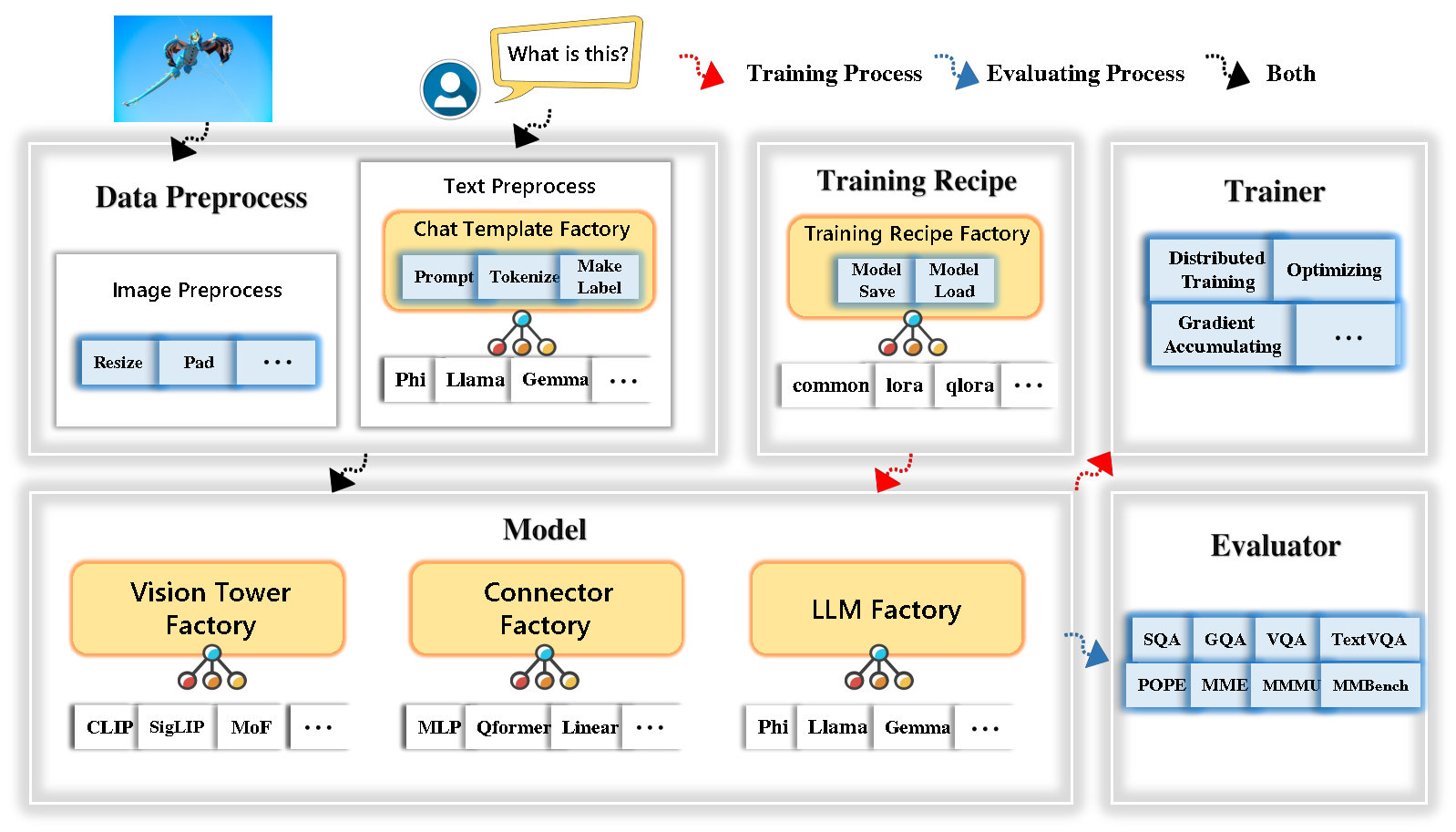
A Tinyllava Factory é uma base de código modular de código aberto para grandes modelos multimodais em pequena escala (LMMs), implementados em Pytorch e Huggingface, com foco na simplicidade das implementações de código, extensibilidade de novos recursos e reprodutibilidade dos resultados do treinamento.
Com a Tinyllava Factory, você pode personalizar seus próprios modelos multimodais grandes com menos esforço de codificação e menos erros de codificação.
A Tinyllava Factory integra um conjunto de modelos e métodos de ponta.
Atualmente, o LLM suporta o OpenElm , Tinyllama , Stablelm , Qwen , Gemma e Phi .
A Vision Tower atualmente suporta clipe, siglip , dino e combinação de clipe e dino .
Atualmente, o Connector suporta MLP , Qformer e ReMampler .
Atualmente, a receita de treinamento suporta ajuste congelado/totalmente/parcialmente e o ajuste Lora/Qlora .
Observe que nossos requisitos de ambiente são diferentes dos requisitos ambientais da LLAVA. Recomendamos fortemente que você crie o ambiente a partir do zero da seguinte maneira.
git clone https://github.com/TinyLLaVA/TinyLLaVA_Factory.git
cd TinyLLaVA_Factoryconda create -n tinyllava_factory python=3.10 -y
conda activate tinyllava_factory
pip install --upgrade pip # enable PEP 660 support
pip install -e .pip install flash-attn --no-build-isolationgit pull
pip install -e . Consulte a seção de preparação de dados em nossa documentação.
Aqui está um exemplo para treinar um LMM usando PHI-2.
scripts/train/train_phi.shoutput_dir por seus scripts/train/pretrain.shpretrained_model_path e output_dir por seus scripts/train/finetune.shper_device_train_batch_size em scripts/train/pretrain.sh e scripts/train/finetune.sh bash scripts/train/train_phi.shOs hiperparâmetros importantes usados em pré -treinamento e finetuning são fornecidos abaixo.
| Estágio de treinamento | Tamanho global do lote | Taxa de aprendizado | Conv_version |
|---|---|---|---|
| Pré -fiel | 256 | 1e-3 | Pré |
| Afinação | 128 | 2E-5 | Phi |
Pontas:
Tamanho do lote global = num de gpus * per_device_train_batch_size * gradient_accumulation_steps , recomendamos que você sempre mantenha o tamanho do lote global e a taxa de aprendizado, exceto Lora Ajuste seu modelo.
conv_version é um hiperparâmetro usado para escolher modelos de bate -papo diferentes para diferentes LLMs. No estágio de pré -treinamento, conv_version é o mesmo para todos os LLMs, usando pretrain . No estágio de Finetuning, usamos
phi para Phi-2, Stablelm, Qwen-1.5
llama para Tinyllama, OpenElm
gemma para Gemma
Consulte a seção de avaliação em nossa documentação.
que são treinados usando a Tinyllava Factory.
| VT (caminho da HF) | LLM (caminho da HF) | Receita | VQA-V2 | GQA | SQA-Image | TextVqa | MM-VET | PAPA | Mme | MMMU-VAL |
|---|---|---|---|---|---|---|---|---|---|---|
| OpenAI/Clip-Vit-Large-Patch14-336 | Apple/OpenELM-450M-Instruct | base | 69.5 | 52.1 | 50.6 | 40.4 | 20.0 | 83.6 | 1052.9 | 23.9 |
| Google/Siglip-SO400M-PATCH14-384 | Apple/OpenELM-450M-Instruct | base | 71.7 | 53.9 | 54.1 | 44.0 | 20.0 | 85.4 | 1118.8 | 24.0 |
| Google/Siglip-SO400M-PATCH14-384 | QWEN/QWEN2-0.5B | base | 72.3 | 55.8 | 60.1 | 45.2 | 19.5 | 86.6 | 1153.0 | 29.7 |
| Google/Siglip-SO400M-PATCH14-384 | QWEN/QWEN2.5-0.5B | base | 75.3 | 59.5 | 60.3 | 48.3 | 23.9 | 86.1 | 1253.0 | 33.3 |
| Google/Siglip-SO400M-PATCH14-384 | QWEN/QWEN2.5-3B | base | 79.4 | 62.5 | 74.1 | 58.3 | 34.8 | 87.4 | 1438.7 | 39.9 |
| OpenAI/Clip-Vit-Large-Patch14-336 | Tinyllama/Tinyllama-1.1b-chat-v1.0 | base | 73.7 | 58.0 | 59.9 | 46.3 | 23.2 | 85.5 | 1284.6 | 27.9 |
| Google/Siglip-SO400M-PATCH14-384 | Tinyllama/Tinyllama-1.1b-chat-v1.0 | base | 75.5 | 58.6 | 64.0 | 49.6 | 23.5 | 86.3 | 1256.5 | 28.3 |
| OpenAI/Clip-Vit-Large-Patch14-336 | Stabilityai/StableLM-2-Zephyr-1_6b | base | 75.9 | 59.5 | 64.6 | 50.5 | 27.3 | 86.1 | 1368.1 | 31.8 |
| Google/Siglip-SO400M-PATCH14-384 | Stabilityai/StableLM-2-Zephyr-1_6b | base | 78.2 | 60.7 | 66.7 | 56.0 | 29.4 | 86.3 | 1319.3 | 32.6 |
| Google/Siglip-SO400M-PATCH14-384 | Google/gemma-2b-it | base | 78.4 | 61.6 | 64.4 | 53.6 | 26.9 | 86.4 | 1339.0 | 31.7 |
| OpenAI/Clip-Vit-Large-Patch14-336 | Microsoft/Phi-2 | base | 76.8 | 59.4 | 71.2 | 53.4 | 31.7 | 86.8 | 1448.6 | 36.3 |
| Google/Siglip-SO400M-PATCH14-384 | Microsoft/Phi-2 | base | 79.2 | 61.6 | 71.9 | 57.4 | 35.0 | 87.2 | 1462.4 | 38.2 |
| Google/Siglip-SO400M-PATCH14-384 | Microsoft/Phi-2 | Base & Lora | 77.6 | 59.7 | 71.6 | 53.8 | 33.3 | 87.9 | 1413.2 | 35.6 |
| Google/Siglip-SO400M-PATCH14-384 | Microsoft/Phi-2 | compartilhar | 80.1 | 62.1 | 73.0 | 60.3 | 37.5 | 87.2 | 1466.4 | 38.4 |
que são treinados usando a antiga base de código Tinyllavabench.
Se você possui modelos treinados por nossa antiga base de código Tinyllavabench e ainda deseja usá-los, fornecemos um exemplo de Tinyllava-3.1b para usar modelos legados.
from tinyllava . eval . run_tiny_llava import eval_model
from tinyllava . model . convert_legecy_weights_to_tinyllavafactory import *
model = convert_legecy_weights_to_tinyllavafactory ( 'bczhou/TinyLLaVA-3.1B' )
prompt = "What are the things I should be cautious about when I visit here?"
image_file = "https://llava-vl.github.io/static/images/view.jpg"
args = type ( 'Args' , (), {
"model_path" : None ,
"model" : model ,
"query" : prompt ,
"conv_mode" : "phi" , # the same as conv_version in the training stage. Different LLMs have different conv_mode/conv_version, please replace it
"image_file" : image_file ,
"sep" : "," ,
"temperature" : 0 ,
"top_p" : None ,
"num_beams" : 1 ,
"max_new_tokens" : 512
})()
eval_model ( args )
"""
Output:
When visiting this serene lakeside location with a wooden dock, there are a few things to be cautious about. First, ensure that the dock is stable and secure before stepping onto it, as it might be slippery or wet, especially if it's a wooden structure. Second, be mindful of the surrounding water, as it can be deep or have hidden obstacles, such as rocks or debris, that could pose a risk. Additionally, be aware of the weather conditions, as sudden changes in weather can make the area more dangerous. Lastly, respect the natural environment and wildlife, and avoid littering or disturbing the ecosystem.
""" Inicie uma demonstração da Web local em execução:
python tinyllava/serve/app.py --model-path tinyllava/TinyLLaVA-Phi-2-SigLIP-3.1BTambém apoiamos a inferência com a CLI. Para usar nosso modelo, execute:
python -m tinyllava.serve.cli
--model-path tinyllava/TinyLLaVA-Phi-2-SigLIP-3.1B
--image-file " ./tinyllava/serve/examples/extreme_ironing.jpg " Se você deseja iniciar o modelo treinado por você ou por nós localmente, aqui está um exemplo.
from tinyllava . eval . run_tiny_llava import eval_model
model_path = "/absolute/path/to/your/model/"
prompt = "What are the things I should be cautious about when I visit here?"
image_file = "https://llava-vl.github.io/static/images/view.jpg"
conv_mode = "phi" # or llama, gemma, etc
args = type ( 'Args' , (), {
"model_path" : model_path ,
"model" : None ,
"query" : prompt ,
"conv_mode" : conv_mode ,
"image_file" : image_file ,
"sep" : "," ,
"temperature" : 0 ,
"top_p" : None ,
"num_beams" : 1 ,
"max_new_tokens" : 512
})()
eval_model ( args )
"""
Output:
XXXXXXXXXXXXXXXXX
""" from transformers import AutoTokenizer , AutoModelForCausalLM
hf_path = 'tinyllava/TinyLLaVA-Phi-2-SigLIP-3.1B'
model = AutoModelForCausalLM . from_pretrained ( hf_path , trust_remote_code = True )
model . cuda ()
config = model . config
tokenizer = AutoTokenizer . from_pretrained ( hf_path , use_fast = False , model_max_length = config . tokenizer_model_max_length , padding_side = config . tokenizer_padding_side )
prompt = "What are these?"
image_url = "http://images.cocodataset.org/val2017/000000039769.jpg"
output_text , genertaion_time = model . chat ( prompt = prompt , image = image_url , tokenizer = tokenizer )
print ( 'model output:' , output_text )
print ( 'runing time:' , genertaion_time )Se você deseja Finetune Tinyllava com seus conjuntos de dados personalizados, consulte aqui.
Se você deseja adicionar um novo LLM sozinho, precisará criar dois arquivos: um para o modelo de bate -papo e outro para modelo de idioma, nas pastas tinyllava/data/template/ e tinyllava/model/llm/ .
Aqui está um exemplo de adicionar o modelo Gemma.
Em primeiro lugar, crie tinyllava/data/template/gemma_template.py , que será usado para o estágio de Finetuning.
from dataclasses import dataclass
from typing import TYPE_CHECKING , Dict , List , Optional , Sequence , Tuple , Union
from packaging import version
from . formatter import EmptyFormatter , StringFormatter
from . base import Template
from . formatter import Formatter
from . import register_template
from ... utils . constants import *
from transformers import PreTrainedTokenizer
import torch
import tokenizers
system = "A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user's questions."
@ register_template ( 'gemma' ) # Enable the TemplateFactory to obtain the added template by this string ('gemma').
@ dataclass
class GemmaTemplate ( Template ):
format_image_token : "Formatter" = StringFormatter ( slot = "<image> n {{content}}" )
format_user : "Formatter" = StringFormatter ( slot = "USER" + ": " + "{{content}}" + " " )
format_assistant : "Formatter" = StringFormatter ( slot = "ASSISTANT" + ": " + "{{content}}" + "<eos>" ) # to be modified according to the tokenizer you choose
system : "Formatter" = EmptyFormatter ( slot = system + " " )
separator : "Formatter" = EmptyFormatter ( slot = [ ' ASSISTANT: ' , '<eos>' ]) # to be modified according to the tokenizer you choose
def _make_masks ( self , labels , tokenizer , sep , eos_token_length , rounds ):
# your code here
return labels , cur_lenPontas:
Certifique -se de que os labels (devolvidos pela função _make_masks ) sigam este formato: as respostas e o ID do token EOS não são mascaradas e os outros tokens são mascarados com -100 .
Em segundo lugar, crie tinyllava/model/llm/gemma.py .
from transformers import GemmaForCausalLM , AutoTokenizer
# The LLM you want to add along with its corresponding tokenizer.
from . import register_llm
# Add GemmaForCausalLM along with its corresponding tokenizer and handle special tokens.
@ register_llm ( 'gemma' ) # Enable the LLMFactory to obtain the added LLM by this string ('gemma').
def return_gemmaclass ():
def tokenizer_and_post_load ( tokenizer ):
tokenizer . pad_token = tokenizer . unk_token
return tokenizer
return ( GemmaForCausalLM , ( AutoTokenizer , tokenizer_and_post_load )) Finalmente, crie scripts/train/train_gemma.sh com o correspondente LLM_VERSION e CONV_VERSION .
Se você deseja adicionar uma nova torre de visão, precisará implementar uma nova classe de torre de visão que deve ser herdada da classe Base Class VisionTower . Aqui está um exemplo da torre de visão MOF.
Primeiro, crie tinyllava/model/vision_tower/mof.py
@ register_vision_tower ( 'mof' )
class MoFVisionTower ( VisionTower ):
def __init__ ( self , cfg ):
super (). __init__ ( cfg )
self . _vision_tower = MoF ( cfg )
self . _image_processor = # your image processor
def _load_model ( self , vision_tower_name , ** kwargs ):
# your code here, make sure your model can be correctly loaded from pretrained parameters either by huggingface or pytorch loading
def forward ( self , x , ** kwargs ):
# your code here Em seguida, modifique seus scripts de treinamento com o VT_VERSION correspondente.
Se você deseja adicionar um novo conector, é necessário implementar uma nova classe de conector que deve ser herdada do Connector da classe base. Aqui está um exemplo do conector linear.
Primeiro, crie tinyllava/model/connector/linear.py
import torch . nn as nn
from . import register_connector
from . base import Connector
@ register_connector ( 'linear' ) #Enable the ConnectorMFactory to obtain the added connector by this string ('linear').
class LinearConnector ( Connector ):
def __init__ ( self , config ):
super (). __init__ ()
self . _connector = nn . Linear ( config . vision_hidden_size , config . hidden_size ) # define your connector model Em seguida, modifique seus scripts de treinamento com o CN_VERSION correspondente.
Agradecemos especiais a Lei Zhao, Luche Wang, Kaijun Luo e Junchen Wang por construir a demo.
Se você tiver alguma dúvida, sinta -se à vontade para iniciar um problema ou entre em contato conosco por WeChat (WeChatid: Tinyllava ).
Se você achar nosso artigo e código úteis em sua pesquisa, considere dar uma estrela e uma citação.
@misc { zhou2024tinyllava ,
title = { TinyLLaVA: A Framework of Small-scale Large Multimodal Models } ,
author = { Baichuan Zhou and Ying Hu and Xi Weng and Junlong Jia and Jie Luo and Xien Liu and Ji Wu and Lei Huang } ,
year = { 2024 } ,
eprint = { 2402.14289 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.LG }
} @article { jia2024tinyllava ,
title = { TinyLLaVA Factory: A Modularized Codebase for Small-scale Large Multimodal Models } ,
author = { Jia, Junlong and Hu, Ying and Weng, Xi and Shi, Yiming and Li, Miao and Zhang, Xingjian and Zhou, Baichuan and Liu, Ziyu and Luo, Jie and Huang, Lei and Wu, Ji } ,
journal = { arXiv preprint arXiv:2405.11788 } ,
year = { 2024 }
}

