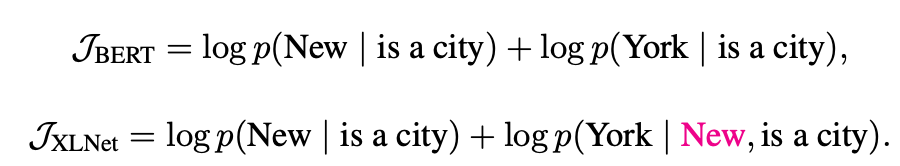xlnet Pytorch
1.0.0
帶有Pytorch包裝器的簡單XLNET實現!
$ git clone https://github.com/graykode/xlnet-Pytorch && cd xlnet-Pytorch
# To use Sentence Piece Tokenizer(pretrained-BERT Tokenizer)
$ pip install pytorch_pretrained_bert
$ python main.py --data ./data.txt --tokenizer bert-base-uncased
--seq_len 512 --reuse_len 256 --perm_size 256
--bi_data True --mask_alpha 6 --mask_beta 1
--num_predict 85 --mem_len 384 --num_epoch 100另外,您可以輕鬆地在Google Colab中運行代碼。
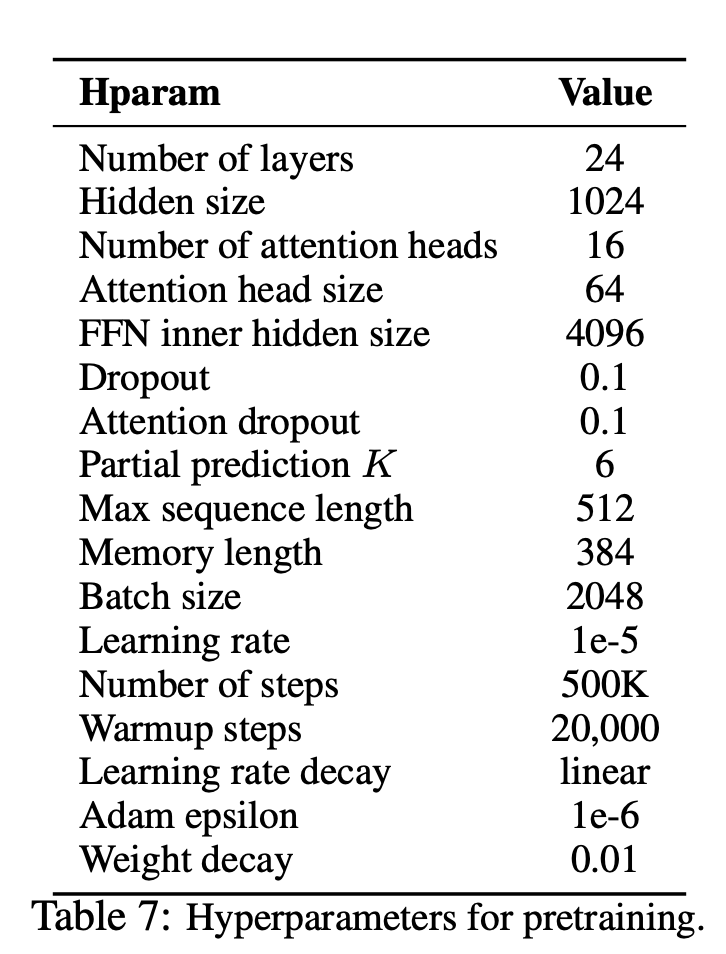
—data (字符串):要訓練的.txt文件。多行文本無關緊要。另外,一個文件將是一個批量張量。默認值: data.txt
—tokenizer (字符串):我只是使用huggingface/pytorch-pretretain-bert的令牌作為子字令牌(我會盡快將其編輯為句子)。您可以選擇基於bert-base-uncased bert-large-uncased unge, bert-base-cased , bert-large-cased 。默認值: bert-base-uncased
—seq_len (整數):序列長度。默認值: 512
—reuse_len (Interger):可以重複使用的令牌數量。可能是seq_len的一半。默認值: 256
—perm_size (Interger):最長置換的長度。可以設置為reuse_len。默認值: 256
--bi_data (布爾值):是否創建雙向數據。如果bi_data為True , biz(batch size)應為數字。默認值: False
—mask_alpha (Interger):形成一個組有多少個令牌。 Defalut: 6
—mask_beta (整數):每個組內掩蓋多少個令牌。默認值: 1
—num_predict (Interger):要預測的代幣數字。在紙上,這意味著部分預測。默認值: 85
—mem_len (Interger):在變壓器-XL體系結構中緩存的步驟數。默認值: 384
—num_epoch (Interger):時期數。默認值: 100
XLNET是一種基於新穎的廣義置換語言建模目標的新的無監督語言表示學習方法。此外,XLNET還採用Transformer-XL作為骨幹模型,在涉及長篇小說的語言任務方面表現出色。
| 模型 | mnli | Qnli | QQP | rte | SST-2 | MRPC | 可樂 | STS-B |
|---|---|---|---|---|---|---|---|---|
| 伯特 | 86.6 | 92.3 | 91.3 | 70.4 | 93.2 | 88.0 | 60.6 | 90.0 |
| xlnet | 89.8 | 93.9 | 91.8 | 83.8 | 95.6 | 89.2 | 63.6 | 91.8 |
XLNet如何從自動回歸和自動編碼模型中受益?
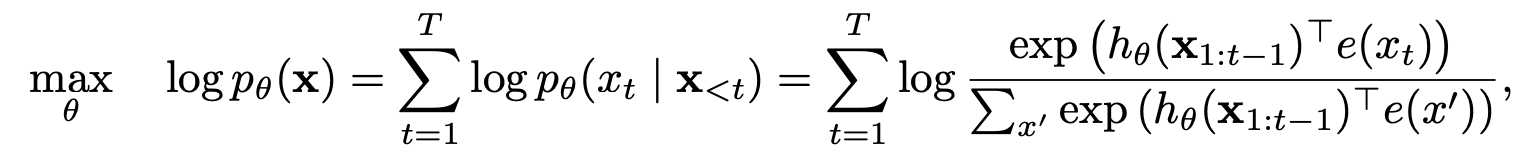
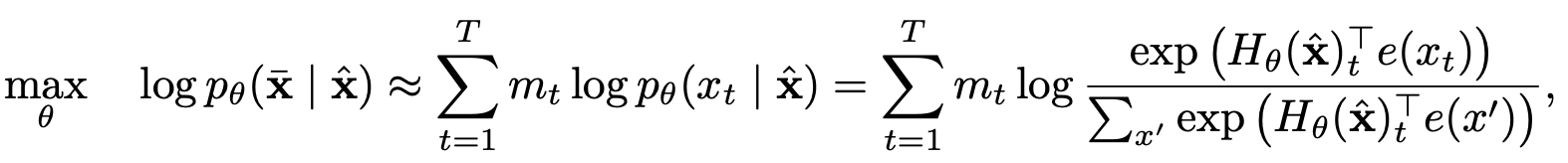
置換語言建模與部分預測
置換語言建模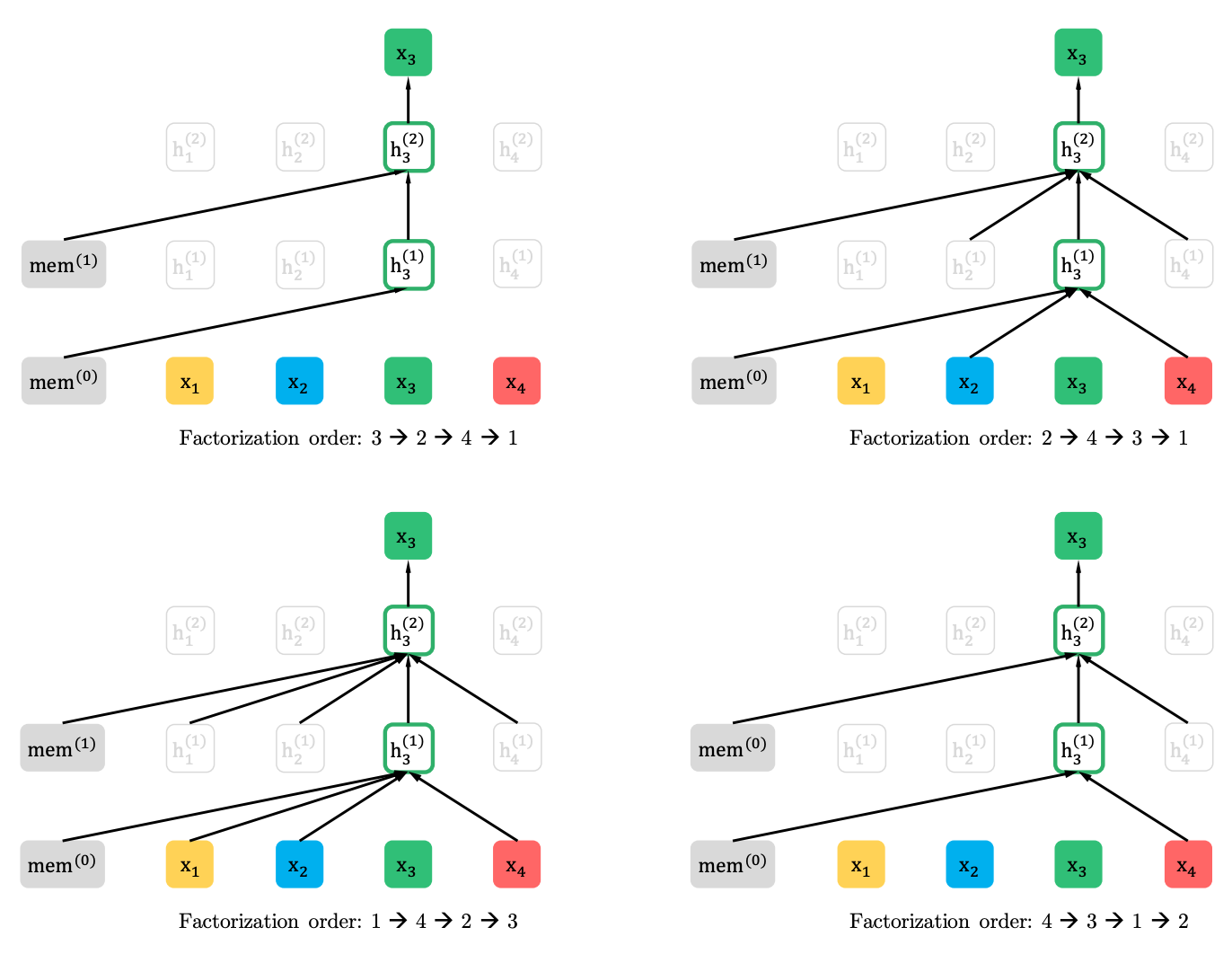
部分預測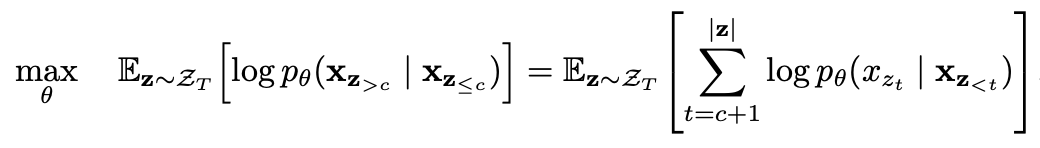
具有目標感知代表的兩流自我注意
兩史的自我注意力
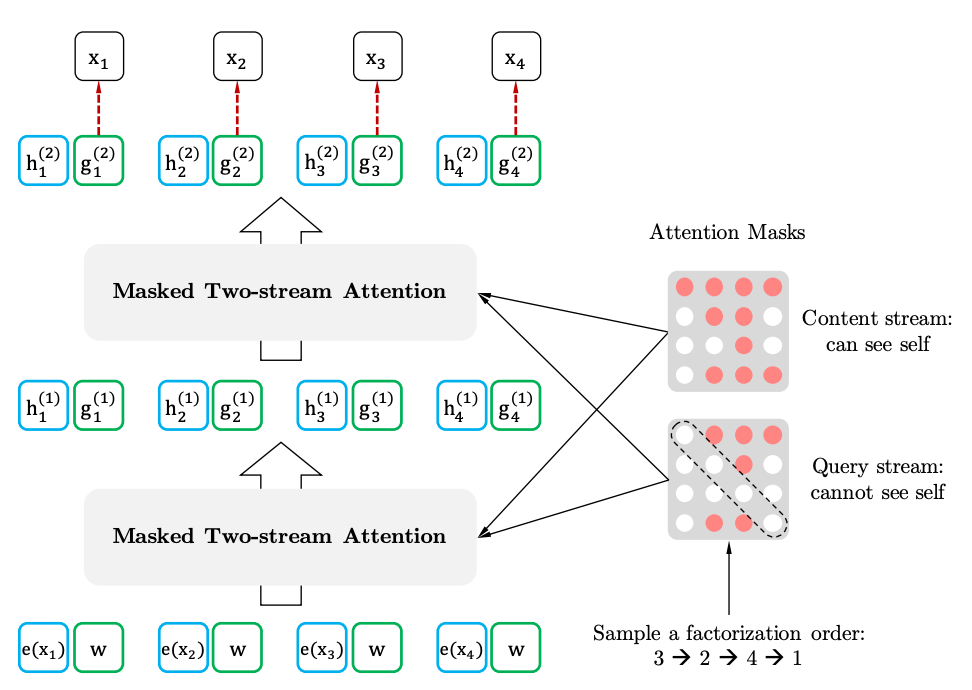
目標感知表示