xlnet Pytorch
1.0.0
Implementación simple de XLNet con Pytorch Wrapper!
$ git clone https://github.com/graykode/xlnet-Pytorch && cd xlnet-Pytorch
# To use Sentence Piece Tokenizer(pretrained-BERT Tokenizer)
$ pip install pytorch_pretrained_bert
$ python main.py --data ./data.txt --tokenizer bert-base-uncased
--seq_len 512 --reuse_len 256 --perm_size 256
--bi_data True --mask_alpha 6 --mask_beta 1
--num_predict 85 --mem_len 384 --num_epoch 100Además, puede ejecutar el código en Google Colab fácilmente.
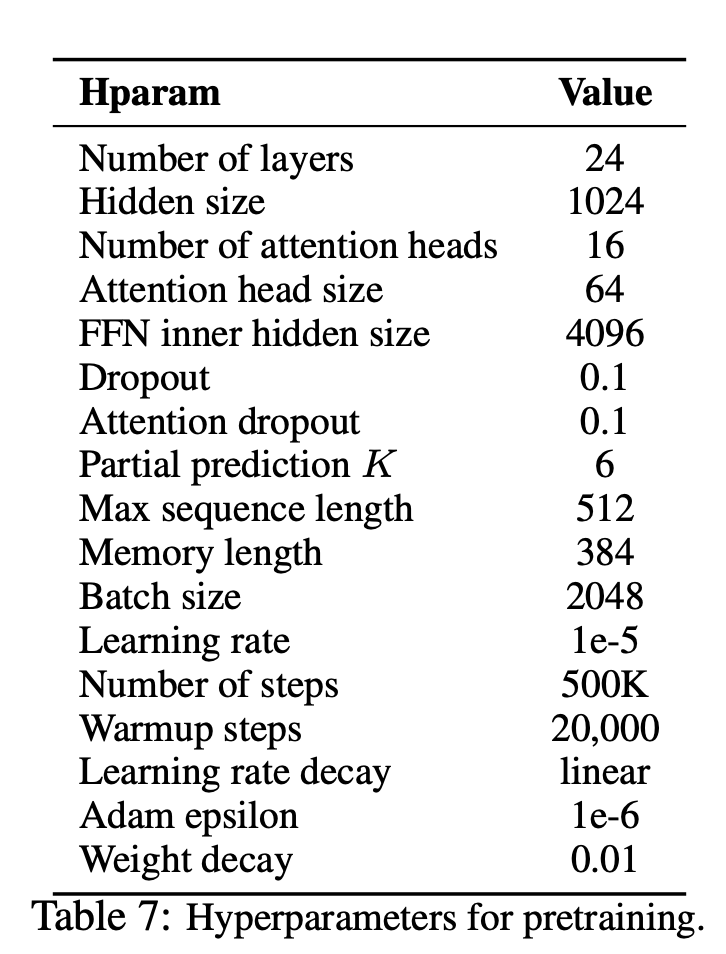
—data (cadena): archivo .txt para entrenar. No importa el texto multilínea. Además, un archivo será un tensor de lotes. Predeterminado: data.txt
—tokenizer (cadena): acabo de usar Huggingface/Pytorch preturado-Berts Tokenizer como Tokenizer de subvención (lo editaré en la pieza de oración pronto). Puede elegir en bert-base-uncased , bert-large-uncased , bert-base-cased , bert-large-cased . Valor predeterminado: bert-base-uncased
—seq_len (entero): longitud de secuencia. Valor predeterminado: 512
—reuse_len (Interger): número de token que se puede reutilizar como memoria. Podría ser la mitad de seq_len . Valor predeterminado: 256
—perm_size (Interger): la longitud de la permutación más larga. Podría configurarse para ser reutilizado_len. Valor predeterminado: 256
--bi_data (boolean): si se debe crear datos bidireccionales. Si bi_data es True , biz(batch size) debe ser un número uniforme. Valor predeterminado: False
—mask_alpha (Interger): cuántos tokens para formar un grupo. Defalut: 6
—mask_beta (entero): cuántos tokens enmascarar dentro de cada grupo. Valor predeterminado: 1
—num_predict (Interger): Número de tokens para predecir. En el papel, significa predicción parcial. Valor predeterminado: 85
—mem_len (Interger): número de pasos para almacenar en caché en la arquitectura Transformer-XL. Valor predeterminado: 384
—num_epoch (Interger): número de época. Valor predeterminado: 100
XLNet es un nuevo método de aprendizaje de representación de lenguaje no supervisado basado en un nuevo objetivo de modelado de lenguaje de permutación generalizada. Además, XLNet emplea Transformer-XL como modelo de columna vertebral, exhibiendo un excelente rendimiento para tareas de lenguaje que involucran un contexto largo.
| Modelo | Mnli | Qnli | QQP | RTE | SST-2 | MRPC | Reajuste salarial | STS-B |
|---|---|---|---|---|---|---|---|---|
| Bert | 86.6 | 92.3 | 91.3 | 70.4 | 93.2 | 88.0 | 60.6 | 90.0 |
| XLNET | 89.8 | 93.9 | 91.8 | 83.8 | 95.6 | 89.2 | 63.6 | 91.8 |
¿Cómo se benefició XLNet de los modelos de auto-regresión y codificación automática?
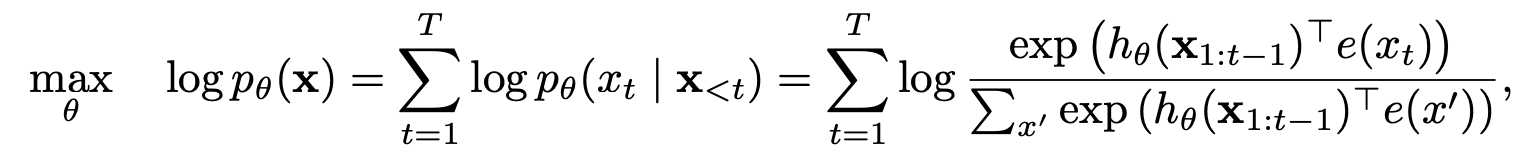
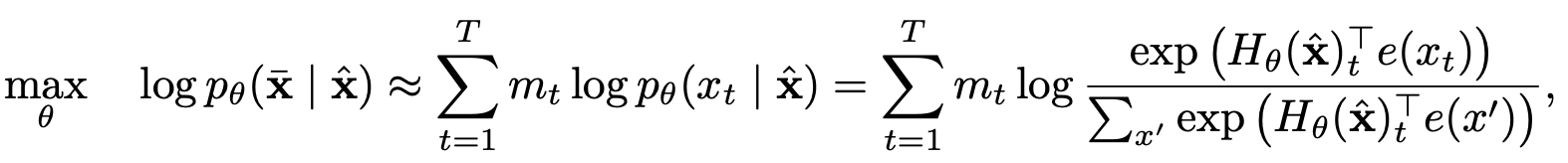
Modelado de lenguaje de permutación con predicción parcial
Modelado de idiomas de permutación 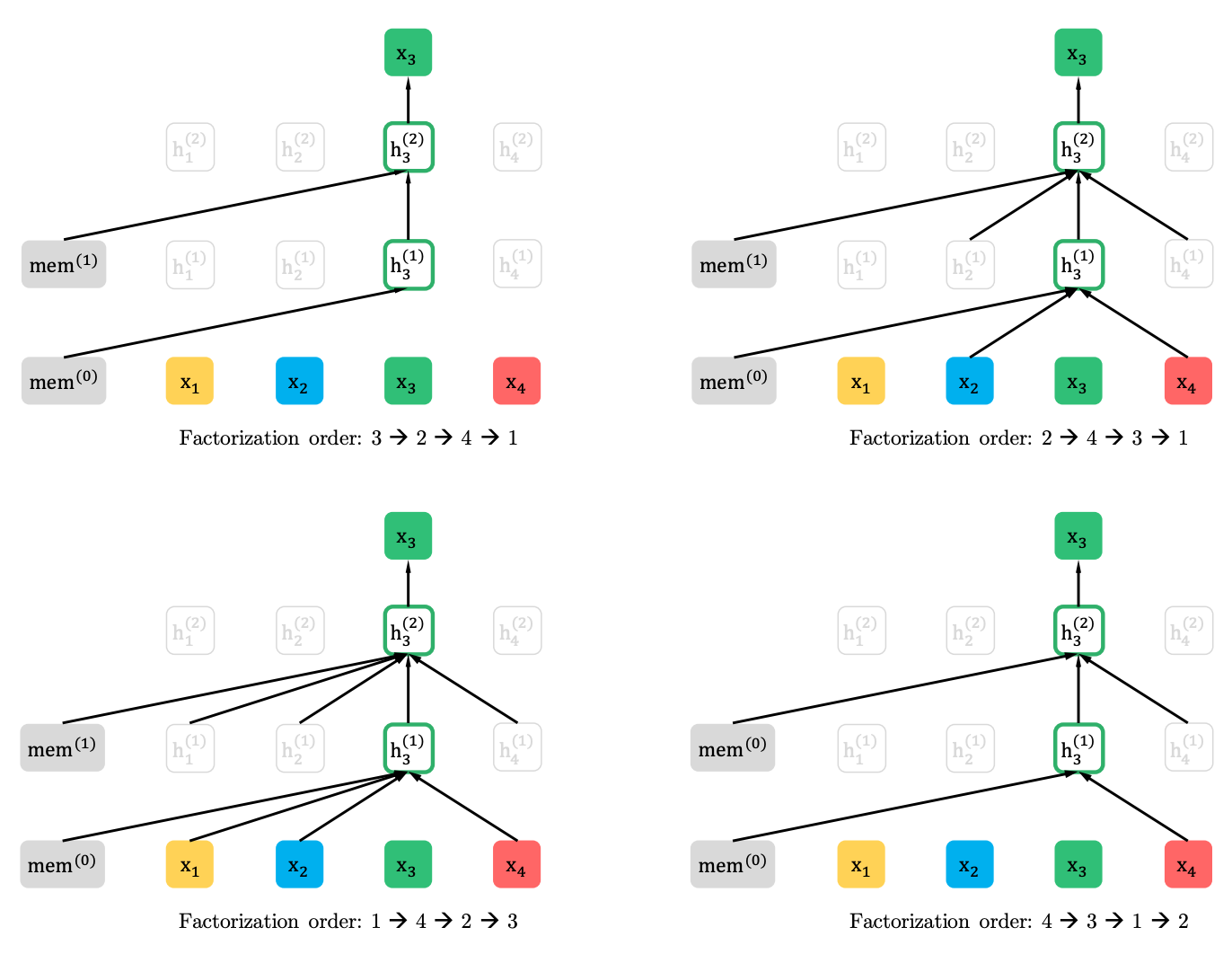
Predicción parcial 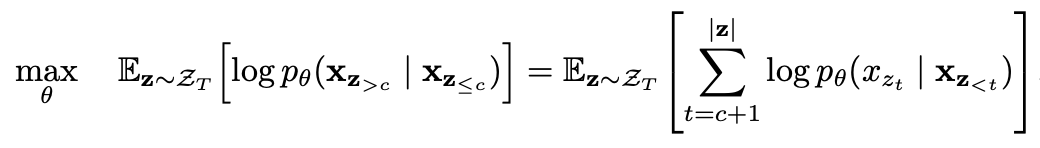
Autoatención de dos transmisiones con representación de objetivo
Autoatención de dos huellas
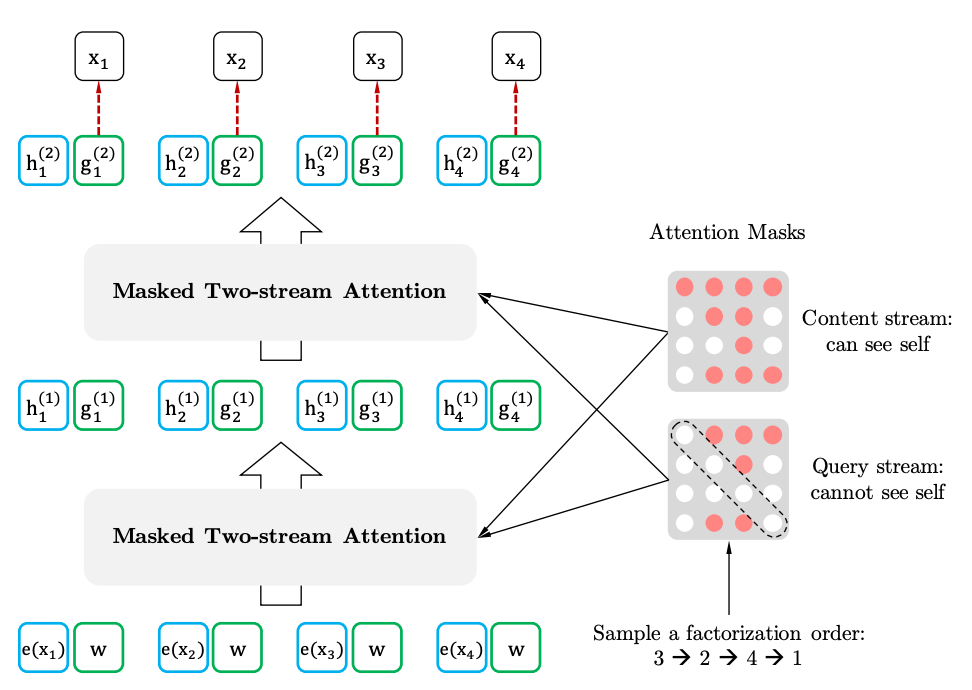
Representación del objetivo