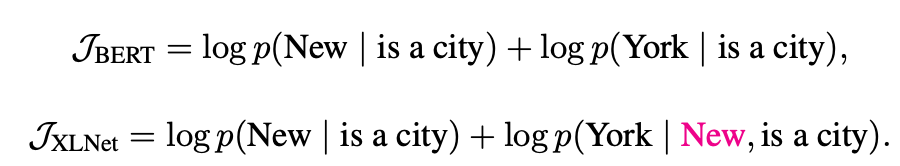xlnet Pytorch
1.0.0
Pytorch 래퍼가있는 간단한 XLNET 구현!
$ git clone https://github.com/graykode/xlnet-Pytorch && cd xlnet-Pytorch
# To use Sentence Piece Tokenizer(pretrained-BERT Tokenizer)
$ pip install pytorch_pretrained_bert
$ python main.py --data ./data.txt --tokenizer bert-base-uncased
--seq_len 512 --reuse_len 256 --perm_size 256
--bi_data True --mask_alpha 6 --mask_beta 1
--num_predict 85 --mem_len 384 --num_epoch 100또한 Google Colab에서 코드를 쉽게 실행할 수 있습니다.
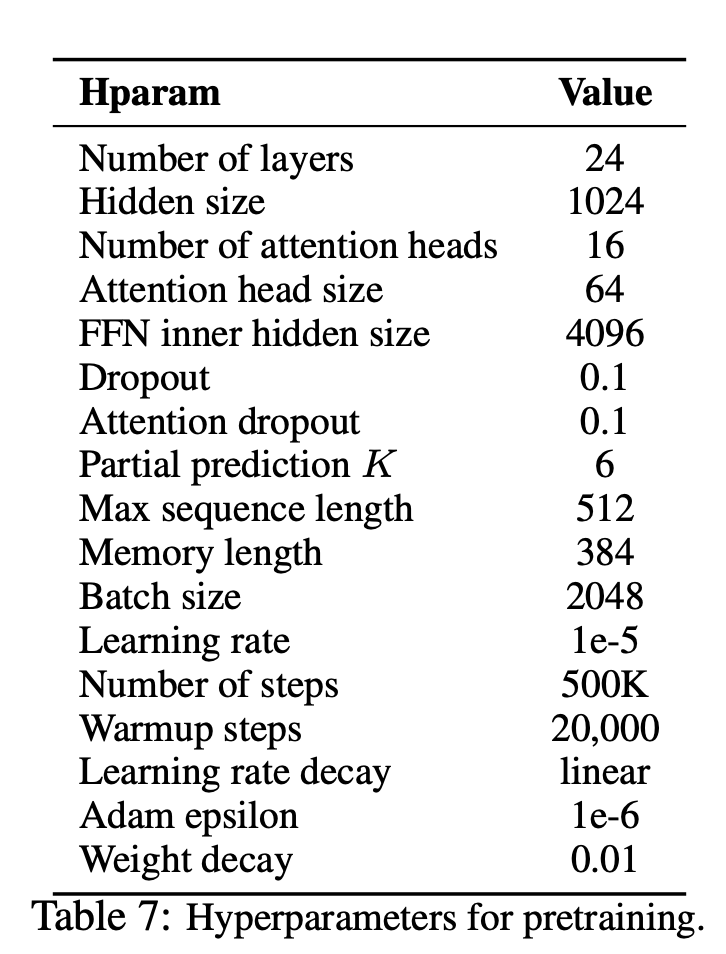
—data (string) : .txt 파일을 훈련합니다. 멀티 린 텍스트는 중요하지 않습니다. 또한 하나의 파일은 하나의 배치 텐서입니다. 기본값 : data.txt
—tokenizer (String) : 방금 Huggingface/Pytorch-Prestrained-Bert 's Tokenizer를 서브 워드 Tokenizer로 사용했습니다 (곧 문장 조각으로 편집 할 것입니다). bert-base-uncased , bert-large-uncased , bert-base-cased , bert-large-cased 로 선택할 수 있습니다. 기본값 : bert-base-uncased
—seq_len (정수) : 시퀀스 길이. 기본값 : 512
—reuse_len (interger) : 메모리로 재사용 할 수있는 토큰 수. seq_len 의 절반이 될 수 있습니다. 기본값 : 256
—perm_size (interger) : 가장 긴 순열의 길이. Reuse_len으로 설정할 수 있습니다. 기본값 : 256
--bi_data (부울) : 양방향 데이터 생성 여부. bi_data 가 True 인 경우 biz(batch size) 짝수가되어야합니다. 기본값 : False
—mask_alpha (Interger) : 그룹을 형성하기 위해 얼마나 많은 토큰이. Defalut : 6
—mask_beta (정수) : 각 그룹 내에서 마스크 할 토큰 수. 기본값 : 1
—num_predict (Interger) : 예측할 토큰의 수. 종이에서는 부분 예측을 의미합니다. 기본값 : 85
—mem_len (Interger) : Transformer-XL 아키텍처에서 캐시를위한 단계 수. 기본값 : 384
—num_epoch (interger) : 에포크 수. 기본값 : 100
XLNET 은 새로운 일반적인 순열 언어 모델링 목표를 기반으로 한 새로운 비 감독 언어 표현 학습 방법입니다. 또한 XLNET은 트랜스포머 -XL을 백본 모델로 사용하여 긴 컨텍스트와 관련된 언어 작업에 대한 우수한 성능을 보여줍니다.
| 모델 | mnli | qnli | QQP | RTE | SST-2 | MRPC | 콜라 | STS-B |
|---|---|---|---|---|---|---|---|---|
| 버트 | 86.6 | 92.3 | 91.3 | 70.4 | 93.2 | 88.0 | 60.6 | 90.0 |
| xlnet | 89.8 | 93.9 | 91.8 | 83.8 | 95.6 | 89.2 | 63.6 | 91.8 |
XLNET은 자동 회귀 및 자동 인코딩 모델로부터 어떻게 혜택을 받았습니까?
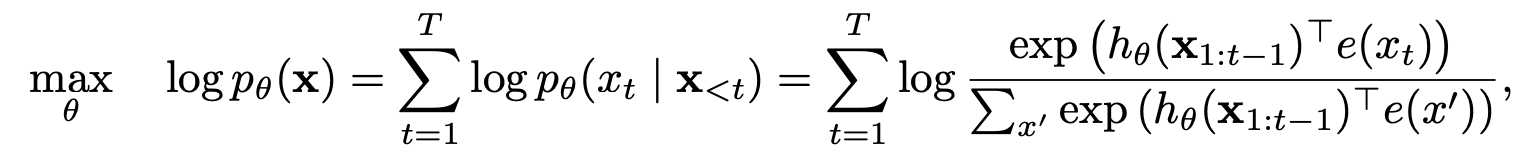
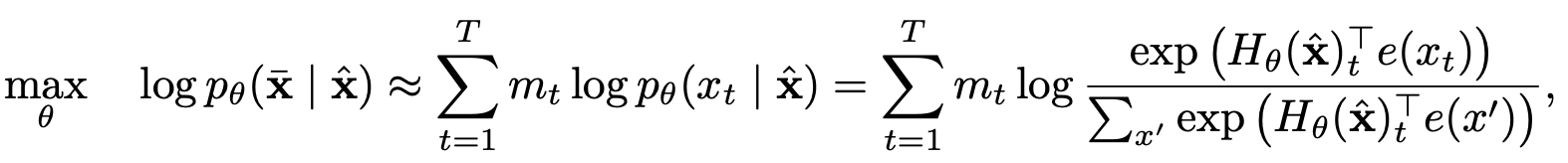
부분 예측을 가진 순열 언어 모델링
순열 언어 모델링 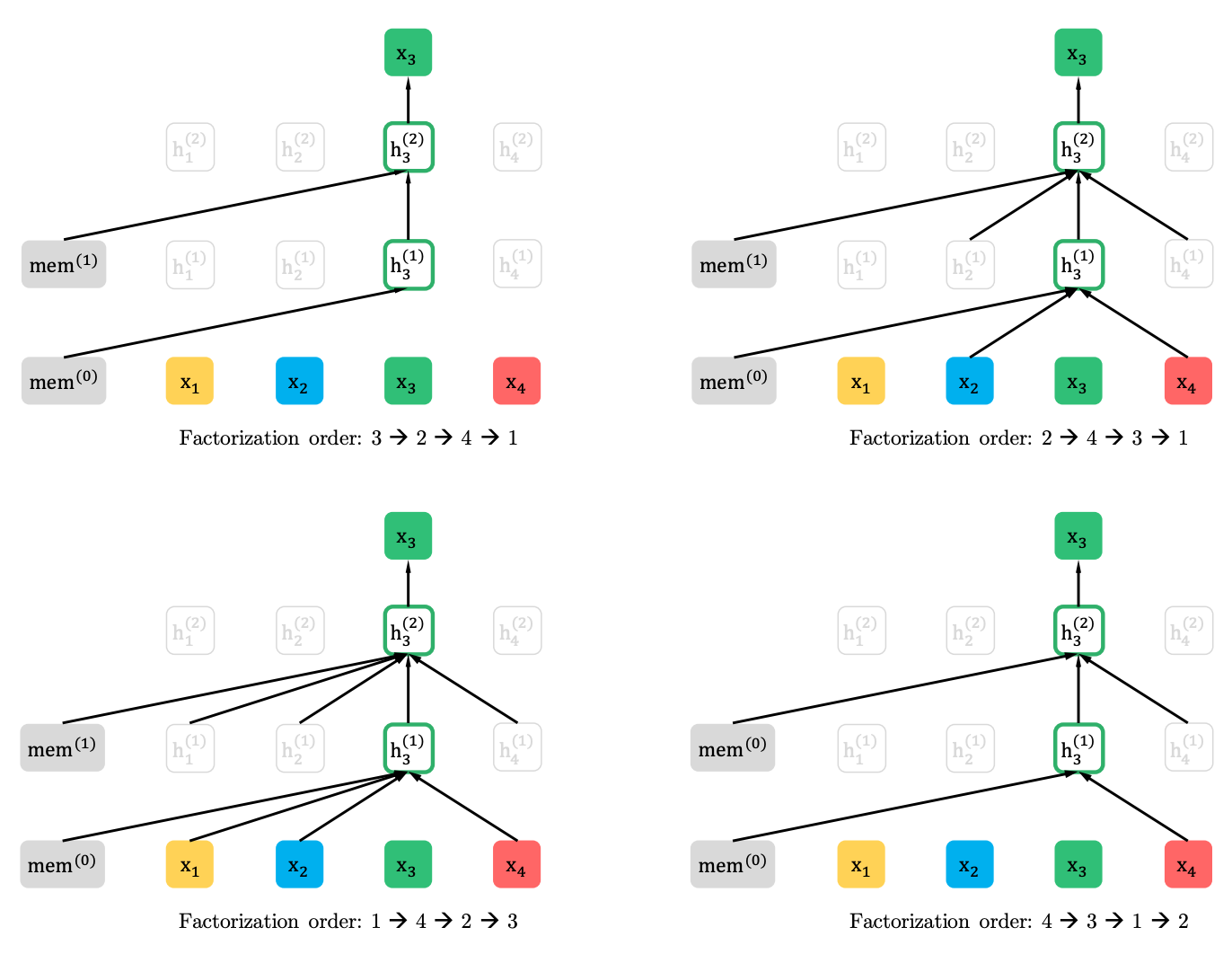
부분 예측 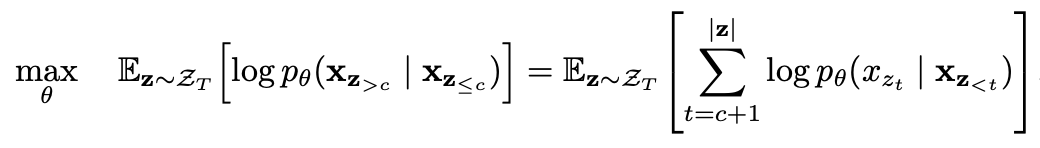
목표 인식 표현을 통한 2 스트림 자체 변환
2 스트램 자체 소지
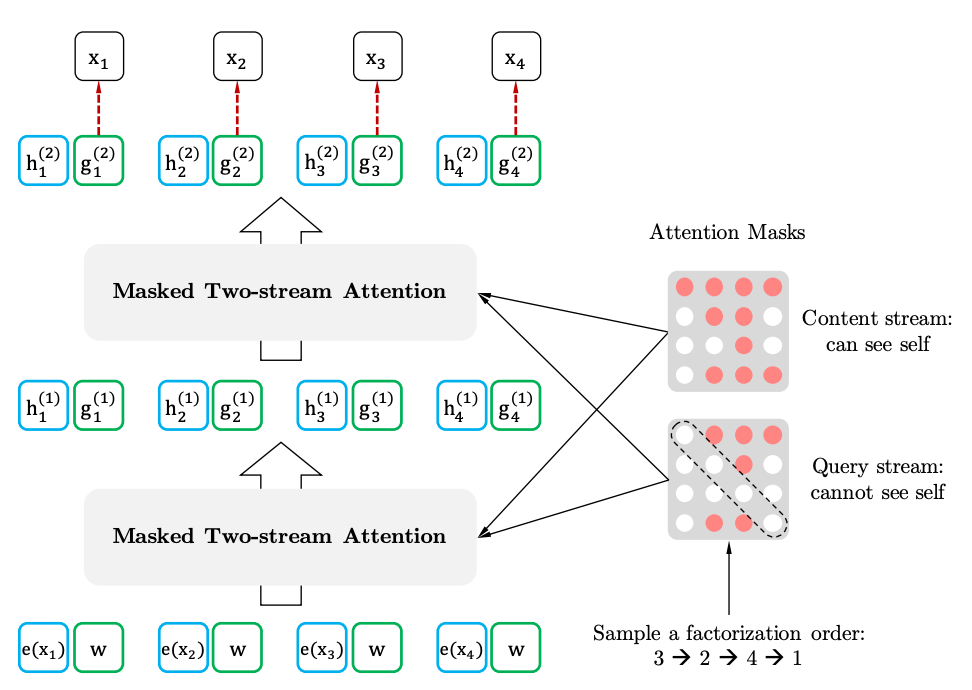
목표 인식 대표