xlnet Pytorch
1.0.0
การใช้งาน XLNET อย่างง่ายด้วย wrapper pytorch!
$ git clone https://github.com/graykode/xlnet-Pytorch && cd xlnet-Pytorch
# To use Sentence Piece Tokenizer(pretrained-BERT Tokenizer)
$ pip install pytorch_pretrained_bert
$ python main.py --data ./data.txt --tokenizer bert-base-uncased
--seq_len 512 --reuse_len 256 --perm_size 256
--bi_data True --mask_alpha 6 --mask_beta 1
--num_predict 85 --mem_len 384 --num_epoch 100นอกจากนี้คุณสามารถเรียกใช้รหัสใน Google Colab ได้อย่างง่ายดาย
—data (สตริง):. .txt ไฟล์เพื่อฝึกอบรม มันไม่สำคัญว่าข้อความหลายเส้น นอกจากนี้ไฟล์หนึ่งไฟล์จะเป็นหนึ่งชุดเทนเซอร์ ค่าเริ่มต้น: data.txt
—tokenizer (String): ฉันเพิ่งใช้ huggingface/pytorch-pretrained-tokenizer ของ Bert เป็น subword tokenizer (ฉันจะแก้ไขเป็นชิ้นส่วนประโยคเร็ว ๆ นี้) คุณสามารถเลือกได้ใน bert-base-uncased , bert-large-uncased , bert-base-cased , bert-large-cased ค่าเริ่มต้น: bert-base-uncased
—seq_len (จำนวนเต็ม): ความยาวลำดับ ค่าเริ่มต้น: 512
—reuse_len (interger): จำนวนโทเค็นที่สามารถนำกลับมาใช้ใหม่เป็นหน่วยความจำ อาจเป็นครึ่งหนึ่งของ seq_len ค่าเริ่มต้น: 256
—perm_size (Interger): ความยาวของการเปลี่ยนแปลงที่ยาวที่สุด สามารถตั้งค่าให้เป็น reuse_len ค่าเริ่มต้น: 256
--bi_data (บูลีน): ไม่ว่าจะสร้างข้อมูลแบบสองทิศทางหรือไม่ หาก bi_data เป็น True biz(batch size) ควรเป็นจำนวน ค่าเริ่มต้น: False
—mask_alpha (Interger): จำนวนโทเค็นในการสร้างกลุ่ม defalut: 6
—mask_beta (จำนวนเต็ม): มีโทเค็นจำนวนเท่าใดที่จะหน้ากากภายในแต่ละกลุ่ม ค่าเริ่มต้น: 1
—num_predict (Interger): จำนวนโทเค็นที่จะทำนาย ในกระดาษมันหมายถึงการทำนายบางส่วน ค่าเริ่มต้น: 85
—mem_len (Interger): จำนวนขั้นตอนในการแคชในสถาปัตยกรรม Transformer-XL ค่าเริ่มต้น: 384
—num_epoch (Interger): จำนวนยุค ค่าเริ่มต้น: 100
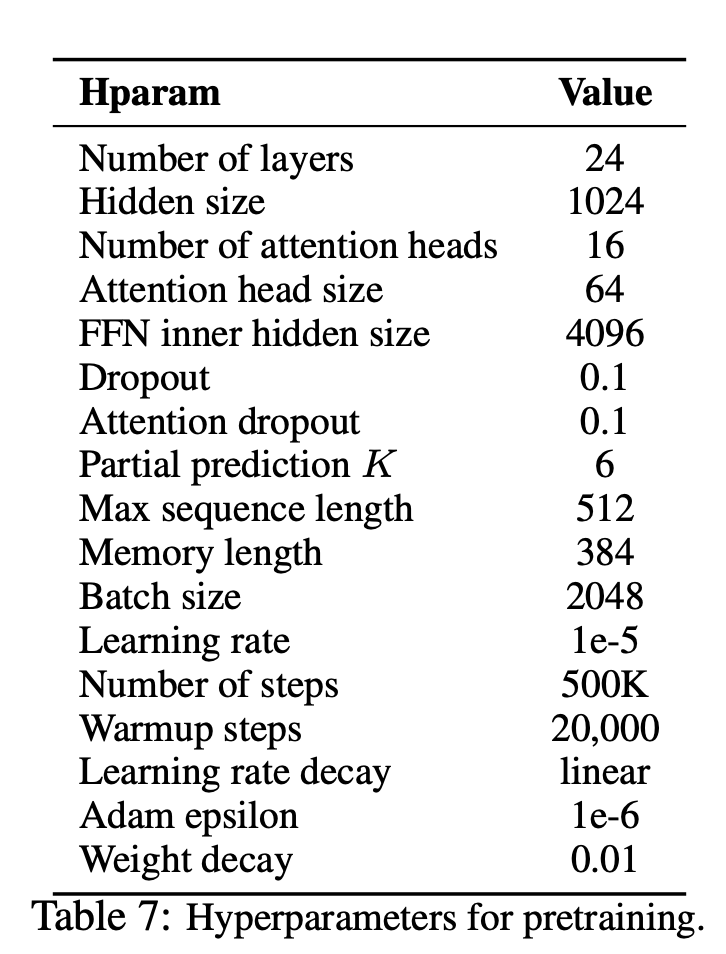
XLNET เป็นวิธีการเรียนรู้การเป็นตัวแทนภาษาที่ไม่ได้รับการดูแลใหม่โดยใช้วัตถุประสงค์การสร้างแบบจำลองภาษาการเปลี่ยนแปลงทั่วไปแบบใหม่ นอกจากนี้ XLNET ยังใช้ Transformer-XL เป็นโมเดล Backbone ซึ่งแสดงประสิทธิภาพที่ยอดเยี่ยมสำหรับงานภาษาที่เกี่ยวข้องกับบริบทที่ยาวนาน
| แบบอย่าง | mnli | qnli | qqp | rte | SST-2 | MRPC | โคล่า | STS-B |
|---|---|---|---|---|---|---|---|---|
| เบิร์ต | 86.6 | 92.3 | 91.3 | 70.4 | 93.2 | 88.0 | 60.6 | 90.0 |
| xlnet | 89.8 | 93.9 | 91.8 | 83.8 | 95.6 | 89.2 | 63.6 | 91.8 |
XLNet ได้รับประโยชน์จากโมเดลการถดถอยอัตโนมัติและการเข้ารหัสอัตโนมัติอย่างไร
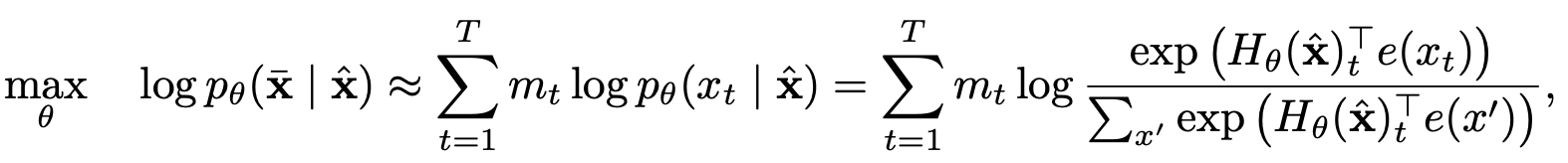
การสร้างแบบจำลองภาษาแบบเปลี่ยนรูปด้วยการทำนายบางส่วน
การสร้างแบบจำลองภาษาแบบเปลี่ยนรูป 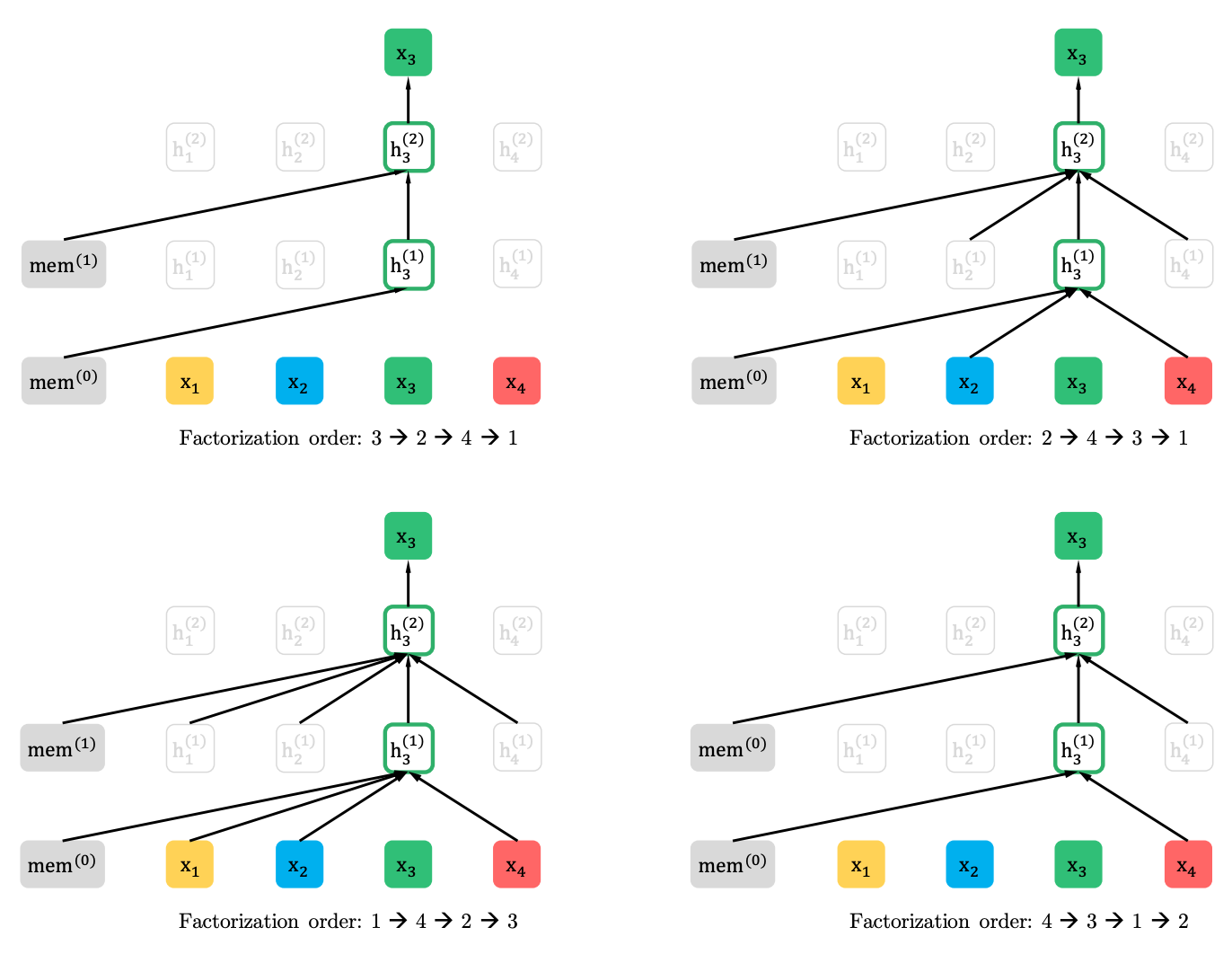
การทำนายบางส่วน 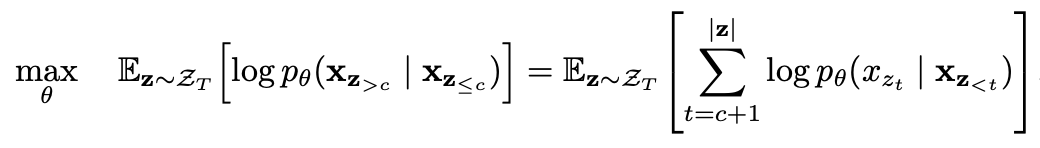
การตั้งใจด้วยตนเองสองสตรีมด้วยการเป็นตัวแทนที่ตระหนักถึงเป้าหมาย
ความตั้งใจของตนเองสองสเตรต
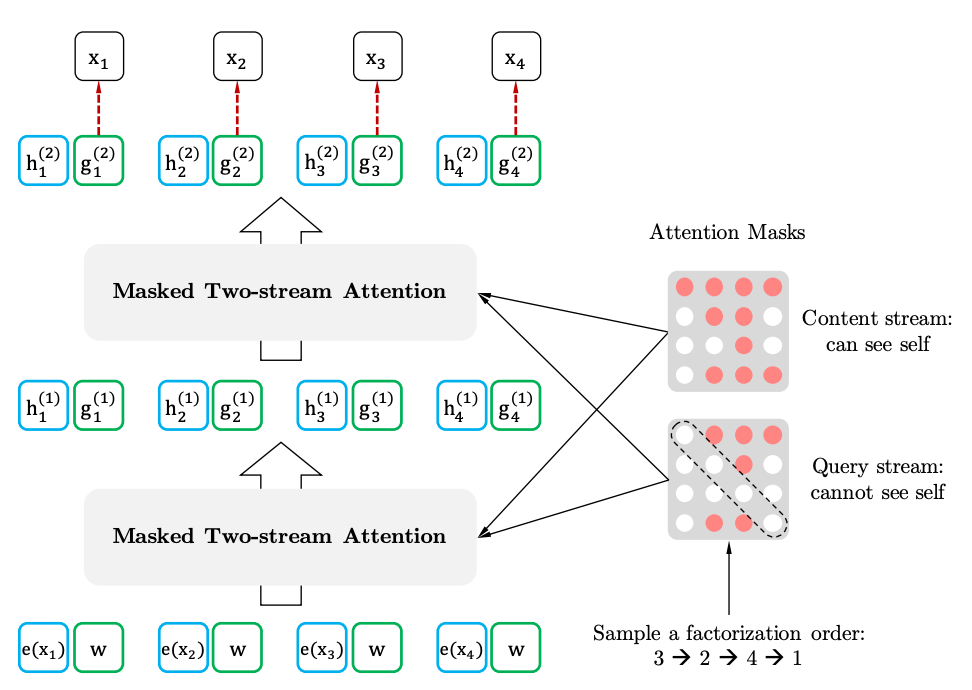
การเป็นตัวแทนที่ตระหนักถึงเป้าหมาย