xlnet Pytorch
1.0.0
带有Pytorch包装器的简单XLNET实现!
$ git clone https://github.com/graykode/xlnet-Pytorch && cd xlnet-Pytorch
# To use Sentence Piece Tokenizer(pretrained-BERT Tokenizer)
$ pip install pytorch_pretrained_bert
$ python main.py --data ./data.txt --tokenizer bert-base-uncased
--seq_len 512 --reuse_len 256 --perm_size 256
--bi_data True --mask_alpha 6 --mask_beta 1
--num_predict 85 --mem_len 384 --num_epoch 100另外,您可以轻松地在Google Colab中运行代码。
—data (字符串):要训练的.txt文件。多行文本无关紧要。另外,一个文件将是一个批量张量。默认值: data.txt
—tokenizer (字符串):我只是使用huggingface/pytorch-pretretain-bert的令牌作为子字令牌(我会尽快将其编辑为句子)。您可以选择基于bert-base-uncased bert-large-uncased unge, bert-base-cased , bert-large-cased 。默认值: bert-base-uncased
—seq_len (整数):序列长度。默认值: 512
—reuse_len (Interger):可以重复使用的令牌数量。可能是seq_len的一半。默认值: 256
—perm_size (Interger):最长置换的长度。可以设置为reuse_len。默认值: 256
--bi_data (布尔值):是否创建双向数据。如果bi_data为True , biz(batch size)应为数字。默认值: False
—mask_alpha (Interger):形成一个组有多少个令牌。 Defalut: 6
—mask_beta (整数):每个组内掩盖多少个令牌。默认值: 1
—num_predict (Interger):要预测的代币数字。在纸上,这意味着部分预测。默认值: 85
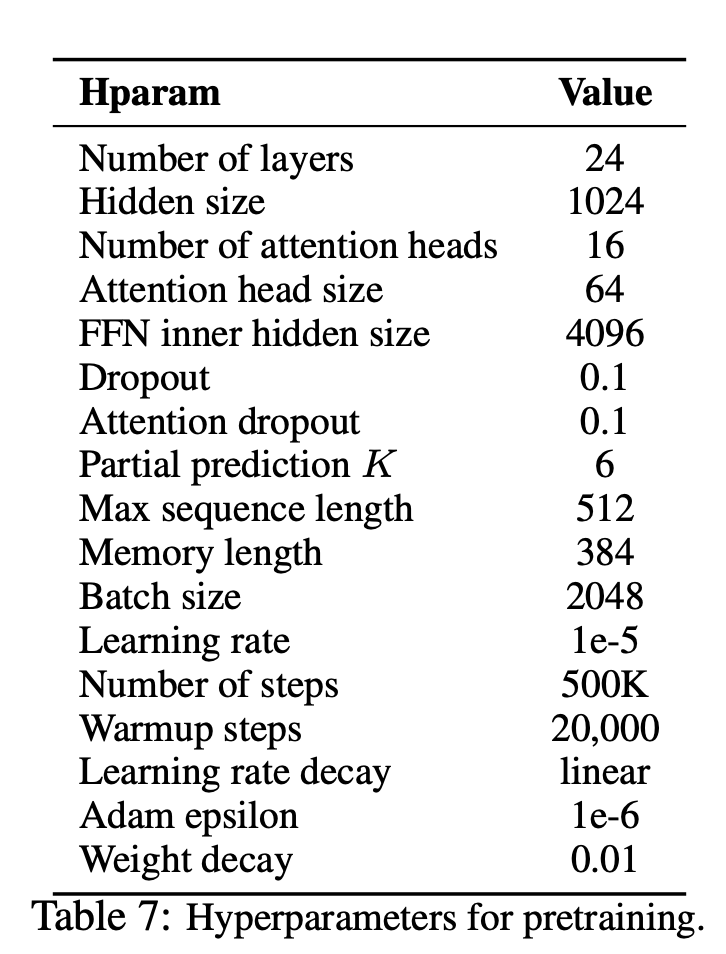
—mem_len (Interger):在变压器-XL体系结构中缓存的步骤数。默认值: 384
—num_epoch (Interger):时期数。默认值: 100
XLNET是一种基于新颖的广义置换语言建模目标的新的无监督语言表示学习方法。此外,XLNET还采用Transformer-XL作为骨干模型,在涉及长篇小说的语言任务方面表现出色。
| 模型 | mnli | Qnli | QQP | rte | SST-2 | MRPC | 可乐 | STS-B |
|---|---|---|---|---|---|---|---|---|
| 伯特 | 86.6 | 92.3 | 91.3 | 70.4 | 93.2 | 88.0 | 60.6 | 90.0 |
| xlnet | 89.8 | 93.9 | 91.8 | 83.8 | 95.6 | 89.2 | 63.6 | 91.8 |
XLNet如何从自动回归和自动编码模型中受益?
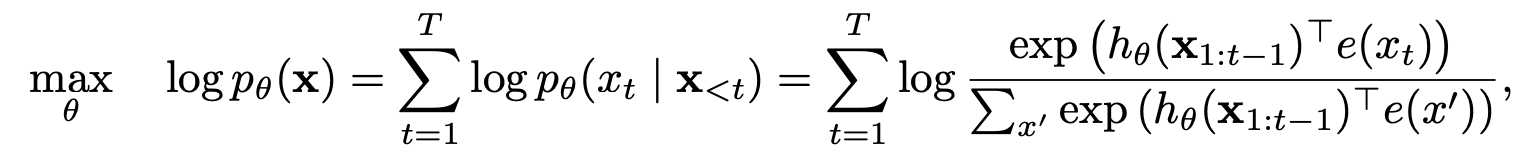
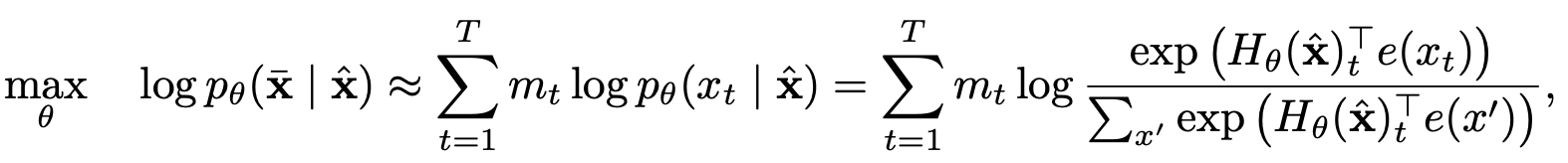
置换语言建模与部分预测
置换语言建模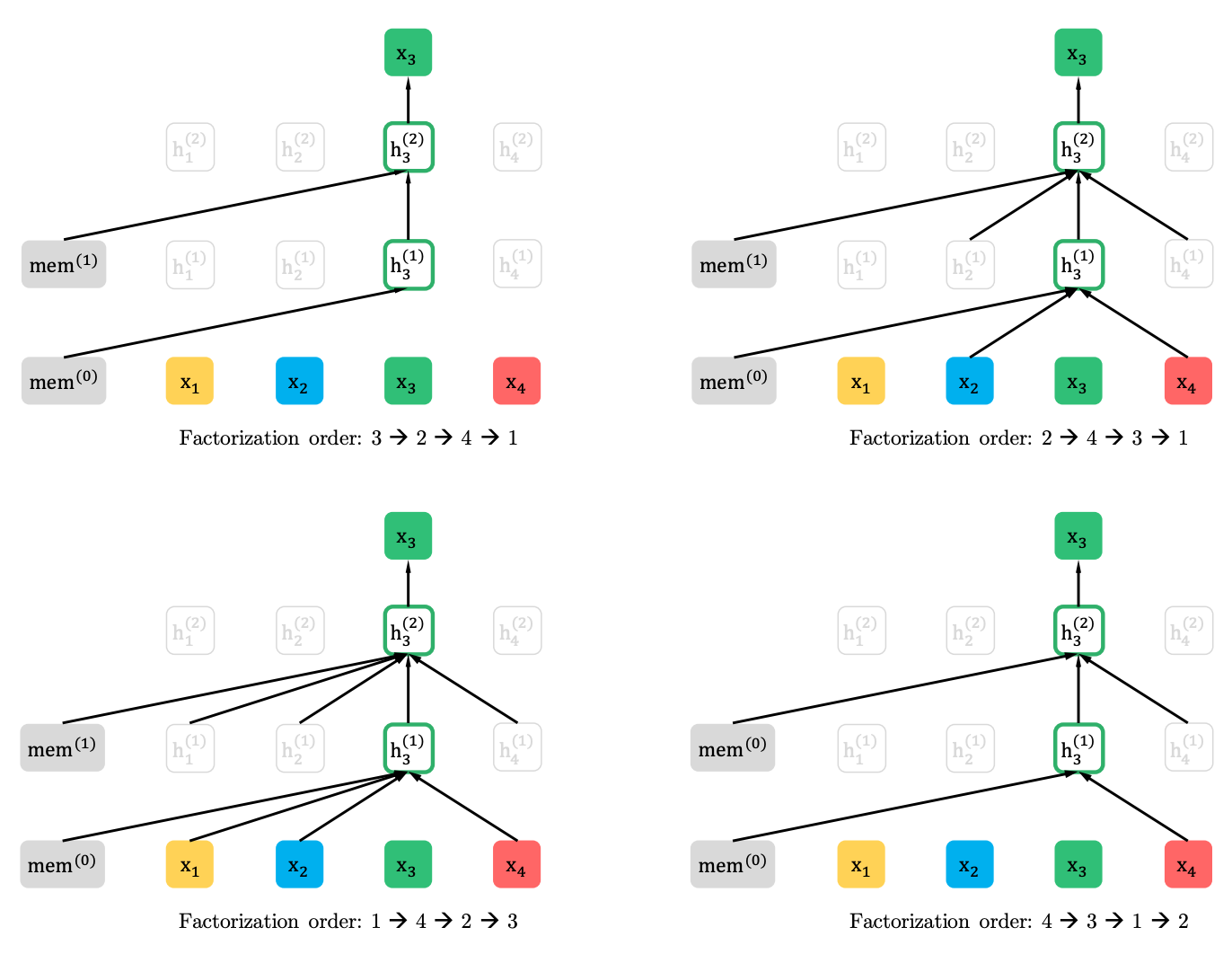
部分预测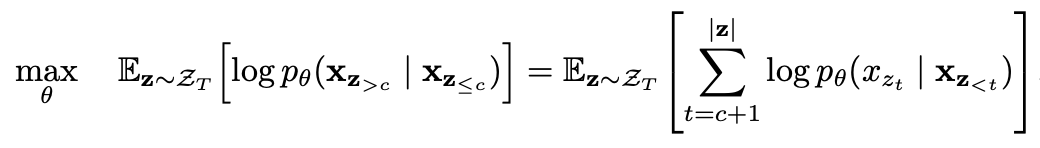
具有目标感知代表的两流自我注意
两史的自我注意力
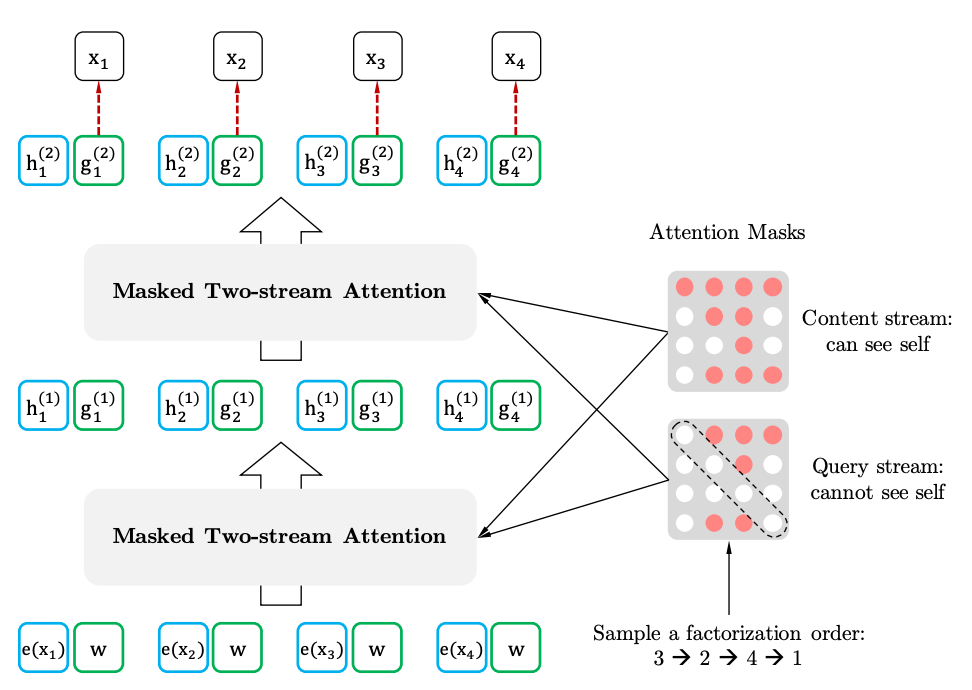
目标感知表示