xlnet Pytorch
1.0.0
Implementasi XLNET Sederhana dengan Pembungkus Pytorch!
$ git clone https://github.com/graykode/xlnet-Pytorch && cd xlnet-Pytorch
# To use Sentence Piece Tokenizer(pretrained-BERT Tokenizer)
$ pip install pytorch_pretrained_bert
$ python main.py --data ./data.txt --tokenizer bert-base-uncased
--seq_len 512 --reuse_len 256 --perm_size 256
--bi_data True --mask_alpha 6 --mask_beta 1
--num_predict 85 --mem_len 384 --num_epoch 100Anda juga dapat menjalankan kode di Google Colab dengan mudah.
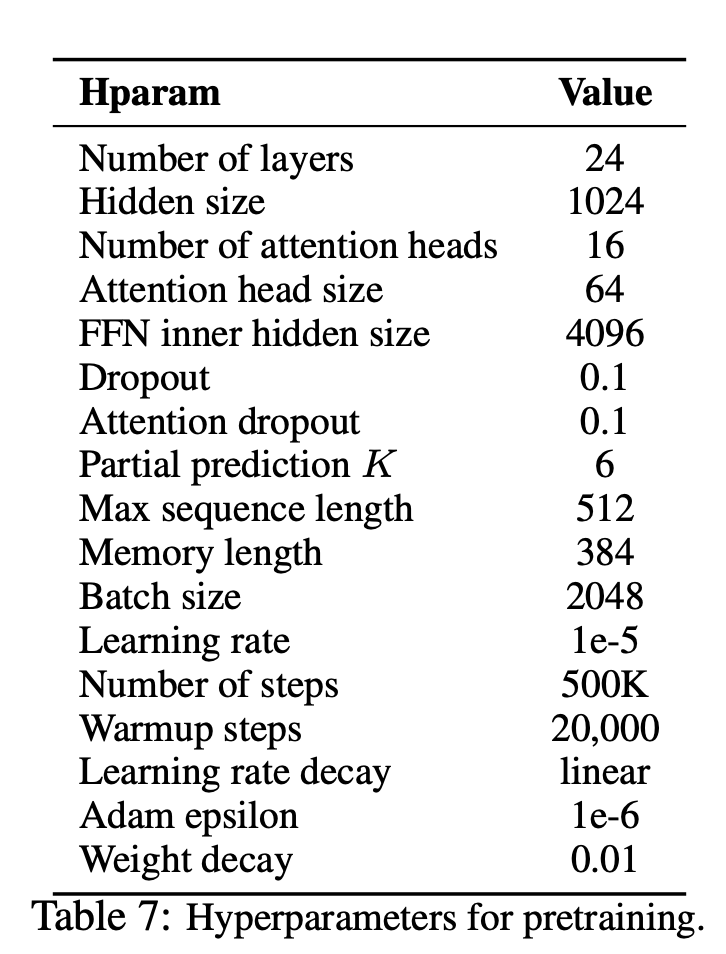
—data (String): .txt file untuk melatih. Tidak masalah teks multiline. Juga, satu file akan menjadi satu tensor batch. Default: data.txt
—tokenizer (string): Saya baru saja menggunakan tokenizer HuggingFace/Pytorch-Pretrained-Bert sebagai Tokenizer Subword (saya akan segera mengeditnya ke Kalimat). Anda dapat memilih dalam bert-base-uncased , bert-large-uncased , bert-base-cased , bert-large-cased . Default: bert-base-uncased
—seq_len (integer): Panjang urutan. Default: 512
—reuse_len (Interger): Jumlah token yang dapat digunakan kembali sebagai memori. Bisa setengah dari seq_len . Default: 256
—perm_size (Interger): Panjang permutasi terpanjang. Bisa diatur untuk reuse_len. Default: 256
--bi_data (BOOLEAN): Apakah akan membuat data dua arah. Jika bi_data True , biz(batch size) harus menjadi angka genap. Default: False
—mask_alpha (Interger): Berapa banyak token yang membentuk grup. Defalut: 6
—mask_beta (integer): Berapa banyak token untuk menutupi dalam setiap kelompok. Default: 1
—num_predict (Interger): BUM TOKEN untuk memprediksi. Dalam kertas, itu berarti prediksi parsial. Default: 85
—mem_len (Interger): Jumlah langkah untuk cache dalam arsitektur transformer-xl. Default: 384
—num_epoch (Interger): Jumlah zaman. Default: 100
XLNET adalah metode pembelajaran representasi bahasa baru tanpa pengawasan berdasarkan pada tujuan pemodelan bahasa permutasi umum baru. Selain itu, XLNET menggunakan Transformer-XL sebagai model backbone, menunjukkan kinerja yang sangat baik untuk tugas-tugas bahasa yang melibatkan konteks yang panjang.
| Model | Mnli | Qnli | QQP | Rte | SST-2 | Mrpc | Cola | STS-B |
|---|---|---|---|---|---|---|---|---|
| Bert | 86.6 | 92.3 | 91.3 | 70.4 | 93.2 | 88.0 | 60.6 | 90.0 |
| Xlnet | 89.8 | 93.9 | 91.8 | 83.8 | 95.6 | 89.2 | 63.6 | 91.8 |
Bagaimana XLNET mendapat manfaat dari model regresi otomatis dan pengkodean otomatis?
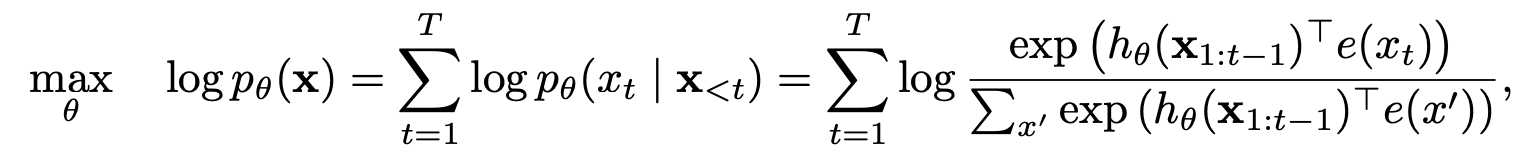
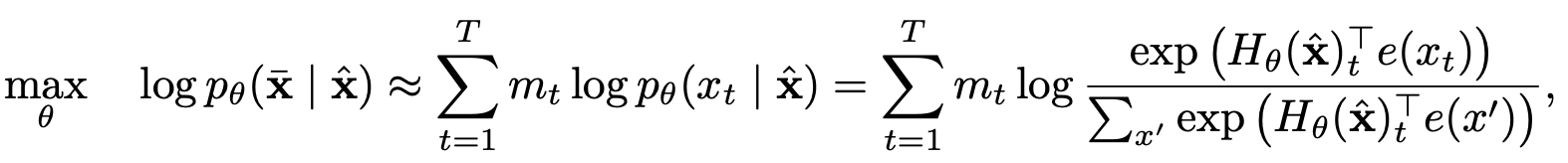
Pemodelan bahasa permutasi dengan prediksi parsial
Pemodelan Bahasa Permutasi 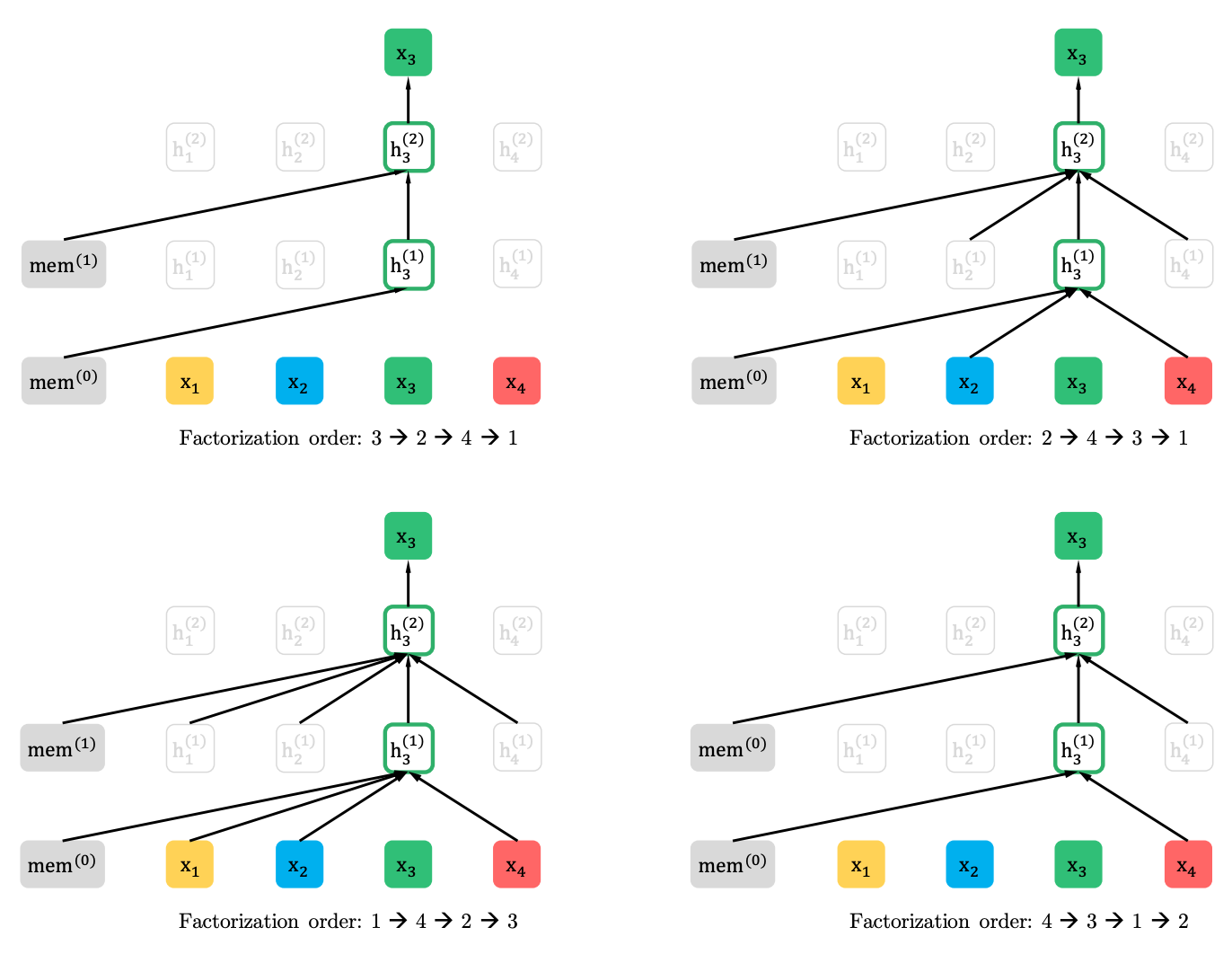
Prediksi parsial 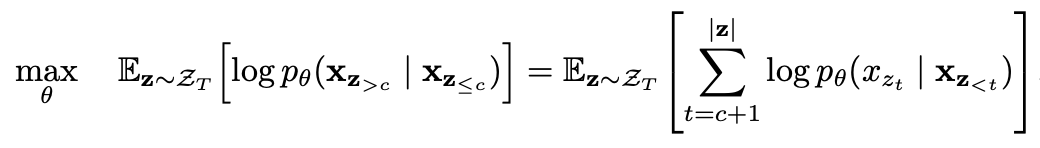
Perhatian diri dua aliran dengan representasi target-sadar
Perhatian diri sendiri
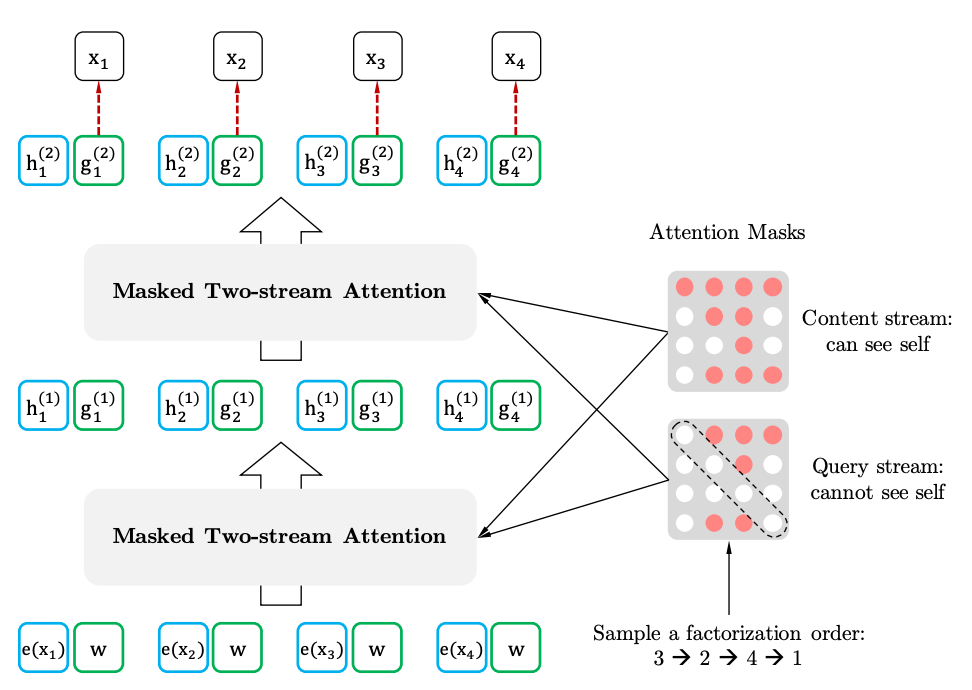
Representasi Target-Sadar