xlnet Pytorch
1.0.0
Pytorchラッパーを使用したシンプルなXLNET実装!
$ git clone https://github.com/graykode/xlnet-Pytorch && cd xlnet-Pytorch
# To use Sentence Piece Tokenizer(pretrained-BERT Tokenizer)
$ pip install pytorch_pretrained_bert
$ python main.py --data ./data.txt --tokenizer bert-base-uncased
--seq_len 512 --reuse_len 256 --perm_size 256
--bi_data True --mask_alpha 6 --mask_beta 1
--num_predict 85 --mem_len 384 --num_epoch 100また、Google Colabでコードを簡単に実行できます。
—data (String):. .txtファイルをトレーニングします。マルチラインテキストは問題ではありません。また、1つのファイルは1つのバッチテンソルになります。デフォルト: data.txt
—tokenizer (String):Huggingface/Pytorch-Preatreaded-Berteのトークンザーをサブワードトークイザーとして使用しました(すぐに文に編集します)。 bert-base-uncased 、 bert-large-uncased 、 bert-base-cased 、 bert-large-casedで選択できます。デフォルト: bert-base-uncased
—seq_len (整数):シーケンス長。デフォルト: 512
—reuse_len (Interger):メモリとして再利用できるトークンの数。 seq_lenの半分になる可能性があります。デフォルト: 256
—perm_size (Interger):最長の順列の長さ。 reuse_lenになるように設定できます。デフォルト: 256
--bi_data (boolean):双方向データを作成するかどうか。 bi_dataがTrueある場合、 biz(batch size)偶数でなければなりません。デフォルト: False
—mask_alpha (Interger):グループを形成するためのトークンの数。 defalut: 6
—mask_beta (整数):各グループ内でマスクするトークンの数。デフォルト: 1
—num_predict (Interger):予測するトークンの数。紙では、部分的な予測を意味します。デフォルト: 85
—mem_len (Interger):Transform-XLアーキテクチャでキャッシュするステップ数。デフォルト: 384
—num_epoch (Interger):エポックの数。デフォルト: 100
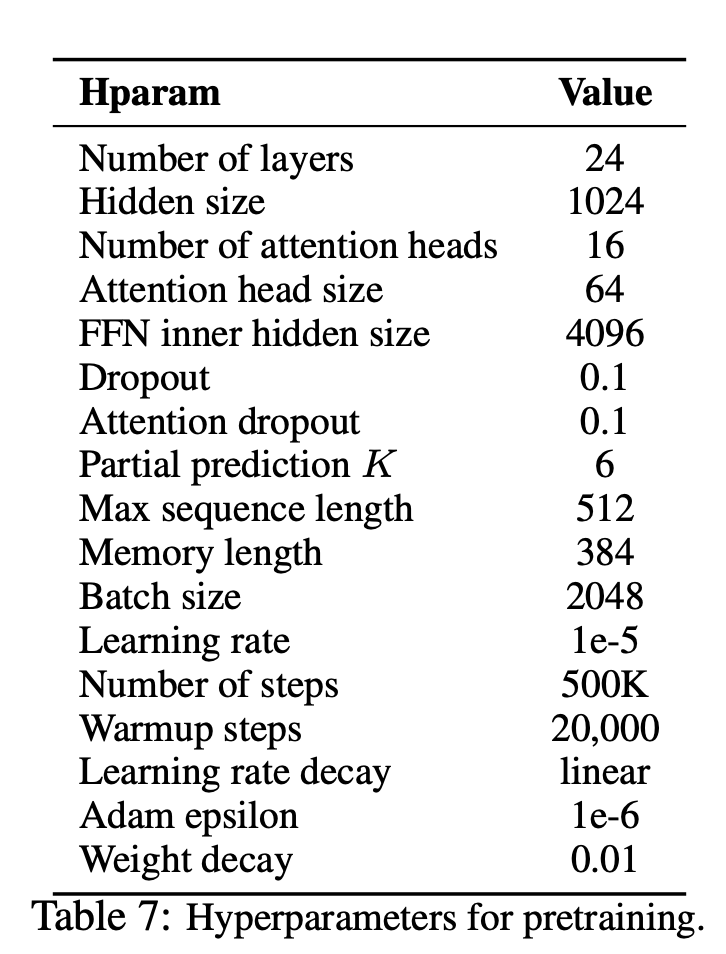
XLNETは、新しい一般化された順列言語モデリングの目的に基づいた新しい監視されていない言語表現学習方法です。さらに、XLNETはバックボーンモデルとしてTransformer-XLを採用しており、長いコンテキストを含む言語タスクに優れたパフォーマンスを示しています。
| モデル | mnli | Qnli | QQP | rte | SST-2 | MRPC | コーラ | sts-b |
|---|---|---|---|---|---|---|---|---|
| バート | 86.6 | 92.3 | 91.3 | 70.4 | 93.2 | 88.0 | 60.6 | 90.0 |
| xlnet | 89.8 | 93.9 | 91.8 | 83.8 | 95.6 | 89.2 | 63.6 | 91.8 |
XLNETは自動回帰モデルと自動エンコードモデルからどのように利益を得ましたか?
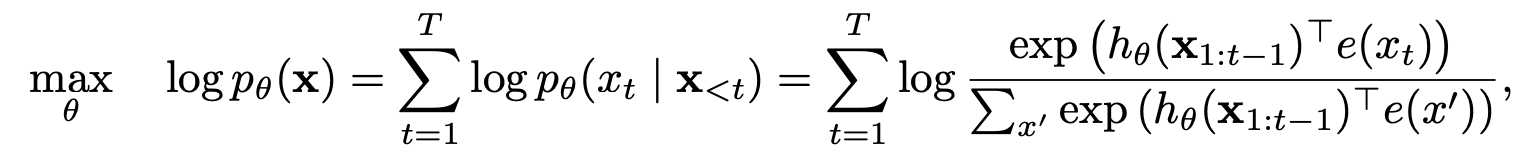
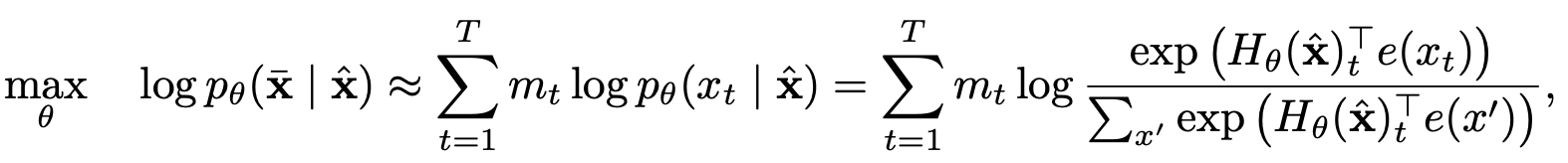
部分的な予測を伴う順列言語モデリング
順列言語モデリング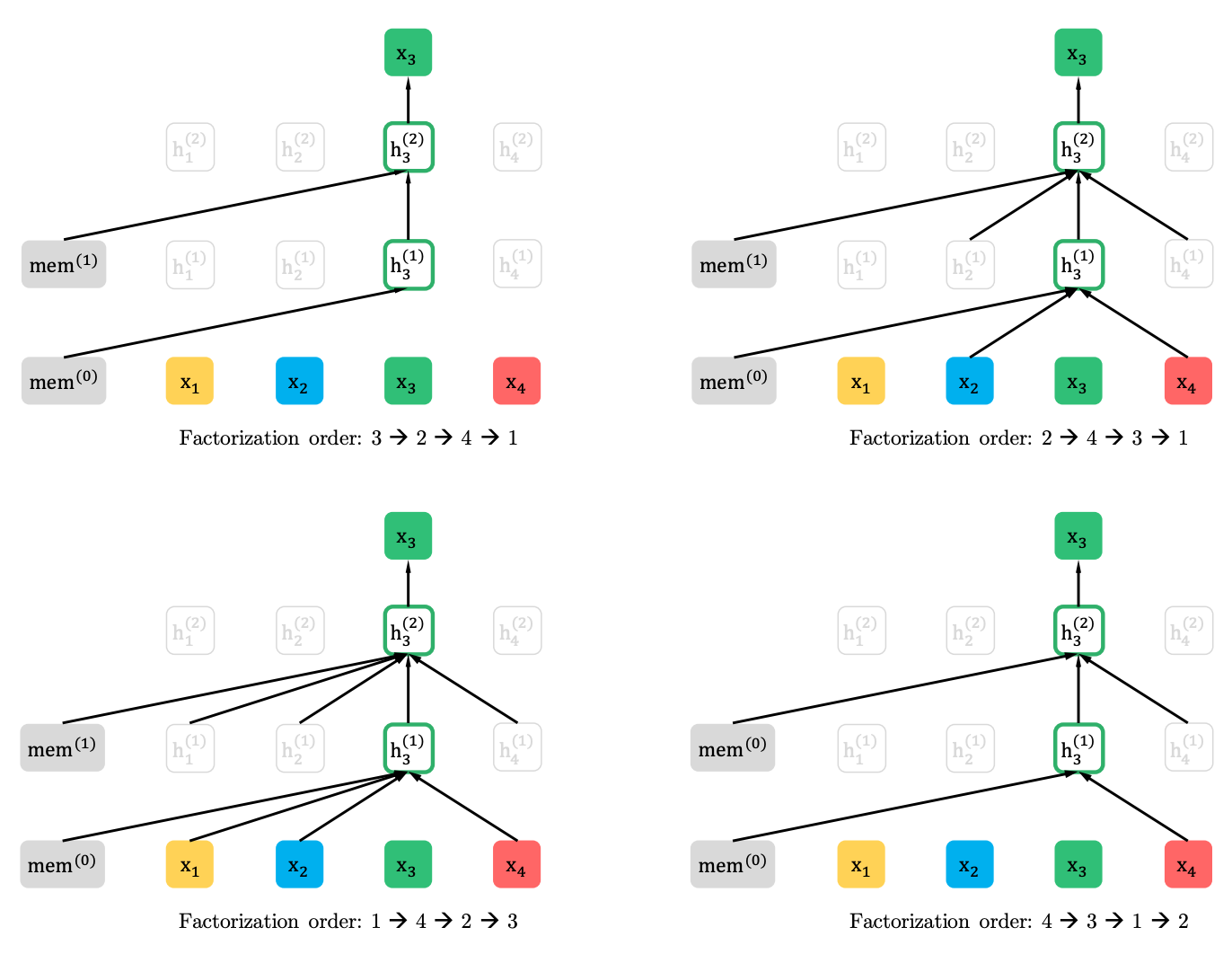
部分的な予測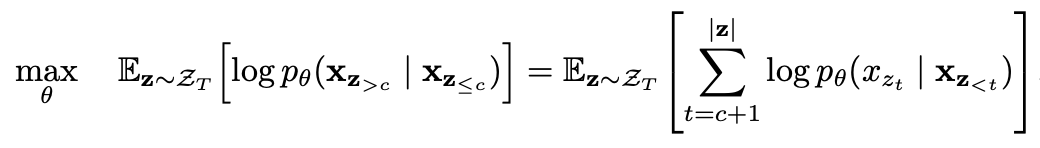
ターゲット認識表現を伴う2ストリームの自己関節
2 stramの自己告発
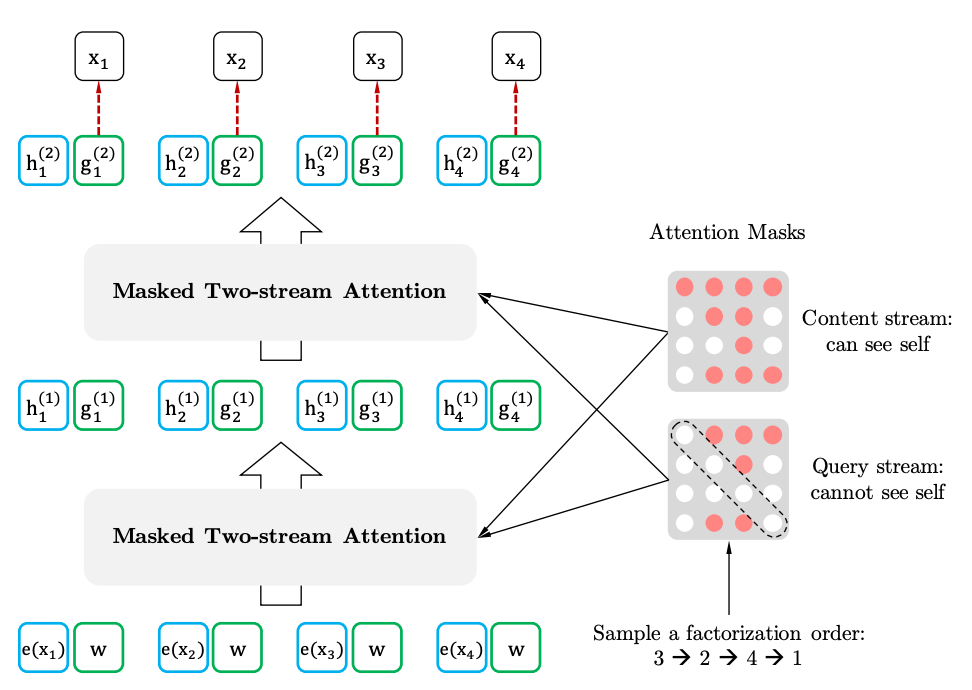
ターゲット認識表現