xlnet Pytorch
1.0.0
Простая реализация XLnet с Pytorch Orbper!
$ git clone https://github.com/graykode/xlnet-Pytorch && cd xlnet-Pytorch
# To use Sentence Piece Tokenizer(pretrained-BERT Tokenizer)
$ pip install pytorch_pretrained_bert
$ python main.py --data ./data.txt --tokenizer bert-base-uncased
--seq_len 512 --reuse_len 256 --perm_size 256
--bi_data True --mask_alpha 6 --mask_beta 1
--num_predict 85 --mem_len 384 --num_epoch 100Кроме того, вы можете легко запустить код в Google Colab.
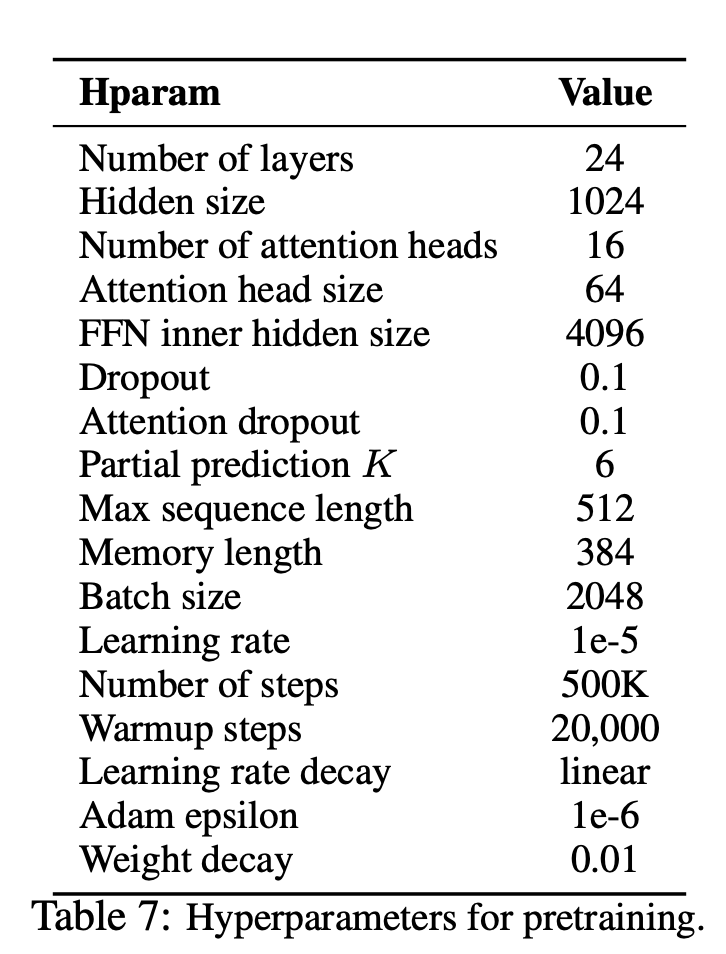
—data (String): .txt file для обучения. Это не имеет значения многослойного текста. Кроме того, один файл будет один тензор партии. По умолчанию: data.txt
—tokenizer (String): Я только что использовал токенизатор Huggingface/Pytorch, представленные в качестве токенизатора, в качестве токенизатора подрота (скоро его редактирую на предложение). Вы можете выбрать в bert-base-uncased , bert-large-uncased , bert-base-cased , bert-large-cased . По умолчанию: bert-base-uncased
—seq_len (целое число): длина последовательности. По умолчанию: 512
—reuse_len (интернет): количество токенов, которое можно повторно использовать как память. Может быть половина seq_len . По умолчанию: 256
—perm_size (Интерер): длина самой длинной перестановки. Может быть настроен на повторное использование_len. По умолчанию: 256
--bi_data (boolean): создавать двунаправленные данные. Если bi_data True , biz(batch size) должен быть равномерным. По умолчанию: False
—mask_alpha (Интерер): сколько жетонов сформировать группу. Defalut: 6
—mask_beta (целое число): сколько токенов маскировать в каждой группе. По умолчанию: 1
—num_predict (интернет): количество токенов, чтобы предсказать. В бумаге это означает частичный прогноз. По умолчанию: 85
—mem_len (интернет): количество шагов к кэшу в архитектуре Transformer-XL. По умолчанию: 384
—num_epoch (Интерер): количество эпохи. По умолчанию: 100
XLnet - это новый метод обучения языковым представлениям, основанный на неконтролируемом языке, основанный на новой целевой задаче моделирования языка перестановки. Кроме того, XLnet использует Transformer-XL в качестве модели магистра, демонстрируя отличную производительность для языковых задач, включающих длинный контекст.
| Модель | Mnli | Qnli | QQP | Rte | SST-2 | MRPC | Кола | STS-B |
|---|---|---|---|---|---|---|---|---|
| БЕРТ | 86.6 | 92.3 | 91.3 | 70.4 | 93.2 | 88.0 | 60.6 | 90.0 |
| Xlnet | 89,8 | 93,9 | 91.8 | 83,8 | 95,6 | 89,2 | 63,6 | 91.8 |
Как XLnet выиграл от моделей авто-регрессии и автосодирования?
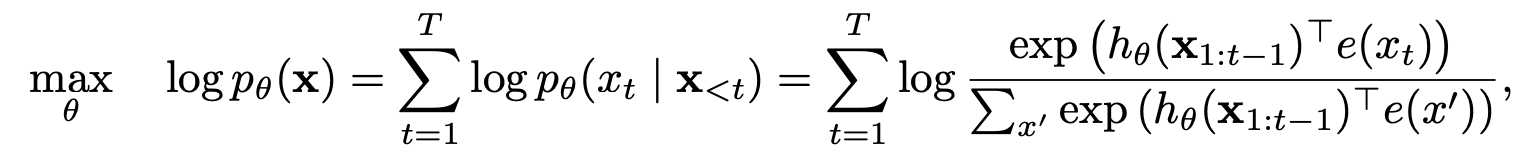
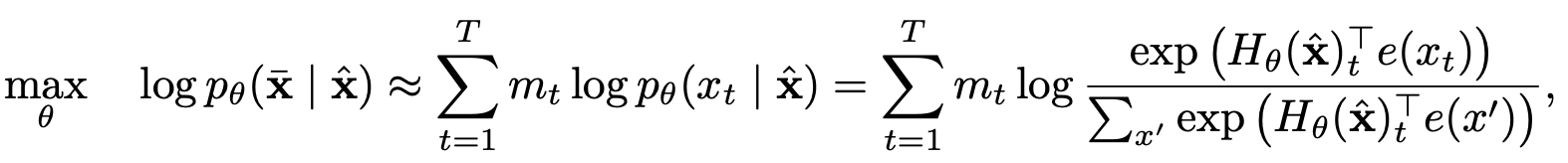
Моделирование языка перестановки с частичным прогнозом
Моделирование языка перестановки 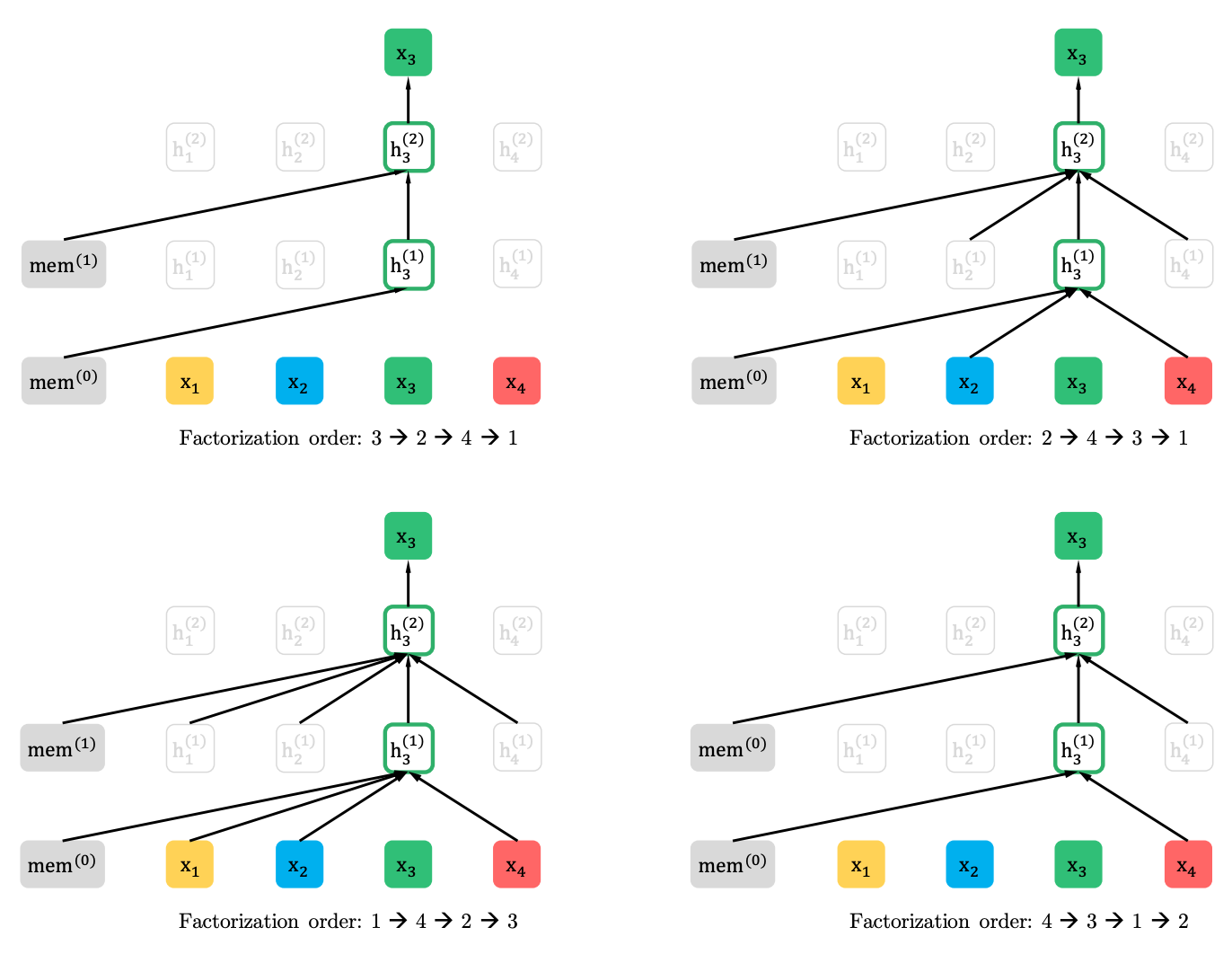
Частичное прогноз 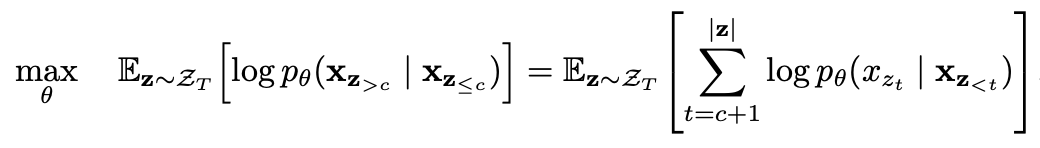
Двухстороннее самоуничтожение с представлением о целевом отношении
Двухстребительские самоубийства
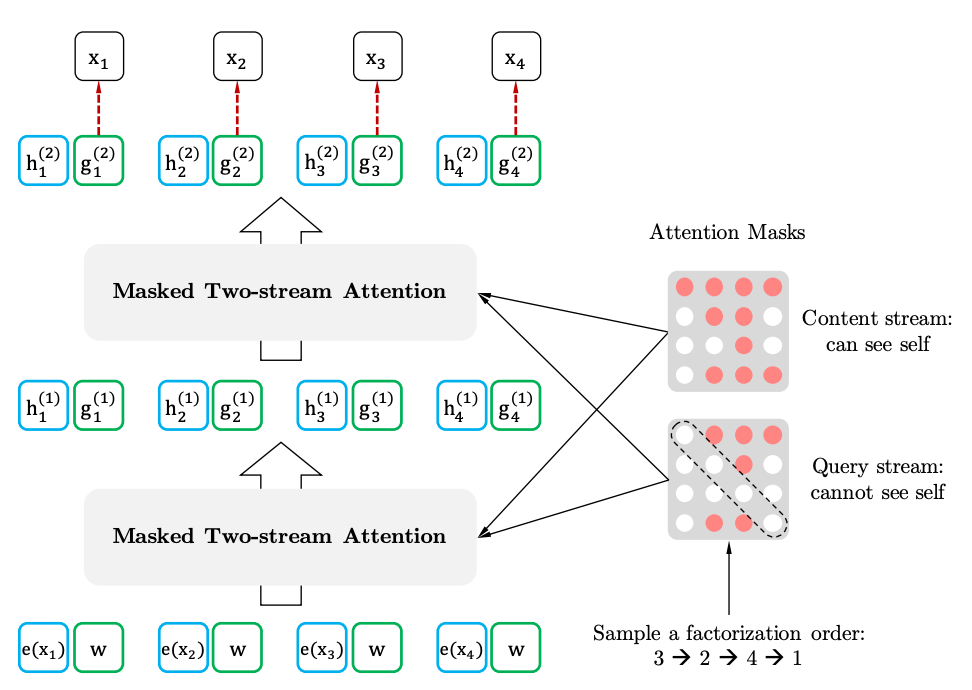
Целевое представление