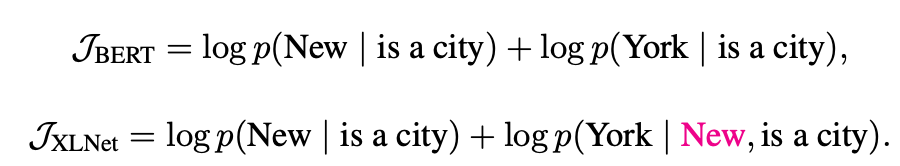xlnet Pytorch
1.0.0
Implémentation simple XLNET avec wrapper Pytorch!
$ git clone https://github.com/graykode/xlnet-Pytorch && cd xlnet-Pytorch
# To use Sentence Piece Tokenizer(pretrained-BERT Tokenizer)
$ pip install pytorch_pretrained_bert
$ python main.py --data ./data.txt --tokenizer bert-base-uncased
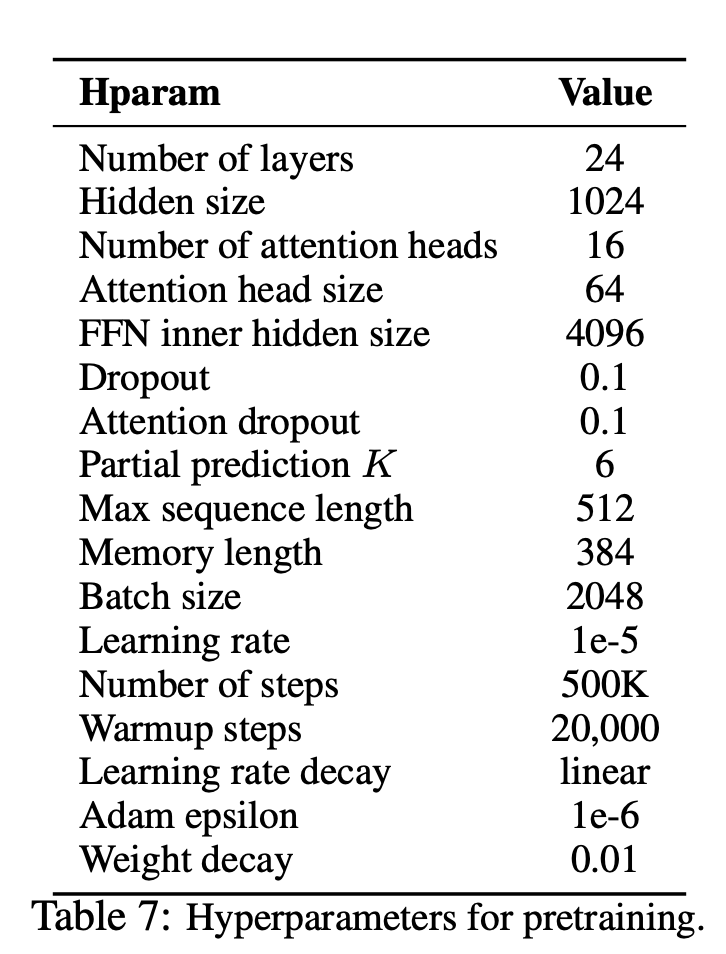
--seq_len 512 --reuse_len 256 --perm_size 256
--bi_data True --mask_alpha 6 --mask_beta 1
--num_predict 85 --mem_len 384 --num_epoch 100Vous pouvez également exécuter le code dans Google Colab facilement.
—data (String): fichier .txt à former. Peu importe le texte multiligne. De plus, un fichier sera un tenseur par lots. Par défaut: data.txt
—tokenizer (String): Je viens d'utiliser le tokenizer de HuggingFace / Pytorch-prétraité en tant que tokenizer sous-mots (je vais le modifier à la phrase bientôt). Vous pouvez choisir dans bert-base-uncased , bert-large-uncased , bert-base-cased , bert-large-cased . Par défaut: bert-base-uncased
—seq_len (entier): longueur de séquence. Par défaut: 512
—reuse_len (interger): nombre de jetons qui peuvent être réutilisés comme mémoire. Pourrait être la moitié de seq_len . Par défaut: 256
—perm_size (Interger): la longueur de la plus longue permutation. Pourrait être défini pour être réutilisé_len. Par défaut: 256
--bi_data (Boolean): s'il faut créer des données bidirectionnelles. Si bi_data est True , biz(batch size) devrait être un nombre uniforme. Par défaut: False
—mask_alpha (Interger): Combien de jetons pour former un groupe. Defalut: 6
—mask_beta (entier): combien de jetons à masquer au sein de chaque groupe. Par défaut: 1
—num_predict (Interger): Num de jetons à prédire. Dans le papier, cela signifie une prédiction partielle. Par défaut: 85
—mem_len (Interger): Nombre d'étapes pour se cacher dans l'architecture Transformateur-XL. Par défaut: 384
—num_epoch (Interger): Nombre d'époque. Par défaut: 100
XLNET est une nouvelle méthode d'apprentissage de représentation de langue non supervisée basée sur un nouvel objectif de modélisation de la langue de permutation généralisée. De plus, XLNET utilise Transformer-XL comme modèle de squelette, présentant d'excellentes performances pour les tâches linguistiques impliquant un contexte long.
| Modèle | MNLI | QNLI | QQP | Rte | SST-2 | MRPC | Cola | STS-B |
|---|---|---|---|---|---|---|---|---|
| Bert | 86.6 | 92.3 | 91.3 | 70.4 | 93.2 | 88.0 | 60.6 | 90.0 |
| Xlnet | 89.8 | 93.9 | 91.8 | 83.8 | 95.6 | 89.2 | 63.6 | 91.8 |
Comment XLNET a-t-il bénéficié des modèles d'auto-régression et de codage automatique?
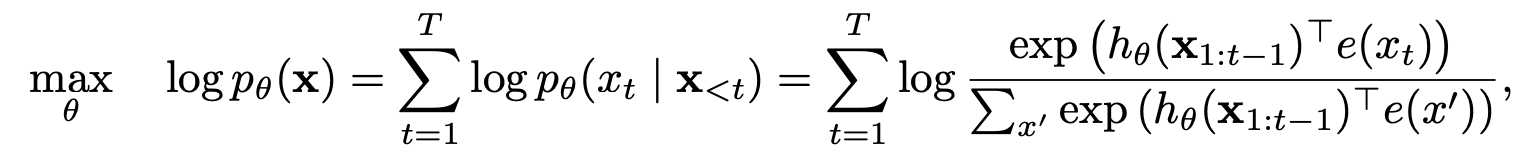
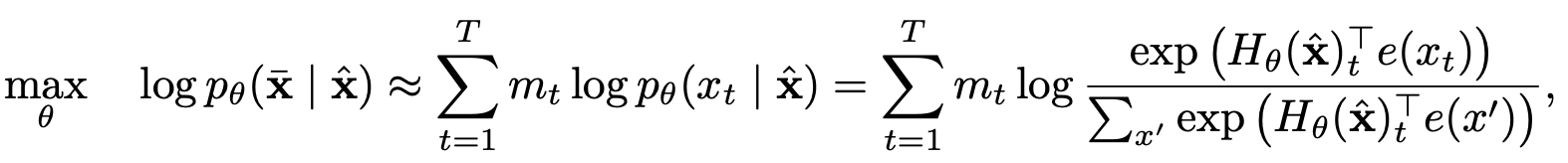
Modélisation du langage de permutation avec prédiction partielle
Modélisation du langage de permutation 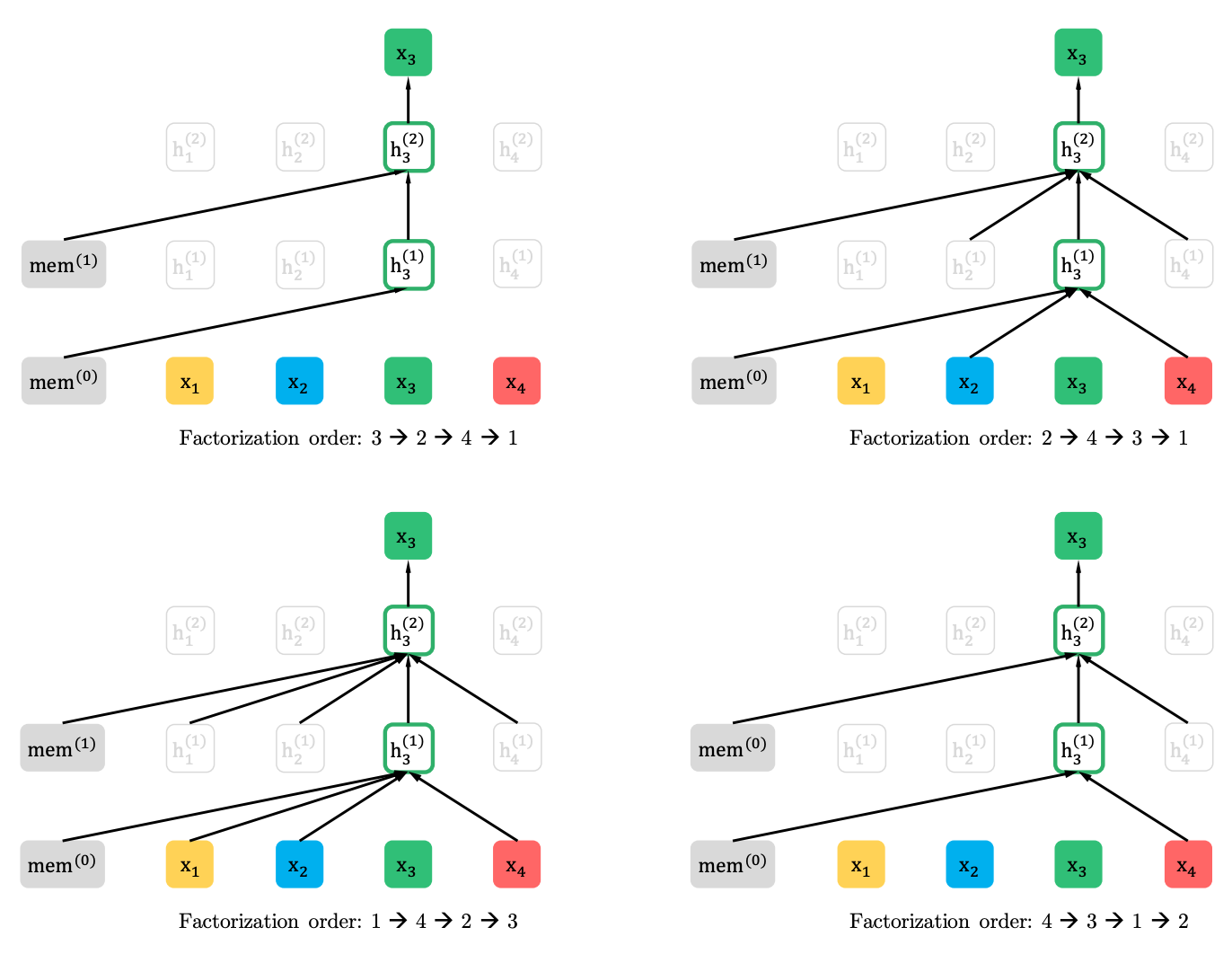
Prédiction partielle 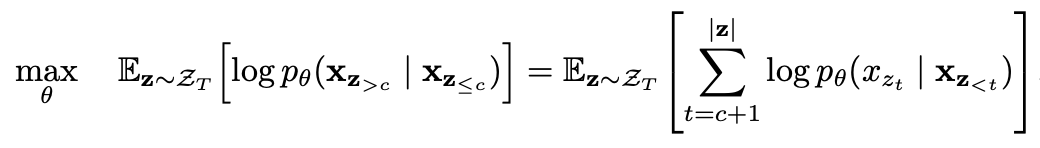
Assoi de l'auto-attitude à deux coureurs avec représentation consciente de la cible
Auto-attention à deux grammes
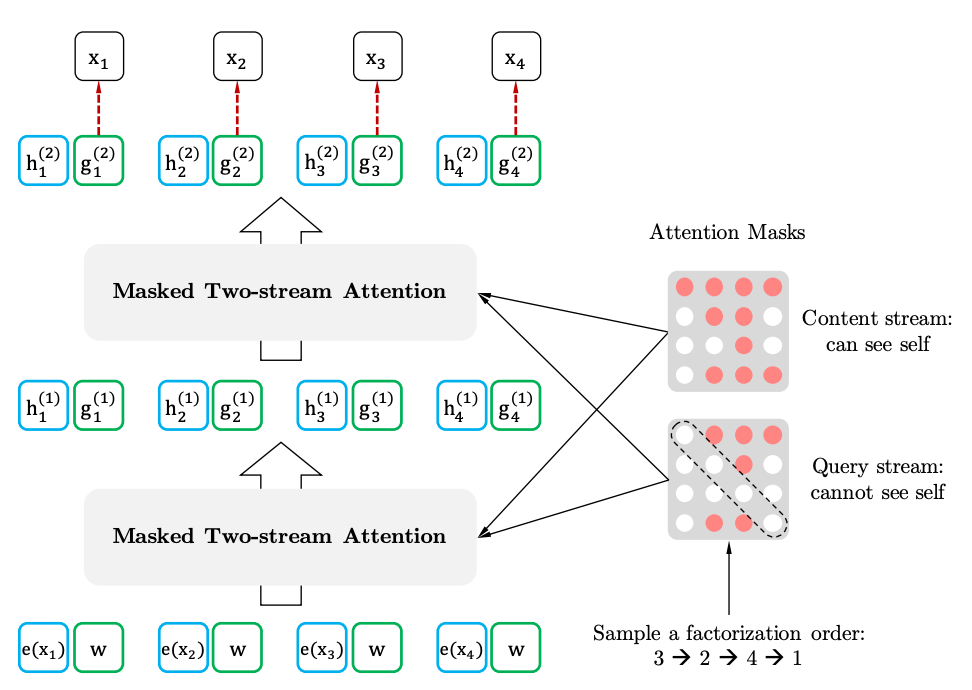
Représentation consciente de la cible