xlnet Pytorch
1.0.0
Einfache XLNET -Implementierung mit Pytorch Wrapper!
$ git clone https://github.com/graykode/xlnet-Pytorch && cd xlnet-Pytorch
# To use Sentence Piece Tokenizer(pretrained-BERT Tokenizer)
$ pip install pytorch_pretrained_bert
$ python main.py --data ./data.txt --tokenizer bert-base-uncased
--seq_len 512 --reuse_len 256 --perm_size 256
--bi_data True --mask_alpha 6 --mask_beta 1
--num_predict 85 --mem_len 384 --num_epoch 100Außerdem können Sie Code in Google Colab problemlos ausführen.
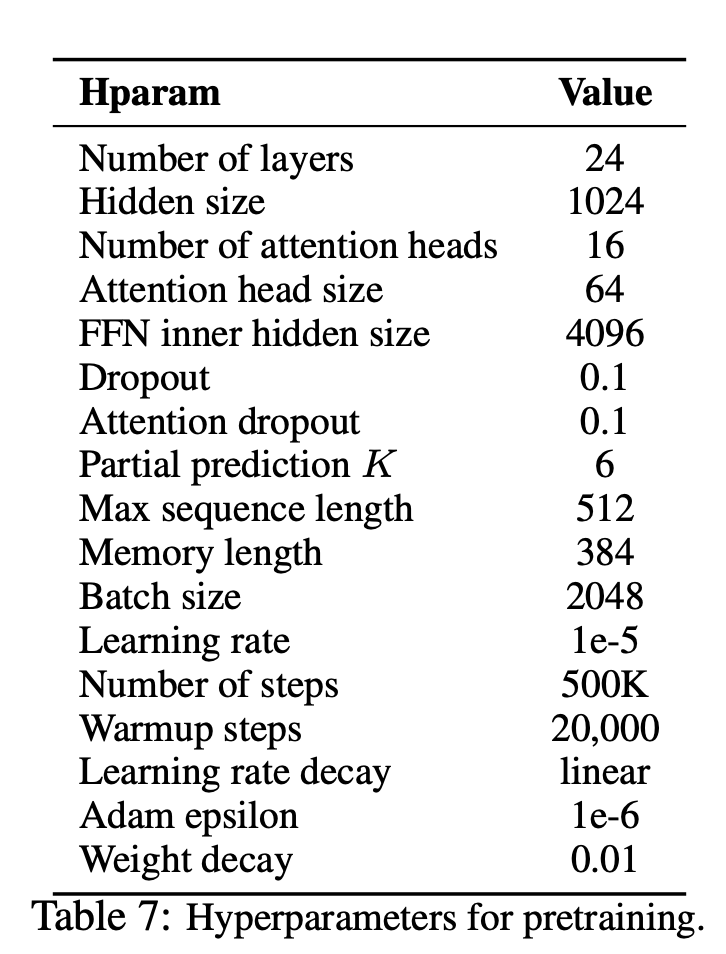
—data (String): .txt -Datei zu trainieren. Es spielt keine Rolle, multiline Text. Außerdem ist eine Datei ein Stapel -Tensor. Standard: data.txt
—tokenizer (String): Ich habe gerade Huggingface/Pytorch-vorbereitete Tokenizer als Subword-Tokenizer verwendet (ich werde es bald bearbeiten). Sie können in bert-base-uncased , bert-large-uncased , bert-base-cased , bert-large-cased wählen. Standard: bert-base-uncased
—seq_len (Ganzzahl): Sequenzlänge. Standard: 512
—reuse_len (Interger): Anzahl der Token, die als Speicher wiederverwendet werden können. Könnte die Hälfte von seq_len sein. Standard: 256
—perm_size (Interger): Die Länge der längsten Permutation. Könnte eingestellt sein, um wieder zu werden. Standard: 256
--bi_data (boolean): Ob bidirektionale Daten erstellen. Wenn bi_data True ist, sollte biz(batch size) eine gleichmäßige Anzahl sein. Standard: False
—mask_alpha (Interger): Wie viele Token, die eine Gruppe bilden. Defalut: 6
—mask_beta (Ganzzahl): Wie viele Token zu maskieren innerhalb jeder Gruppe. Standard: 1
—num_predict (Interger): Anzahl der Token, die vorhergesagt werden müssen. In Papier bedeutet dies teilweise Vorhersage. Standard: 85
—mem_len (Interger): Anzahl der Schritte, die in der Transformator-XL-Architektur zwischengespeichert werden. Standard: 384
—num_epoch (Interger): Anzahl der Epoche. Standard: 100
XLNET ist eine neue Lernmethode für unbeaufsichtigte Sprachrepräsentation, die auf einem neuartigen Permutationssprachenmodellierungsziel basiert. Darüber hinaus verwendet XLNET Transformator-XL als Backbone-Modell und weist eine hervorragende Leistung für Sprachaufgaben auf, die einen langen Kontext beinhalten.
| Modell | Mnli | Qnli | QQP | Rte | SST-2 | MRPC | Cola | STS-B |
|---|---|---|---|---|---|---|---|---|
| Bert | 86.6 | 92.3 | 91.3 | 70,4 | 93.2 | 88.0 | 60.6 | 90.0 |
| Xlnet | 89,8 | 93.9 | 91.8 | 83.8 | 95.6 | 89,2 | 63.6 | 91.8 |
Wie hat XLNET von automatischen Regressions- und automatisch kodierenden Modellen profitiert?
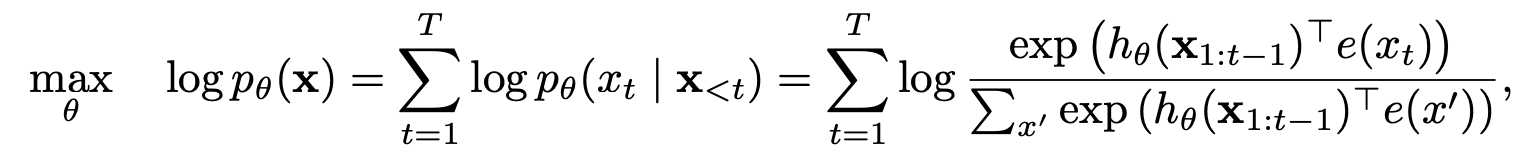
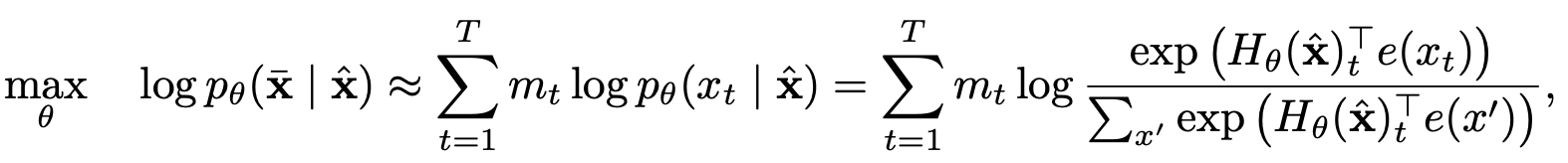
Permutationssprachmodellierung mit teilweise Vorhersage
Permutationssprachmodellierung 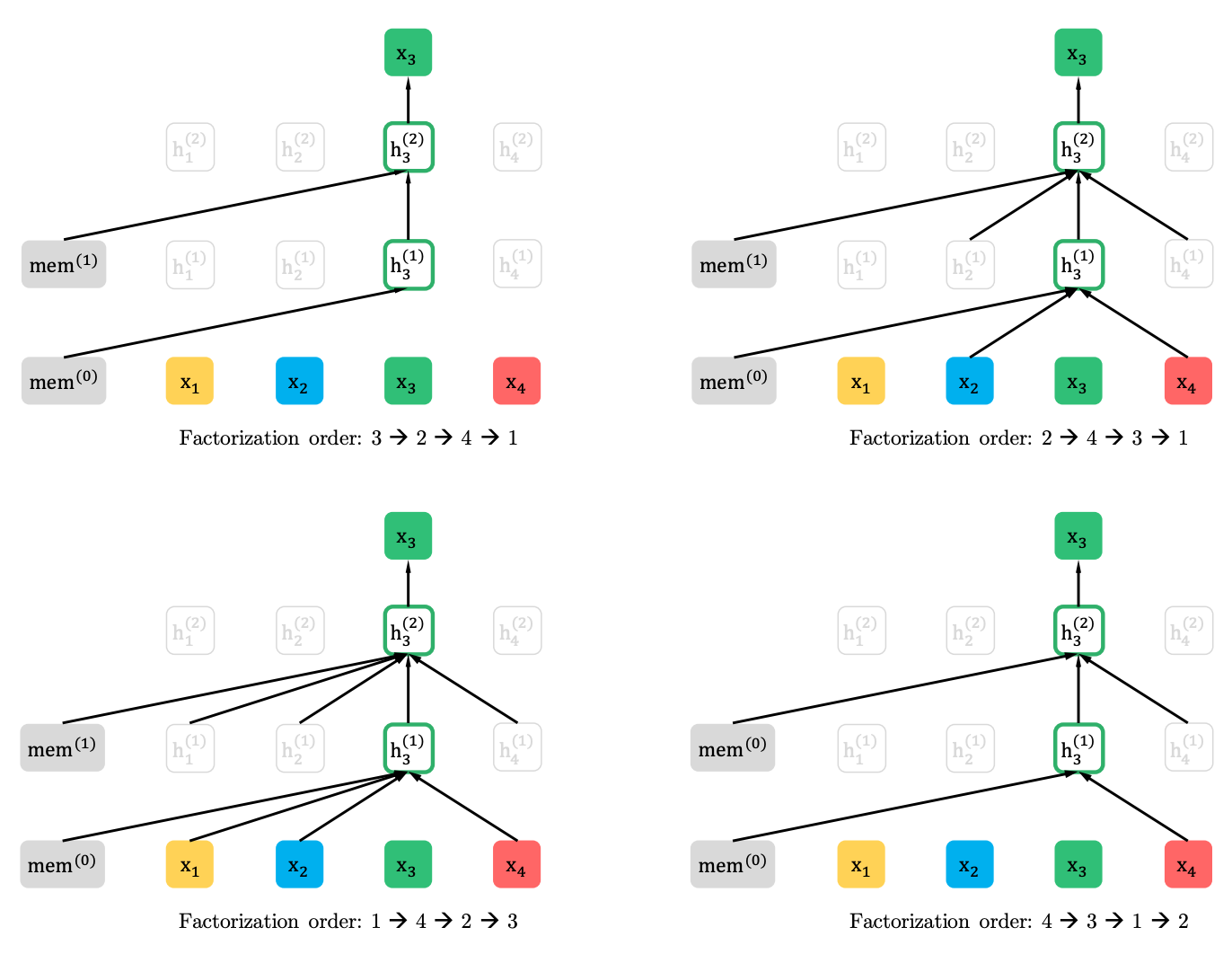
Partielle Vorhersage 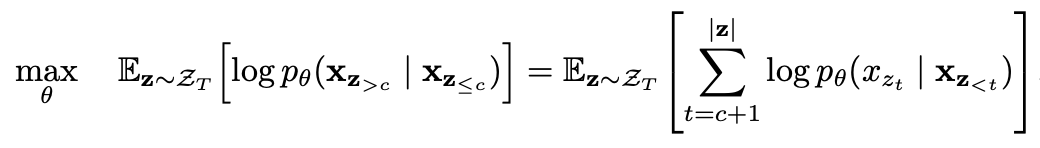
Zwei-Stream-Selbstbekämpfung mit Zielvertretung
Zwei-Stram-Selbstbeziehung
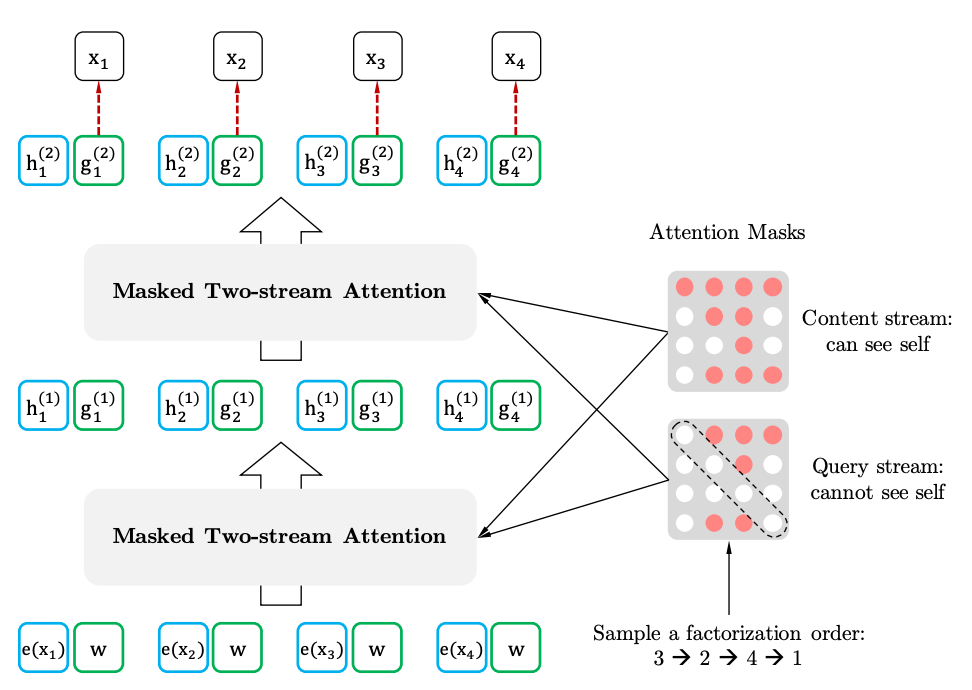
Zielgerichtete Darstellung