bigbird
1.0.0
不是官方的Google產品。
Bigbird是一種基於稀疏注意的變壓器,它將基於變壓器的模型(例如BERT)擴展到更長的序列。此外,Bigbird對稀疏模型可以處理的完整變壓器的功能有理論上的理解。
由於能夠處理更長的上下文的能力,大鳥大大提高了各種NLP任務的性能,例如問答和摘要。
更多細節和比較可以在我們的演講中找到。
如果您覺得這有用,請引用我們的神經2020紙:
@article{zaheer2020bigbird,
title={Big bird: Transformers for longer sequences},
author={Zaheer, Manzil and Guruganesh, Guru and Dubey, Kumar Avinava and Ainslie, Joshua and Alberti, Chris and Ontanon, Santiago and Pham, Philip and Ravula, Anirudh and Wang, Qifan and Yang, Li and others},
journal={Advances in Neural Information Processing Systems},
volume={33},
year={2020}
}
最重要的目錄是core 。 core中有三個主要文件。
IMDB.IPYNB提供了快速的文本分類示範
請先創建一個項目,然後在具有配額的區域中創建一個實例
gcloud compute instances create
bigbird
--zone=europe-west4-a
--machine-type=n1-standard-16
--boot-disk-size=50GB
--image-project=ml-images
--image-family=tf-2-3-1
--maintenance-policy TERMINATE
--restart-on-failure
--scopes=cloud-platform
gcloud compute tpus create
bigbird
--zone=europe-west4-a
--accelerator-type=v3-32
--version=2.3.1
gcloud compute ssh --zone " europe-west4-a " " bigbird "
為了插圖,我們使用了實例名稱bigbird和Zone europe-west4-a ,但可以隨意更改它們。有關創建Google Cloud TPU的更多詳細信息,請參見在線文檔中。
git clone https://github.com/google-research/bigbird.git
cd bigbird
pip3 install -e .您可以在我們的Google Cloud儲物存儲桶中找到經過預定的和微調的檢查點。
可選,您可以使用gsutil作為
mkdir -p bigbird/ckpt
gsutil cp -r gs://bigbird-transformer/ bigbird/ckpt/儲物桶包含:
bigbr_base )和大( bigbr_large )尺寸的BERT驗證模型。它對應於僅Bert/Roberta樣模型。遵循原始的BERT和ROBERTA實現,它們是具有差異後正函數的變壓器,IE層標準正在註意力層之後。但是,在Rothe等人之後,我們可以通過耦合編碼器和解碼器參數來部分使用它們,如bigbird/summarization/roberta_base.sh啟動腳本所示。bigbp_large )預驗證的Pegasus編碼器碼頭變壓器。再次實現Pegasus之後,它們是具有前歸一化的變壓器。他們具有完整的單獨的編碼器重量。同樣,對於長文檔摘要數據集,我們已經為每個數據集轉換了Pegasus檢查點( model.ckpt-0 ),並提供了用於更長文檔的精細調整檢查點( model.ckpt-300000 )。tf.SavedModel ,可直接用於預測和評估,如Colab Sonotebook中所示。要快速從BigBird開始,可以從classifier目錄中運行分類實驗代碼開始。運行代碼只需執行
export GCP_PROJECT_NAME=bigbird-project # Replace by your project name
export GCP_EXP_BUCKET=gs://bigbird-transformer-training/ # Replace
sh -x bigbird/classifier/base_size.sh要直接使用編碼器而不是說BERT模型,我們可以使用以下代碼。
from bigbird . core import modeling
bigb_encoder = modeling . BertModel (...)它可以輕鬆替換Bert的編碼器。
另外,也可以嘗試使用Bigbird編碼器層玩
from bigbird . core import encoder
only_layers = encoder . EncoderStack (...)所有標誌和配置都在core/flags.py中解釋。在這裡,我們解釋了一些重要的配置參數。
attention_type用於選擇我們將使用的注意力類型。將其設置為block_sparse運行BigBird注意模塊。
flags . DEFINE_enum (
"attention_type" , "block_sparse" ,
[ "original_full" , "simulated_sparse" , "block_sparse" ],
"Selecting attention implementation. "
"'original_full': full attention from original bert. "
"'simulated_sparse': simulated sparse attention. "
"'block_sparse': blocked implementation of sparse attention." ) block_size用於定義塊的大小,而num_rand_blocks用於設置隨機塊的數量。該代碼當前使用3個塊和2個全局塊的窗口大小。當前代碼僅支持靜態張量。
要注意的要點:
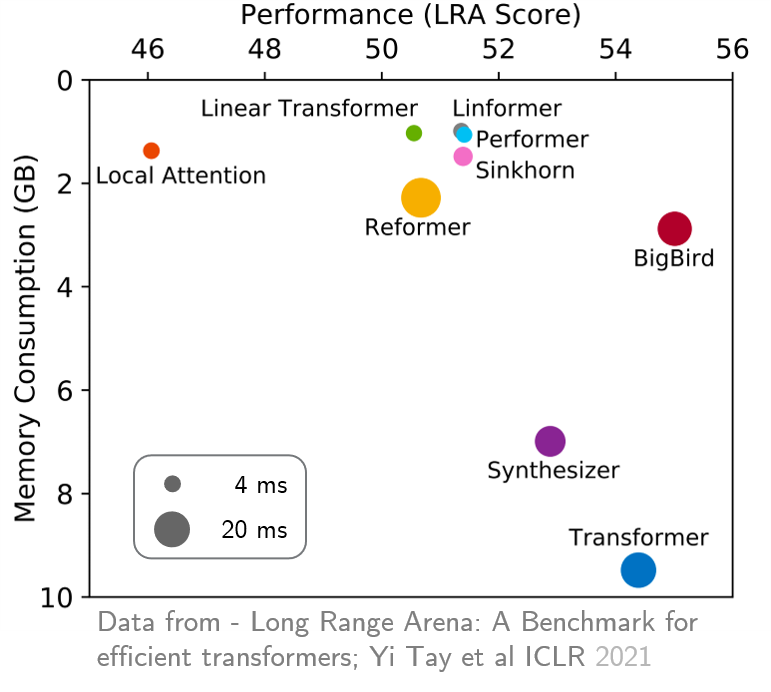
original_full ,因為使用稀疏的bigbird注意沒有好處。 最近,遠程競技場提供了六個需要更長上下文的任務的基準,並執行了實驗以基準所有現有的遠程變壓器。結果如下所示。與同行不同的是,Bigbird模型顯然可以減少記憶消耗而無需犧牲性能。