bigbird
1.0.0
공식적인 Google 제품이 아닙니다.
Bigbird는 Bert와 같은 변압기 기반 모델을 훨씬 더 긴 시퀀스로 확장하는 희박한 분위기 기반 변압기입니다. 또한 Bigbird는 스파 스 모델이 처리 할 수있는 완전한 변압기의 기능에 대한 이론적 이해와 함께 제공됩니다.
더 긴 컨텍스트를 처리 할 수있는 기능의 결과로 Bigbird는 질문 답변 및 요약과 같은 다양한 NLP 작업의 성능을 크게 향상시킵니다.
자세한 내용과 비교는 프레젠테이션에서 찾을 수 있습니다.
이것이 유용하다고 생각되면, 우리의 Neurips 2020 종이를 인용하십시오.
@article{zaheer2020bigbird,
title={Big bird: Transformers for longer sequences},
author={Zaheer, Manzil and Guruganesh, Guru and Dubey, Kumar Avinava and Ainslie, Joshua and Alberti, Chris and Ontanon, Santiago and Pham, Philip and Ravula, Anirudh and Wang, Qifan and Yang, Li and others},
journal={Advances in Neural Information Processing Systems},
volume={33},
year={2020}
}
가장 중요한 디렉토리는 core 입니다. core 에는 세 가지 주요 파일이 있습니다.
텍스트 분류를위한 빠른 미세 조정 데모는 imdb.ipynb에 제공됩니다.
먼저 프로젝트를 만들고 다음과 같이 할당량이있는 영역에서 인스턴스를 만듭니다.
gcloud compute instances create
bigbird
--zone=europe-west4-a
--machine-type=n1-standard-16
--boot-disk-size=50GB
--image-project=ml-images
--image-family=tf-2-3-1
--maintenance-policy TERMINATE
--restart-on-failure
--scopes=cloud-platform
gcloud compute tpus create
bigbird
--zone=europe-west4-a
--accelerator-type=v3-32
--version=2.3.1
gcloud compute ssh --zone " europe-west4-a " " bigbird "
예시를 위해 인스턴스 이름 bigbird 및 Zone europe-west4-a 사용했지만 자유롭게 변경하십시오. Google Cloud TPU 작성에 대한 자세한 내용은 온라인 문서에서 찾을 수 있습니다.
git clone https://github.com/google-research/bigbird.git
cd bigbird
pip3 install -e .Google Cloud Storage 버킷에서 사전 및 미세 조정 된 체크 포인트를 찾을 수 있습니다.
선택적으로 gsutil AS를 사용하여 다운로드 할 수 있습니다
mkdir -p bigbird/ckpt
gsutil cp -r gs://bigbird-transformer/ bigbird/ckpt/스토리지 버킷에는 다음이 포함됩니다.
bigbr_base ) 및 큰 ( bigbr_large ) 크기에 대한 사전 치료 된 버트 모델. Bert/Roberta-like Encoder 전용 모델에 해당합니다. 원래 Bert 및 Roberta 구현에 따라 정상화 후 변압기이며, 즉 층 표준은주의 레이어 후에 발생합니다. 그러나 Rothe et al에 따라 BigBird/Sumbarization/Roberta_base.sh 런치 스크립트에 표시된대로 인코더 및 디코더 매개 변수를 결합하여 인코더 디코더 방식으로 부분적으로 사용할 수 있습니다.bigbp_large ). 페가수스의 독창적 인 구현에 따라, 그들은 정상화를 가진 변압기입니다. 그들은 별도의 인코더 디코더 가중치 세트를 가지고 있습니다. 또한 긴 문서 요약 데이터 세트의 경우 각 데이터 세트에 대해 Pegasus 체크 포인트 ( model.ckpt-0 )를 변환했으며 더 긴 문서에서 작동하는 미세 조정 체크 포인트 ( model.ckpt-300000 )도 제공했습니다.tf.SavedModel . BigBird로 빠르게 시작하려면 classifier 디렉토리에서 분류 실험 코드를 실행하여 시작할 수 있습니다. 코드를 실행하려면 단순히 실행됩니다
export GCP_PROJECT_NAME=bigbird-project # Replace by your project name
export GCP_EXP_BUCKET=gs://bigbird-transformer-training/ # Replace
sh -x bigbird/classifier/base_size.shBert 모델 대신 인코더를 직접 사용하려면 다음 코드를 사용할 수 있습니다.
from bigbird . core import modeling
bigb_encoder = modeling . BertModel (...)Bert의 인코더를 쉽게 대체 할 수 있습니다.
또는 Bigbird 인코더의 레이어를 사용해 볼 수도 있습니다.
from bigbird . core import encoder
only_layers = encoder . EncoderStack (...) 모든 플래그와 구성은 core/flags.py 에 설명되어 있습니다. 여기서 우리는 중요한 구성 매개 변수 중 일부를 설명합니다.
attention_type 우리가 사용할주의의 유형을 선택하는 데 사용됩니다. block_sparse 로 설정하면 Bigbird주의 모듈이 실행됩니다.
flags . DEFINE_enum (
"attention_type" , "block_sparse" ,
[ "original_full" , "simulated_sparse" , "block_sparse" ],
"Selecting attention implementation. "
"'original_full': full attention from original bert. "
"'simulated_sparse': simulated sparse attention. "
"'block_sparse': blocked implementation of sparse attention." ) block_size 블록의 크기를 정의하는 데 사용되는 반면 num_rand_blocks 랜덤 블록 수를 설정하는 데 사용됩니다. 코드는 현재 3 개의 블록과 2 개의 글로벌 블록의 창 크기를 사용합니다. 현재 코드는 정적 텐서 만 지원합니다.
주목해야 할 중요한 점 :
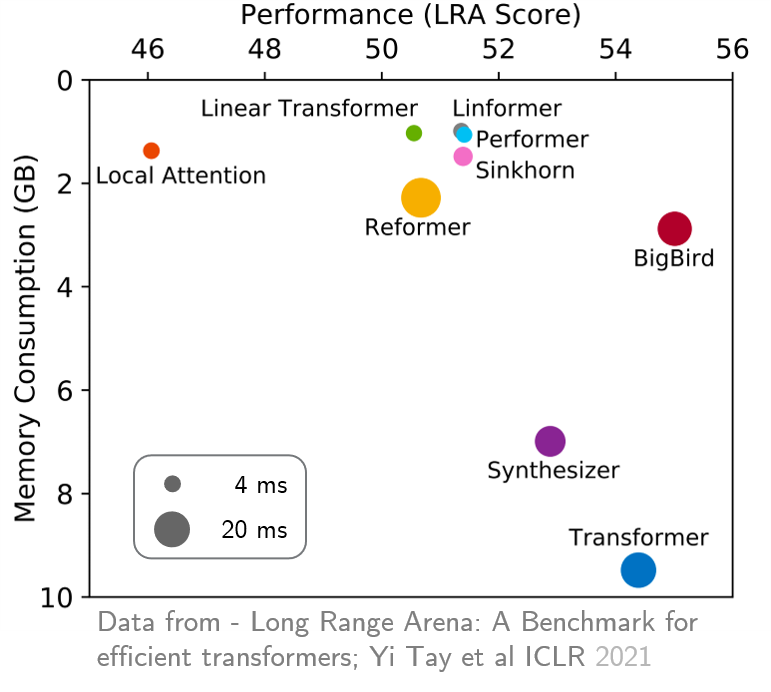
original_full 사용하는 것이 좋습니다. 최근 Long Range Arena는 더 긴 컨텍스트가 필요한 6 가지 작업의 벤치 마크를 제공했으며 기존의 모든 장거리 변압기를 벤치마킹하기위한 실험을 수행했습니다. 결과는 아래에 나와 있습니다. Bigbird Model은 상대방과 달리 성능을 희생하지 않고 메모리 소비를 명확하게 줄입니다.