bigbird
1.0.0
Não é um produto oficial do Google.
Bigbird, é um transformador baseado em atendimento esparso que estende modelos baseados em transformadores, como Bert a sequências muito mais longas. Além disso, o Bigbird vem junto com um entendimento teórico das capacidades de um transformador completo que o modelo esparso pode suportar.
Como conseqüência da capacidade de lidar com um contexto mais longo, o Bigbird melhora drasticamente o desempenho em várias tarefas de PNL, como resposta a perguntas e resumo.
Mais detalhes e comparações podem ser encontrados em nossa apresentação.
Se você achar isso útil, cite nosso papel Neurips 2020:
@article{zaheer2020bigbird,
title={Big bird: Transformers for longer sequences},
author={Zaheer, Manzil and Guruganesh, Guru and Dubey, Kumar Avinava and Ainslie, Joshua and Alberti, Chris and Ontanon, Santiago and Pham, Philip and Ravula, Anirudh and Wang, Qifan and Yang, Li and others},
journal={Advances in Neural Information Processing Systems},
volume={33},
year={2020}
}
O diretório mais importante é core . Existem três arquivos principais no core .
Uma rápida demonstração de ajuste fino para classificação de texto é fornecida no imdb.ipynb
Crie um projeto primeiro e crie uma instância em uma zona que tenha cota da seguinte maneira
gcloud compute instances create
bigbird
--zone=europe-west4-a
--machine-type=n1-standard-16
--boot-disk-size=50GB
--image-project=ml-images
--image-family=tf-2-3-1
--maintenance-policy TERMINATE
--restart-on-failure
--scopes=cloud-platform
gcloud compute tpus create
bigbird
--zone=europe-west4-a
--accelerator-type=v3-32
--version=2.3.1
gcloud compute ssh --zone " europe-west4-a " " bigbird "
Para ilustração, usamos o nome da instância bigbird e a Zone europe-west4-a , mas fique à vontade para alterá-los. Mais detalhes sobre a criação de TPU do Google Cloud podem ser encontrados em documentações on -line.
git clone https://github.com/google-research/bigbird.git
cd bigbird
pip3 install -e .Você pode encontrar pontos de verificação pré-terenciados e ajustados em nosso balde de armazenamento em nuvem do Google.
Opcionalmente, você pode baixá -los usando gsutil como
mkdir -p bigbird/ckpt
gsutil cp -r gs://bigbird-transformer/ bigbird/ckpt/O balde de armazenamento contém:
bigbr_base ) e tamanho grande ( bigbr_large ). Corresponde aos modelos apenas do codificador do tipo Bert/Roberta. Seguindo a implementação original de Bert e Roberta, eles são transformadores com pós-normalização, a norma da camada do IE está acontecendo após a camada de atenção. No entanto, seguindo Rothe et al, podemos usá-los parcialmente de maneira codificadora-decodificadora, acoplando os parâmetros do codificador e decodificador, conforme ilustrado no script de lançamento do BigBird/Summarization/Roberta_Base.SH.bigbp_large ). Novamente, após a implementação original de Pegasus, eles são transformadores com pré-normalização. Eles têm um conjunto completo de pesos separados do codificador-decodificador. Também para conjuntos de dados de resumo de documentos longos, convertemos pontos de verificação PEGASUS ( model.ckpt-0 ) para cada conjunto de dados e também fornecemos pontos de verificação ajustados ( model.ckpt-300000 ), que funcionam em documentos mais longos.tf.SavedModel FINED para resumo de documentos longos que podem ser diretamente usados para previsão e avaliação, conforme ilustrado no Colab Nootebook. Para começar rapidamente com o BigBird, pode -se começar executando o código do experimento de classificação no diretório classifier . Para executar o código, simplesmente execute
export GCP_PROJECT_NAME=bigbird-project # Replace by your project name
export GCP_EXP_BUCKET=gs://bigbird-transformer-training/ # Replace
sh -x bigbird/classifier/base_size.shPara usar diretamente o codificador em vez de dizer o modelo BERT, podemos usar o seguinte código.
from bigbird . core import modeling
bigb_encoder = modeling . BertModel (...)Ele pode facilmente substituir o codificador de Bert.
Como alternativa, também se pode tentar brincar com camadas de codificador bigbird
from bigbird . core import encoder
only_layers = encoder . EncoderStack (...) Todas as bandeiras e configurações são explicadas em core/flags.py . Aqui, explicamos alguns dos parâmetros de configuração importantes.
attention_type é usado para selecionar o tipo de atenção que usaríamos. Configurando -o para block_sparse executa o módulo de atenção Bigbird.
flags . DEFINE_enum (
"attention_type" , "block_sparse" ,
[ "original_full" , "simulated_sparse" , "block_sparse" ],
"Selecting attention implementation. "
"'original_full': full attention from original bert. "
"'simulated_sparse': simulated sparse attention. "
"'block_sparse': blocked implementation of sparse attention." ) block_size é usado para definir o tamanho dos blocos, enquanto num_rand_blocks é usado para definir o número de blocos aleatórios. Atualmente, o código usa o tamanho da janela de 3 blocos e 2 blocos globais. O código atual suporta apenas tensores estáticos.
Pontos importantes a serem observados:
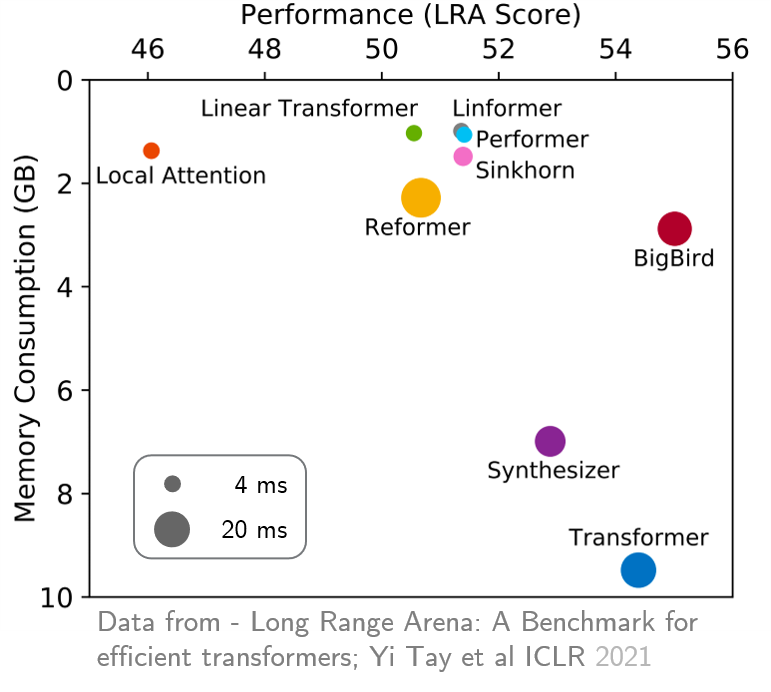
original_full é recomendado, pois não há benefício no uso da atenção esparsa do BigBird. Recentemente, a Long Range Arena forneceu uma referência de seis tarefas que requerem um contexto mais longo e realizaram experimentos para comparar todos os transformadores de longo alcance existentes. Os resultados são mostrados abaixo. O modelo Bigbird, diferentemente de suas contrapartes, reduz claramente o consumo de memória sem sacrificar o desempenho.