bigbird
1.0.0
Kein offizielles Google -Produkt.
Bigbird ist ein spärlicher Auftragsstransformator, der Transformator-basierte Modelle wie BERT auf viel längere Sequenzen erweitert. Darüber hinaus kommt Bigbird mit einem theoretischen Verständnis der Fähigkeiten eines vollständigen Transformators mit, mit dem das spärliche Modell umgehen kann.
Infolge der Fähigkeit, einen längeren Kontext zu bewältigen, verbessert Bigbird die Leistung bei verschiedenen NLP -Aufgaben wie Fragen und Zusammenfassung.
Weitere Details und Vergleiche finden Sie in unserer Präsentation.
Wenn Sie dies nützlich finden, zitieren Sie bitte unsere Neurips 2020 -Papier:
@article{zaheer2020bigbird,
title={Big bird: Transformers for longer sequences},
author={Zaheer, Manzil and Guruganesh, Guru and Dubey, Kumar Avinava and Ainslie, Joshua and Alberti, Chris and Ontanon, Santiago and Pham, Philip and Ravula, Anirudh and Wang, Qifan and Yang, Li and others},
journal={Advances in Neural Information Processing Systems},
volume={33},
year={2020}
}
Das wichtigste Verzeichnis ist core . Es gibt drei Hauptdateien im core .
Eine schnelle Feinabstimmungsdemonstration für die Textklassifizierung finden Sie in IMDB.IPynb
Bitte erstellen Sie zuerst ein Projekt und erstellen Sie eine Instanz in einer Zone, die Quoten wie folgt hat
gcloud compute instances create
bigbird
--zone=europe-west4-a
--machine-type=n1-standard-16
--boot-disk-size=50GB
--image-project=ml-images
--image-family=tf-2-3-1
--maintenance-policy TERMINATE
--restart-on-failure
--scopes=cloud-platform
gcloud compute tpus create
bigbird
--zone=europe-west4-a
--accelerator-type=v3-32
--version=2.3.1
gcloud compute ssh --zone " europe-west4-a " " bigbird "
Zur Illustration haben wir den Instanznamen bigbird und Zone europe-west4-a verwendet, aber sie können sie gerne ändern. Weitere Details zum Erstellen von Google Cloud TPU finden Sie in Online -Dokumentationen.
git clone https://github.com/google-research/bigbird.git
cd bigbird
pip3 install -e .In unserem Google Cloud-Speicher-Bucket finden Sie vorab vorgelegte und abgestimmte Kontrollpunkte.
Optional können Sie sie mit gsutil als herunterladen
mkdir -p bigbird/ckpt
gsutil cp -r gs://bigbird-transformer/ bigbird/ckpt/Der Speicherkorb enthält:
bigbr_base ) und große ( bigbr_large ) Größe. Es entspricht nur Modellen von Bert/Roberta-ähnlicher Encoder. Nach der ursprünglichen Implementierung von Bert und Roberta sind sie Transformatoren mit Nach der Normalisierung, dh Layer-Norm erfolgt nach der Aufmerksamkeitsschicht. Nach Rothe et al. Können wir sie jedoch teilweise in der Encoder-Decoder-Mode verwenden, indem wir die Parameter Encoder und Decoder zusammenstellen, wie in Bigbird/Summarization/Roberta_Base.sh Launch-Skript dargestellt.bigbp_large ). Nach der ursprünglichen Implementierung von Pegasus sind sie erneut Transformatoren mit Vornormalisierung. Sie haben einen vollständigen Satz separater Encoder-Decoder-Gewichte. Auch für lange Dokumentenübersichtsdatensätze haben wir Pegasus-Checkpoints ( model.ckpt-0 ) für jeden Datensatz konvertiert und auch fein abgestimmte Kontrollpunkte ( model.ckpt-300000 ) bereitgestellt, die auf längeren Dokumenten funktionieren.tf.SavedModel Für eine lange Zusammenfassung der Dokumente, die direkt zur Vorhersage und Bewertung verwendet werden kann, wie im Colab Nootebook dargestellt. Für schnell mit Bigbird kann man mit dem Ausführen des Klassifizierungsexperimentcode im classifier beginnen. Um den Code auszuführen, führen Sie einfach aus
export GCP_PROJECT_NAME=bigbird-project # Replace by your project name
export GCP_EXP_BUCKET=gs://bigbird-transformer-training/ # Replace
sh -x bigbird/classifier/base_size.shUm den Encoder anstelle von Say Bert -Modell direkt zu verwenden, können wir den folgenden Code verwenden.
from bigbird . core import modeling
bigb_encoder = modeling . BertModel (...)Es kann leicht Berts Encoder ersetzen.
Alternativ kann man auch versuchen, mit Schichten von Bigbird -Encoder zu spielen
from bigbird . core import encoder
only_layers = encoder . EncoderStack (...) Alle Flags und Konfigurationen werden in core/flags.py erläutert. Hier erklären wir einige der wichtigen Konfigurationsparamater.
attention_type wird verwendet, um die Art der Aufmerksamkeit auszuwählen, die wir verwenden würden. Das Einstellen von block_sparse führt das Bigbird -Aufmerksamkeitsmodul aus.
flags . DEFINE_enum (
"attention_type" , "block_sparse" ,
[ "original_full" , "simulated_sparse" , "block_sparse" ],
"Selecting attention implementation. "
"'original_full': full attention from original bert. "
"'simulated_sparse': simulated sparse attention. "
"'block_sparse': blocked implementation of sparse attention." ) block_size wird verwendet, um die Größe der Blöcke zu definieren, während num_rand_blocks verwendet wird, um die Anzahl der Zufallsblöcke festzulegen. Der Code verwendet derzeit eine Fenstergröße von 3 Blöcken und 2 globalen Blöcken. Der aktuelle Code unterstützt nur statische Tensoren.
Wichtige Punkte zu beachten:
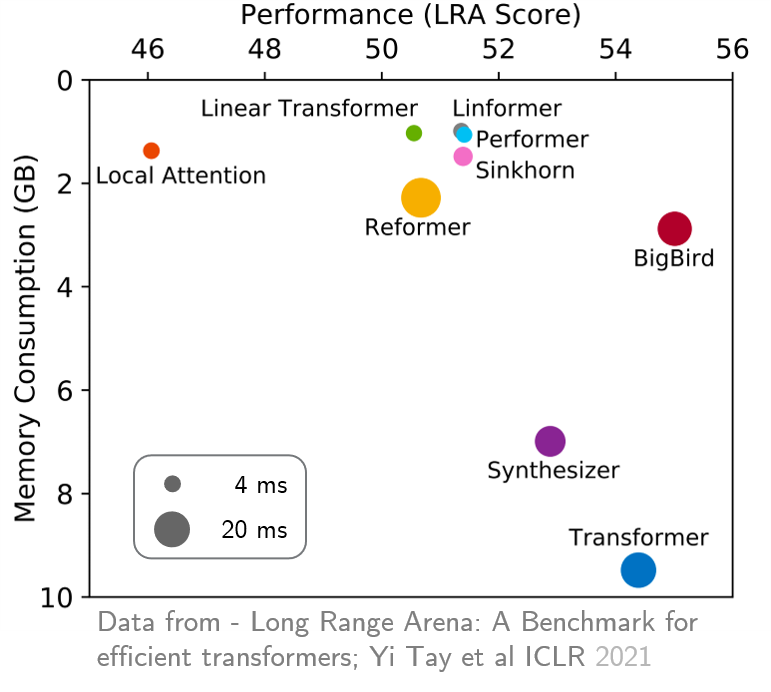
original_full empfohlen, da es keinen Nutzen bei der Verwendung von spärlicher Bigbird -Aufmerksamkeit gibt. In jüngster Zeit lieferte die Langstreckenarena einen Maßstab von sechs Aufgaben, die einen längeren Kontext erfordern, und führte Experimente durch, um alle vorhandenen Langstreckentransformatoren zu bewerten. Die Ergebnisse sind unten angezeigt. Das Bigbird -Modell reduziert im Gegensatz zu seinen Gegenstücken den Speicherverbrauch eindeutig, ohne die Leistung zu beeinträchtigen.