bigbird
1.0.0
不是官方的Google产品。
Bigbird是一种基于稀疏注意的变压器,它将基于变压器的模型(例如BERT)扩展到更长的序列。此外,Bigbird对稀疏模型可以处理的完整变压器的功能有理论上的理解。
由于能够处理更长的上下文的能力,大鸟大大提高了各种NLP任务的性能,例如问答和摘要。
更多细节和比较可以在我们的演讲中找到。
如果您觉得这有用,请引用我们的神经2020纸:
@article{zaheer2020bigbird,
title={Big bird: Transformers for longer sequences},
author={Zaheer, Manzil and Guruganesh, Guru and Dubey, Kumar Avinava and Ainslie, Joshua and Alberti, Chris and Ontanon, Santiago and Pham, Philip and Ravula, Anirudh and Wang, Qifan and Yang, Li and others},
journal={Advances in Neural Information Processing Systems},
volume={33},
year={2020}
}
最重要的目录是core 。 core中有三个主要文件。
IMDB.IPYNB提供了快速的文本分类示范
请先创建一个项目,然后在具有配额的区域中创建一个实例
gcloud compute instances create
bigbird
--zone=europe-west4-a
--machine-type=n1-standard-16
--boot-disk-size=50GB
--image-project=ml-images
--image-family=tf-2-3-1
--maintenance-policy TERMINATE
--restart-on-failure
--scopes=cloud-platform
gcloud compute tpus create
bigbird
--zone=europe-west4-a
--accelerator-type=v3-32
--version=2.3.1
gcloud compute ssh --zone " europe-west4-a " " bigbird "
为了插图,我们使用了实例名称bigbird和Zone europe-west4-a ,但可以随意更改它们。有关创建Google Cloud TPU的更多详细信息,请参见在线文档中。
git clone https://github.com/google-research/bigbird.git
cd bigbird
pip3 install -e .您可以在我们的Google Cloud储物存储桶中找到经过预定的和微调的检查点。
可选,您可以使用gsutil作为
mkdir -p bigbird/ckpt
gsutil cp -r gs://bigbird-transformer/ bigbird/ckpt/储物桶包含:
bigbr_base )和大( bigbr_large )尺寸的BERT验证模型。它对应于仅Bert/Roberta样模型。遵循原始的BERT和ROBERTA实现,它们是具有差异后正函数的变压器,IE层标准正在注意力层之后。但是,在Rothe等人之后,我们可以通过耦合编码器和解码器参数来部分使用它们,如bigbird/summarization/roberta_base.sh启动脚本所示。bigbp_large )预验证的Pegasus编码器码头变压器。再次实现Pegasus之后,它们是具有前归一化的变压器。他们具有完整的单独的编码器重量。同样,对于长文档摘要数据集,我们已经为每个数据集转换了Pegasus检查点( model.ckpt-0 ),并提供了用于更长文档的精细调整检查点( model.ckpt-300000 )。tf.SavedModel ,可直接用于预测和评估,如Colab Sonotebook中所示。要快速从BigBird开始,可以从classifier目录中运行分类实验代码开始。运行代码只需执行
export GCP_PROJECT_NAME=bigbird-project # Replace by your project name
export GCP_EXP_BUCKET=gs://bigbird-transformer-training/ # Replace
sh -x bigbird/classifier/base_size.sh要直接使用编码器而不是说BERT模型,我们可以使用以下代码。
from bigbird . core import modeling
bigb_encoder = modeling . BertModel (...)它可以轻松替换Bert的编码器。
另外,也可以尝试使用Bigbird编码器层玩
from bigbird . core import encoder
only_layers = encoder . EncoderStack (...)所有标志和配置都在core/flags.py中解释。在这里,我们解释了一些重要的配置参数。
attention_type用于选择我们将使用的注意力类型。将其设置为block_sparse运行BigBird注意模块。
flags . DEFINE_enum (
"attention_type" , "block_sparse" ,
[ "original_full" , "simulated_sparse" , "block_sparse" ],
"Selecting attention implementation. "
"'original_full': full attention from original bert. "
"'simulated_sparse': simulated sparse attention. "
"'block_sparse': blocked implementation of sparse attention." ) block_size用于定义块的大小,而num_rand_blocks用于设置随机块的数量。该代码当前使用3个块和2个全局块的窗口大小。当前代码仅支持静态张量。
要注意的要点:
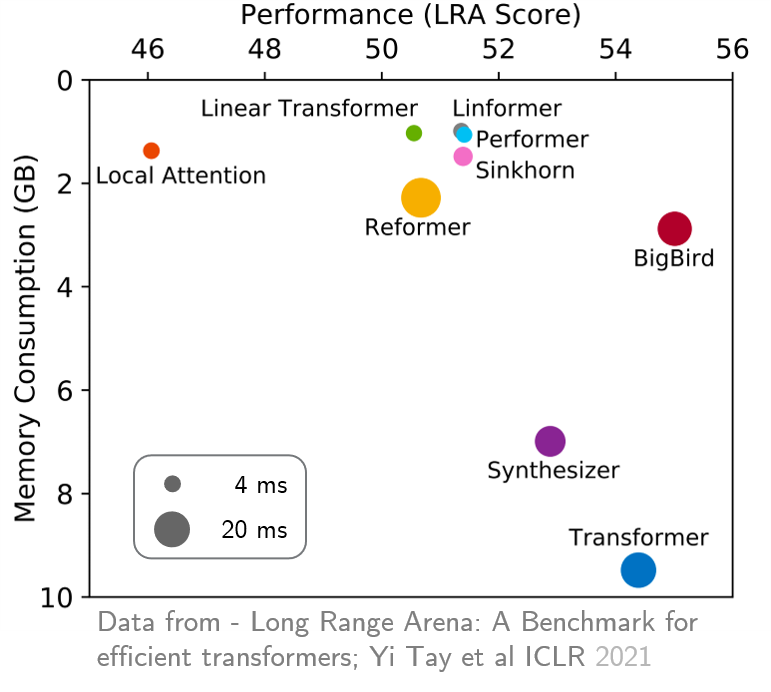
original_full ,因为使用稀疏的bigbird注意没有好处。 最近,远程竞技场提供了六个需要更长上下文的任务的基准,并执行了实验以基准所有现有的远程变压器。结果如下所示。与同行不同的是,Bigbird模型显然可以减少记忆消耗而无需牺牲性能。