bigbird
1.0.0
公式のGoogle製品ではありません。
Bigbirdは、BERTからはるかに長いシーケンスなどの変圧器ベースのモデルを拡張するまばらなアテナテンションベースの変圧器です。さらに、Bigbirdは、まばらなモデルが処理できる完全な変圧器の能力についての理論的理解と一緒になります。
より長いコンテキストを処理する能力の結果として、Bigbirdは、質問応答や要約などのさまざまなNLPタスクのパフォーマンスを大幅に向上させます。
詳細と比較は、プレゼンテーションにあります。
これが便利だと思う場合は、Neurips 2020の論文を引用してください。
@article{zaheer2020bigbird,
title={Big bird: Transformers for longer sequences},
author={Zaheer, Manzil and Guruganesh, Guru and Dubey, Kumar Avinava and Ainslie, Joshua and Alberti, Chris and Ontanon, Santiago and Pham, Philip and Ravula, Anirudh and Wang, Qifan and Yang, Li and others},
journal={Advances in Neural Information Processing Systems},
volume={33},
year={2020}
}
最も重要なディレクトリはcoreです。 coreには3つの主要なファイルがあります。
テキスト分類のための簡単な微調整デモンストレーションは、imdb.ipynbで提供されています
最初にプロジェクトを作成し、次のように割り当てを持つゾーンにインスタンスを作成してください
gcloud compute instances create
bigbird
--zone=europe-west4-a
--machine-type=n1-standard-16
--boot-disk-size=50GB
--image-project=ml-images
--image-family=tf-2-3-1
--maintenance-policy TERMINATE
--restart-on-failure
--scopes=cloud-platform
gcloud compute tpus create
bigbird
--zone=europe-west4-a
--accelerator-type=v3-32
--version=2.3.1
gcloud compute ssh --zone " europe-west4-a " " bigbird "
イラストには、インスタンス名bigbirdとZone europe-west4-aを使用しましたが、自由に変更してください。 Google Cloud TPUの作成の詳細については、オンラインドキュメントをご覧ください。
git clone https://github.com/google-research/bigbird.git
cd bigbird
pip3 install -e .Googleクラウドストレージバケットには、前処理された微調整されたチェックポイントを見つけることができます。
オプションで、 gsutil ASを使用してダウンロードできます
mkdir -p bigbird/ckpt
gsutil cp -r gs://bigbird-transformer/ bigbird/ckpt/ストレージバケットには次のものが含まれています。
bigbr_base )および大規模( bigbr_large )サイズの前提条件のBERTモデル。これは、Bert/Robertaのようなエンコーダーのみのモデルに対応しています。元のBertおよびRobertaの実装に続いて、それらは正常化後の変圧器であり、IEレイヤーの規範は注意層の後に発生しています。ただし、Rotheらに続いて、Bigbird/summarization/roberta_base.sh起動スクリプトに示されているように、エンコーダーとデコーダーのパラメーターを結合することにより、エンコーダーデコーダーファッションで部分的に使用できます。bigbp_large )の前処理されたPegasusエンコーダーデコーダートランス。再びペガサスの元の実装に続いて、それらは正常化前の変圧器です。それらは、個別のエンコーダーデコーダー重量の完全なセットを持っています。また、長いドキュメント要約データセットについては、各データセットのPegasusチェックポイント( model.ckpt-0 )を変換し、長いドキュメントで機能する微調整されたチェックポイント( model.ckpt-300000 )も提供しました。tf.SavedModel 。Bigbirdからすばやく始めるために、 classifier Directoryで分類実験コードを実行することから始めることができます。コードを実行するには、単純に実行されます
export GCP_PROJECT_NAME=bigbird-project # Replace by your project name
export GCP_EXP_BUCKET=gs://bigbird-transformer-training/ # Replace
sh -x bigbird/classifier/base_size.shたとえばBertモデルの代わりにエンコーダーを直接使用するには、次のコードを使用できます。
from bigbird . core import modeling
bigb_encoder = modeling . BertModel (...)Bertのエンコーダーを簡単に交換できます。
または、Bigbirdエンコーダーのレイヤーで遊んでみることもできます
from bigbird . core import encoder
only_layers = encoder . EncoderStack (...)すべてのフラグと構成はcore/flags.pyで説明されています。ここでは、重要な構成パラメーターのいくつかを説明します。
attention_typeは、使用する注意の種類を選択するために使用されます。 block_sparseに設定すると、Bigbirdの注意モジュールが実行されます。
flags . DEFINE_enum (
"attention_type" , "block_sparse" ,
[ "original_full" , "simulated_sparse" , "block_sparse" ],
"Selecting attention implementation. "
"'original_full': full attention from original bert. "
"'simulated_sparse': simulated sparse attention. "
"'block_sparse': blocked implementation of sparse attention." ) block_sizeブロックのサイズを定義するために使用されますが、 num_rand_blocksランダムブロックの数を設定するために使用されます。このコードは現在、3ブロックと2つのグローバルブロックのウィンドウサイズを使用しています。現在のコードは、静的なテンソルのみをサポートしています。
注意すべき重要な点:
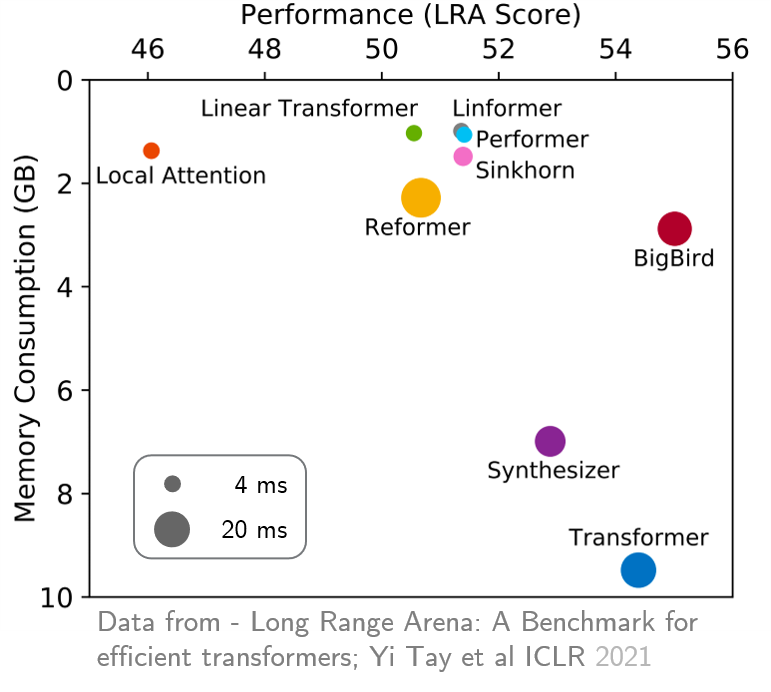
original_full使用することをお勧めします。 最近、長距離アリーナは、より長いコンテキストを必要とする6つのタスクのベンチマークを提供し、既存のすべての長距離変圧器をベンチマークするために実験を行いました。結果を以下に示します。 Bigbirdモデルは、そのカウンターパートとは異なり、パフォーマンスを犠牲にすることなくメモリの消費を明確に削減します。